网络模型
Kubernetes 的网络模型假定了所有 Pod 都在一个可以直接连通的扁平的网络空间中,这在GCE(Google Compute Engine)里面是现成的网络模型,Kubernetes 假定这个网络已经存在。而在私有云里搭建 Kubernetes 集群,就不能假定这个网络已经存在了。我们需要自己实现这个网络假设,将不同节点上的 Docker 容器之间的互相访问先打通,然后运行 Kubernetes.
网络模型原则
- 任意节点上的Pod可以在不借助NAT的情况下与任意节点上的任意Pod进行通信;
- 节点上的代理(诸如系统守护进程、kubelet等)可以在不借助NAT的情况下与该节点上的任意Pod进行通信;
- 处于一个节点的主机网络中的Pod可以在不借助NAT的情况下与任意节点上的任意Pod进行通信(当且仅当支持Pod运行在主机网络的平台上,比如Linux等);
- 不论在Pod内部还是外部,该Pod的IP地址和端口信息都是一致的。
在上述要求得到保证后,Kubernetes网络主要聚焦于两个任务—IP地址管理和路由,并致力于解决如下问题:
- 同一个Pod内多个容器之间如何通信
- 同一个Node节点中多个Pod之间如何通信
- 不同Node节点上的多个Pod之间如何通信
- Pod和Service之间如何通信
- Pod和集群外的实体如何通信
- Service和集群外的实体如何通信
CNI
Kubernetes刚开始仅关注和负责容器编排领域的相关事宜,网络管理并不是它最核心的工作。起初,Kubernetes通过开发Kubenet来实现网络管理功能以提供满足要求的集群网络。Kubenet是一个非常简单、基础的网络插件实现。但它本身并不支持任何跨节点之间的网络通信和网络策略等高级功能,且仅适用于Linux系统,所以Kubernetes试图找到一个更优秀的方案来替代Kubenet。为了解决这个问题,CoreOs公司和Docker各自推出了CNI(Container Network Interface)和CNM (Container Network Model)规范,CNI以其完善的规范和优雅的设计击败了CNM,并成为了Kubernetes首选的网络插件接口规范。
CNI的基本思想是在容器运行时环境中创建容器时,先创建好网络命名空间(netns),然后调用CNI插件为这个网络命名空间配置网络,之后再启动容器内的进程。CNI通过Json Schema定义了容器运行环境和网络插件之间的接口声明,描述当前容器网络的配置和规范,尝试通过一种普适的方式来实现容器网络的标准化 。它仅专注于在创建容器时分配网络资源(IP、网卡、网段等)和在容器被回收时如何删除网络资源两个方面的能力。CNI作为Kubernetes和底层网络之间的一个抽象存在,屏蔽了底层网络实现的细节、实现了Kubernetes和具体网络实现方案的解耦,同时也克服了Kubenet不能实现跨主机容器间的相互通信等不足和短板。
借助 CNI 标准,Kubernetes 可以实现容器网络问题的解决。通过插件化的方式来集成各种网络插件,实现集群内部网络相互通信,只要实现CNI标准中定义的核心接口操作ADD,将容器添加到网络;DEL从网络中删除一个容器;CHECK,检查容器的网络是否符合预期等)。CNI插件通常聚焦在容器到容器的网络通信。


CNI的接口并不是指 HTTP,gRPC 这种接口,CNI接口是指对可执行程序的调用(exec)可执行程序,Kubernetes 节点默认的 CNI 插件路径为/opt/cni/bin

CNI通过JSON格式的配置文件来描述网络配置,当需要设置容器网络时,由容器运行时负责执行CNI插件,并通过CNI插件的标准输入(stdin)来传递配置文件信息,通过标准输出(stdout)接收插件的执行结果。从网络插件功能可以分为五类:
Main: interface-creating
- bridge: 创建一个桥接网络,并将宿主机和容器加入到这个桥接网络中
- ipvlan: 在容器中加入一个ipvlan接口
- loopback: 设置环回接口的状态为up状态
- macvlan: 创建一个新的mac地址,并将所有到该地址的流量转发到容器
- ptp: 创建一个新的veth对
- vlan: 分配一个vlan设备
- host-device: 将宿主机现有的网络接口移到容器内。
IPAM: IP address allocation
- dhcp: 在宿主机上运行一个daemon进程并代表容器发起DHCP请求。
- host-local: 维护一个已分配IP的本地数据库
- static: 向容器分配一个静态的IPv4/IPv6地址,这个地址仅用于调试目的。
Meta: other plugins
- flannel: 根据flannel配置文件生成一个网络接口
- tuning: 调整一个已有网络接口的sysctl参数
- portmap: 一个基于iptables的端口映射插件,将宿主机地址空间的端口映射到容器中
- bandwidth: 通过流量控制工具tbf来实现带宽限制
- sbr: 为接口配置基于源IP地址的路由
- firewall: 一个借助iptables或者firewalld来添加规则来限制出入容器流量的防火墙插件。
Windos specific
win-bridge: 一个桥接插件,用于在 Windows 环境中将容器连接到宿主机网络,支持通过 NAT 实现容器与外部网络的通信。
win-overlay: 一个覆盖网络插件,支持在 Windows 环境下跨主机创建虚拟网络,允许容器通过 VXLAN 技术与其他节点上的容器进行通信。
容器网络插件

Pod启动网络流程

Pod 调度与启动流程
- Pod 被调度到容器集群的某个节点上
- Kubernetes 调度器根据调度算法选择一个合适的节点,将 Pod 分配到该节点。
- 将调度决策写入
kube-apiserver,更新 Pod 的NodeName字段。
- 节点的 kubelet 通过调用 CRI 插件来创建 Pod
- kubelet 获取 Pod 信息:
- kubelet
通过 watch 监听kube-apiserver`,检测到有新 Pod 调度到本节点。 - 拉取 Pod 定义,包括容器配置、资源需求等。
- 调用 CRI 插件:
- 使用 gRPC 接口与 CRI 插件(如 containerd)通信,发起 Pod 创建请求。
- CRI 插件创建 Pod 的 Sandbox 和网络命名空间
- CRI 插件调用容器运行时创建一个 Pause 容器(作为 Pod 的 Sandbox 容器)。
- 创建 Pod 的独立网络命名空间(NetNS)用于网络隔离。
- 生成一个唯一的 Sandbox ID 标识该 Pod 沙箱。
- CRI 插件通过网络命名空间和 Sandbox ID 调用 CNI 插件
- CRI 插件通过
RunPodSandboxAPI 调用 CNI 插件,将网络命名空间和 Sandbox ID 作为参数传递。 - 开始为 Pod 配置网络。
- CRI 插件通过
- CNI 配置 Pod 网络
- Flannel 为 Pod 分配一个 IP 地址,并设置节点间的网络隧道(如 VXLAN)。
- Bridge CNI 插件:在宿主机上创建一个虚拟网桥(如
cni0),并将 Pod 的虚拟网卡(veth pair)连接到网桥。 - 主机 IPAM CNI 插件:分配具体的 IP 地址,设置路由和 DNS 信息。
- 返回结果:CNI 插件返回成功状态,包含分配的 Pod IP 地址。
- 创建 Pause 容器,并将其添加到 Pod 的网络命名空间
- Pause 容器作为 Pod 的基础,持有 Pod 的网络命名空间和其他资源隔离设置。
- 所有应用容器共享 Pause 容器的网络命名空间。
- Pause 容器被启动,并加入网络命名空间。
- kubelet 调用 CRI 插件拉取应用容器镜像
kubelet通过 CRI 插件发起请求,确保应用容器所需的镜像可用。- 检查本地镜像缓存,如果不存在则拉取镜像。
- 容器运行时 containerd 拉取应用容器镜像
- 容器运行时(如 containerd)从镜像仓库(如 Docker Hub、Harbor)拉取应用容器镜像。
- 将镜像存储到本地镜像仓库。
- kubelet 调用 CRI 插件来响应应用容器
kubelet使用 CRI 插件,发起应用容器创建请求。- 配置应用容器的运行参数(启动命令、环境变量、资源限制等)。
- CRI 插件调用容器运行时 containerd 来启动和配置应用容器
- CRI 插件通过 containerd 启动应用容器。
- 配置应用容器的 Cgroups 和 Namespace:
- 加入 Pod 的网络命名空间(共享 Pause 容器的 NetNS)。
- 配置资源隔离(CPU、内存)。
- 应用容器被运行在 Pod 的沙箱环境中,完成整个流程。
总结
Scheduler:分配 Pod 到节点。kubelet:协调 CRI 和 CNI,完成 Pod 和容器的创建。CRI 插件:负责沙箱和容器的创建。CNI 插件:负责网络配置。容器运行时:负责容器镜像拉取和运行。
开源组件对比
| 提供商 | 网络模型 | 路由分发 | 网络策略 | 网格 | 外部数据存储 | 加密 | Ingress/Egress 策略 |
|---|---|---|---|---|---|---|---|
| Canal | 封装 (VXLAN) | 否 | 是 | 否 | K8s API | 是 | 是 |
| Flannel | 封装 (VXLAN) | 否 | 否 | 否 | K8s API | 是 | 否 |
| Calico | 封装 (VXLAN, IPIP) 或未封装 | 是 | 是 | 是 | Etcd 和 K8s API | 是 | 是 |
| Weave | 封装 | 是 | 是 | 是 | 无 | 是 | 是 |
| Cilium | 封装 (VXLAN) | 是 | 是 | 是 | Etcd 和 K8s API | 是 | 是 |
- 网络模型:封装或未封装。
- 路由分发:一种外部网关协议,用于在互联网上交换路由和可达性信息。BGP 可以帮助进行跨集群 pod 之间的网络。此功能对于未封装的 CNI 网络插件是必须的,并且通常由 BGP 完成。如果你想构建跨网段拆分的集群,路由分发是一个很好的功能
- 网络策略:Kubemetes 提供了强制执行规则的功能,这些规则决定了哪些 senvice 可以使用网络策略进行相互通信。这是从Kubernetes 1.7 起稳定的功能,可以与某些网络插件一起使用。
- 网格:允许在不同的 Kubernetes 集群间进行 service 之间的网络通信,
- 外部数据存储:具有此功能的 CN网络插件需要一个外部数据存储来存储数据
- 加密:允许加密和安全的网络控制和数据平面。
- Ingress/Egress 策略:允许你管理 Kubernetes 和非 Kubernetes 通信的路由控制
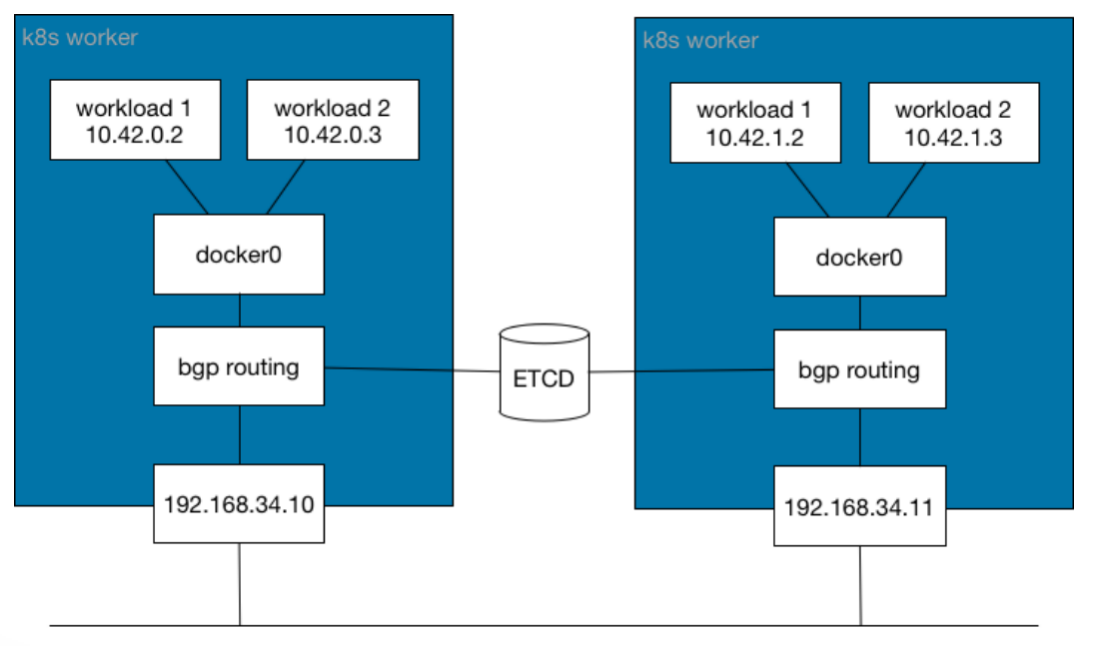
underlay network(非封装网络)
- 现实的物理基础层网络设备。
- underlay 是数据中心场景的基础物理设施,保证任何两个点路由可达,其中包含了传统的网络技术。
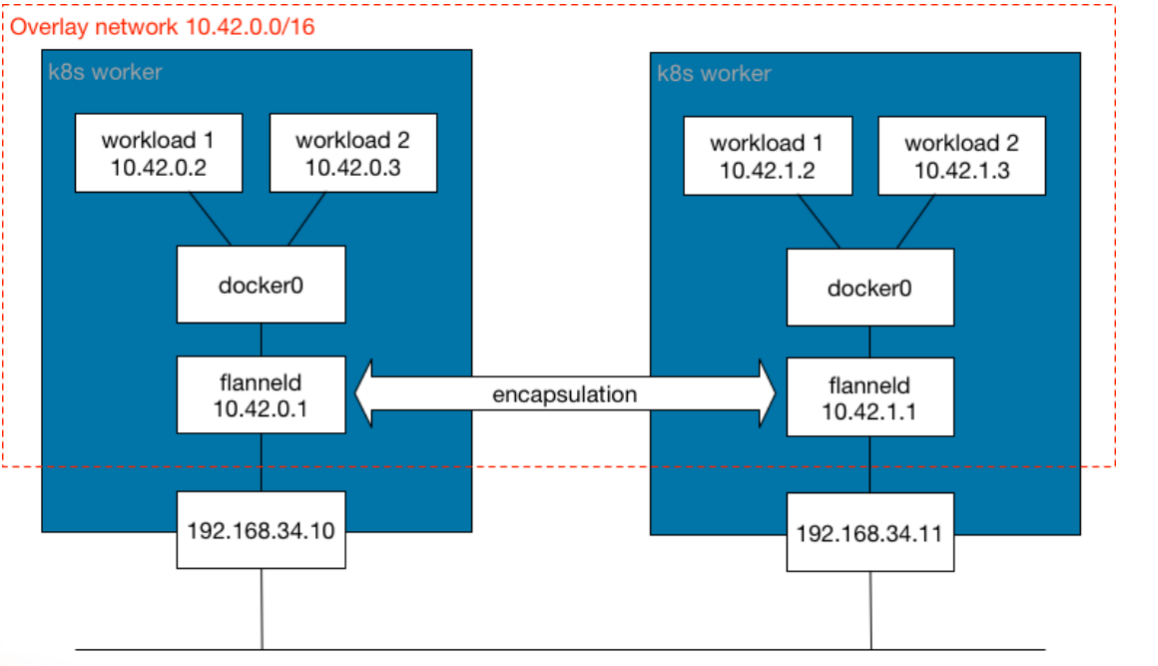
overlay network(封装网络)
- 一个基于物理网络之上构建的逻辑网络。
- overlay 是在网络技术领域指的一种网络架构上叠加的虚拟化技术模式。
- Overlay 网络技术多种多样,一般采用 TRILL、VxLAN、GRE、NVGRE 等隧道技术。
calico
Calico 创建和管理一个扁平的三层网络(不需要 overlay),每个容器会分配一个可路由的 IP。由于通信时不需要解包和封包,网络性能损耗小,易于排查,且易于水平扩展。
小规模部署时可以通过 BGP client 直接互联,大规模下可通过指定的 BGP Route Reflector 来完成,这样保证所有的数据流量都是通过 IP 路由的方式完成互联的。
Calico 基于 iptables 还提供了丰富而灵活的网络 Policy,保证通过各个节点上的 ACL 来提供 Workload 的多租户隔离、安全组以及其他可达性限制等功能。
calico 架构
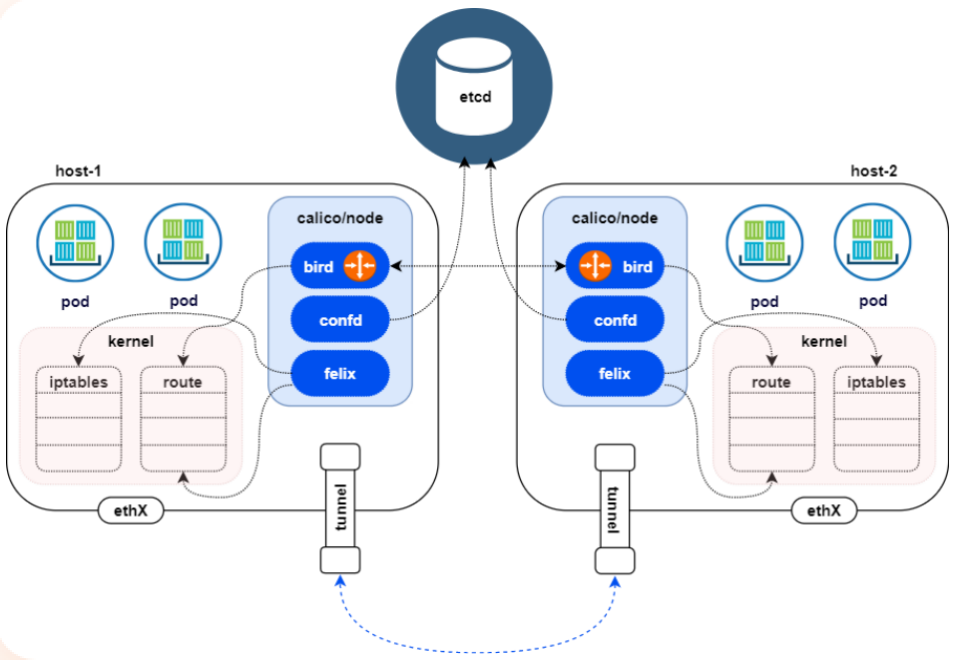
Felix
calico的核心组件,运行在每个节点上。主要的功能有接口管理、路由规则、ACL规则和状态报告,Felix会监听ECTD中心的存储,从它获取事件,比如说用户在这台机器上加了一个IP,或者是创建了一个容器等。用户创建pod后,Felix负责将其网卡、IP、MAC都设置好,然后在内核的路由表里面写一条,注明这个IP应该到这张网卡。同样如果用户制定了隔离策略,Felix同样会将该策略创建到ACL中,以实现隔离。
bird
Calico 为每一台 Host 部署一个 BGP Client,它的作用是将Felix的路由信息读入内核,并通过BGP协议在集群中分发。当Felix将路由插入到Linux内核FIB中时,BGP客户端将获取这些路由并将它们分发到部署中的其他节点。这可以确保在部署时有效地路由流量
confd
通过监听 etcd 以了解 BGP 配置和全局默认值的更改。Confd 根据 ETCD 中数据的更新,动态生成 BIRD 配置文件。当配置文件更改时,confd 触发 BIRD 重新加载新文件
什么是VXLAN
VXLAN,即 Virtual Extensible LAN(虚拟可扩展局域网),是Linux本身支持的一网种网络虚拟化技术。VXLAN 可以完全在内核态实现封装和解封装工作,从而通过“隧道”机制,构建出覆盖网络(Overlay Network)
基于三层的“二层”通信,层即 vxlan 包封装在 udp 数据包中, 要求 udp 在 k8s 节点间三层可达;二层即 vlan 封包的源 mac 地址和目的 mac 地址是自己的 vxlan 设备 mac 和对端 vxlan 设备 mac 实现通讯。



