简介
自己的博客是部署在腾讯云上的,除了部署博客和相关的学习软件之外,服务器并没有很好的利用起,于想使用grafanan对nginx的数据进行可视化展示以及监控服务器的基本情况。
监控服务器的相关配置
使用dokcer-file对grafana 进行配置,使用prometheus和grafana对服务器进行监控,同时将plugins目录外挂出来展示需要piechart-panel,和orldmap-panel
version: '3'
services:
prometheus:
image: prom/prometheus
container_name: prometheus
ports:
- "9090:9090"
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
- ./prometheus.rules.yml:/etc/prometheus/prometheus.rules.yml
deploy:
resources:
limits:
memory: 150M
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--web.enable-lifecycle'
- '--web.enable-admin-api'
- '--storage.tsdb.path=/prometheus'
networks:
- hph_net
node-exporter:
image: prom/node-exporter:v1.2.2
container_name: node-exporter
ports:
- "9100:9100"
restart: always
deploy:
resources:
limits:
memory: 150M
depends_on:
- prometheus
networks:
- hph_net
grafana:
image: grafana/grafana-enterprise
container_name: grafana
ports:
- "3000:3000"
environment:
- GF_SECURITY_ADMIN_PASSWORD=admin
- GF_DATABASE_TYPE=mysql
- GF_DATABASE_HOST=192.144.232.47
- GF_DATABASE_NAME=grafana
- GF_DATABASE_USER=grafana
- GF_DATABASE_PASSWORD=Grafana@2024!
volumes:
- ./grafana/provisioning/:/etc/grafana/provisioning/
- ./grafana/plugins/:/var/lib/grafana/plugins/
- ./grafana/conf/defaults.ini:/usr/share/grafana/conf/defaults.ini
deploy:
resources:
limits:
memory: 150M
depends_on:
- node-exporter
networks:
- hph_net
networks:
hph_net:
external: trueprometheus.yml
prometheus的配置如下主要是为了配置采集node的指标对服务器的指标进行抓取同时使用对应的规则对数据进行处理。
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "prometheus.rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
static_configs:
- targets: ["prometheus:9090"]
- job_name: "node_metrics"
static_configs:
- targets: ["node-exporter:9100"]prometheus.rules.yml
Prometheus采集数据的规则配置:
groups: #新rule文件需要加这行开头,追加旧的rule文件则不需要。
- name: node_usage_record_rules
interval: 1m
rules:
- record: cpu:usage:rate1m
expr: (1 - avg(irate(node_cpu_seconds_total{mode="idle"}[3m])) by (job,instance)) * 100
- record: mem:usage:rate1m
expr: (1 - node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes) * 100使用Nginx反向代理
需要修改对应的 grafana/conf/default.ini在root_url后边添加路径/grafana(该路径可自定义,和nginx配置中保持一致即可)
# 后缀与nginx代理后缀保持一致
root_url = %(protocol)s://%(domain)s:%(http_port)s/grafana
# 允许跨域
allowed_origins = *
# 允许iframe嵌入
allow_embedding = true
配置nginx
location /grafana {
root html;
index index.html index.htm;
add_header Access-Control-Allow-Origin '*';
add_header Access-Control-Allow-Methods '*';
add_header Access-Control-Allow-Credentials true;
proxy_set_header 'Authorization' 'Bearer glsa_e0nhCdjBTCn8cW6OiSLcZTuhhOFUZQzC_4e5f6177';
proxy_pass http://192.144.232.47:3000;
proxy_set_header Host $host;
if ($request_method = OPTIONS) {
return 200;
}
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header REMOTE-HOST $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}其中 proxy_set_header 由下面的操作获得
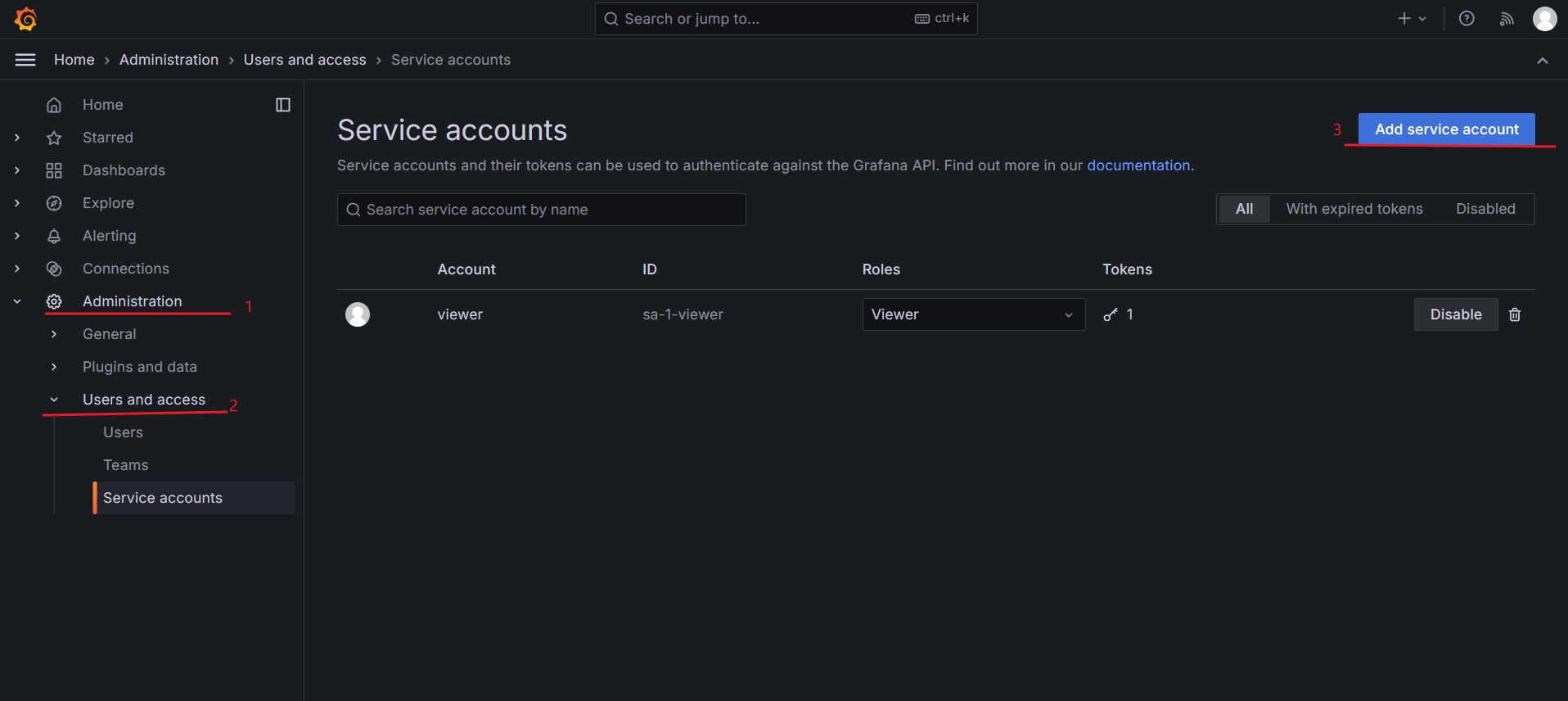
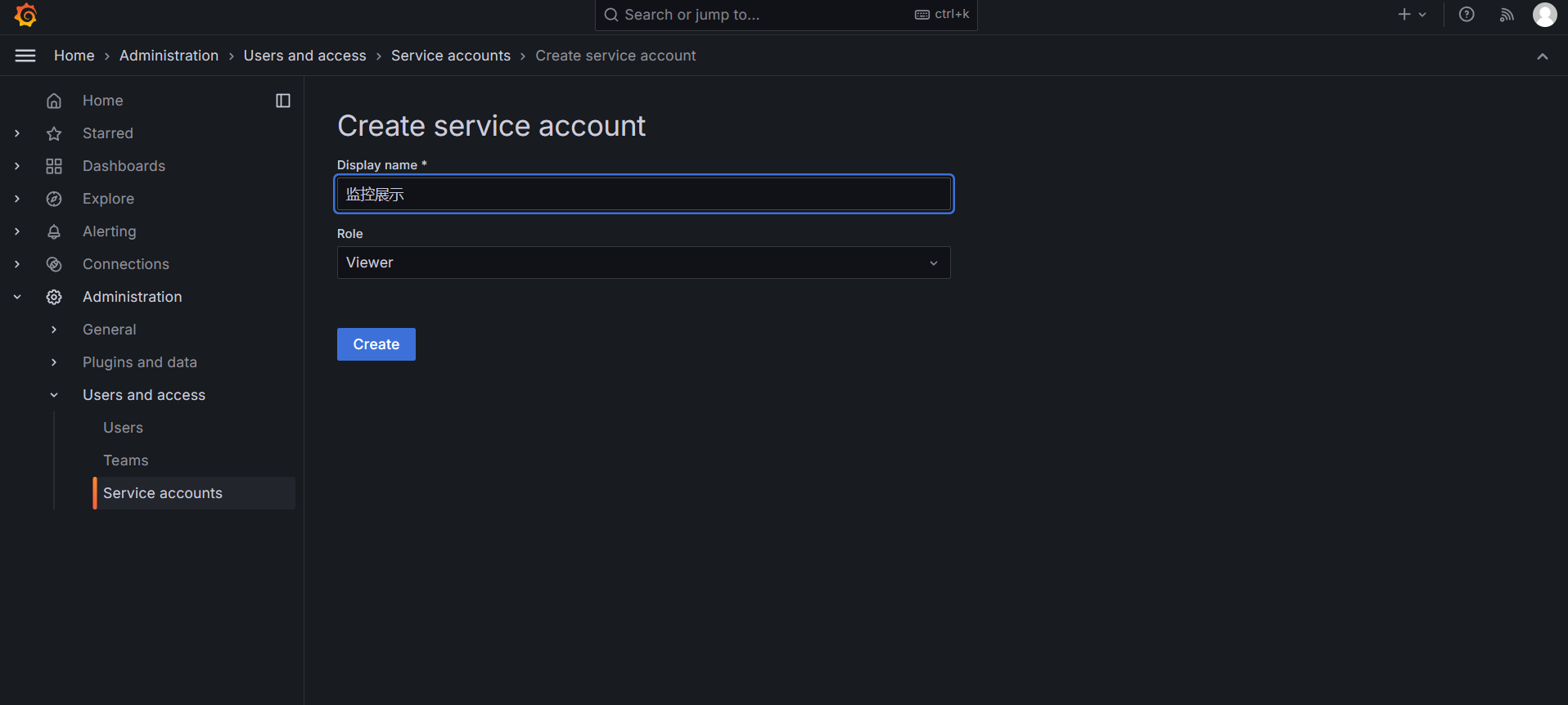
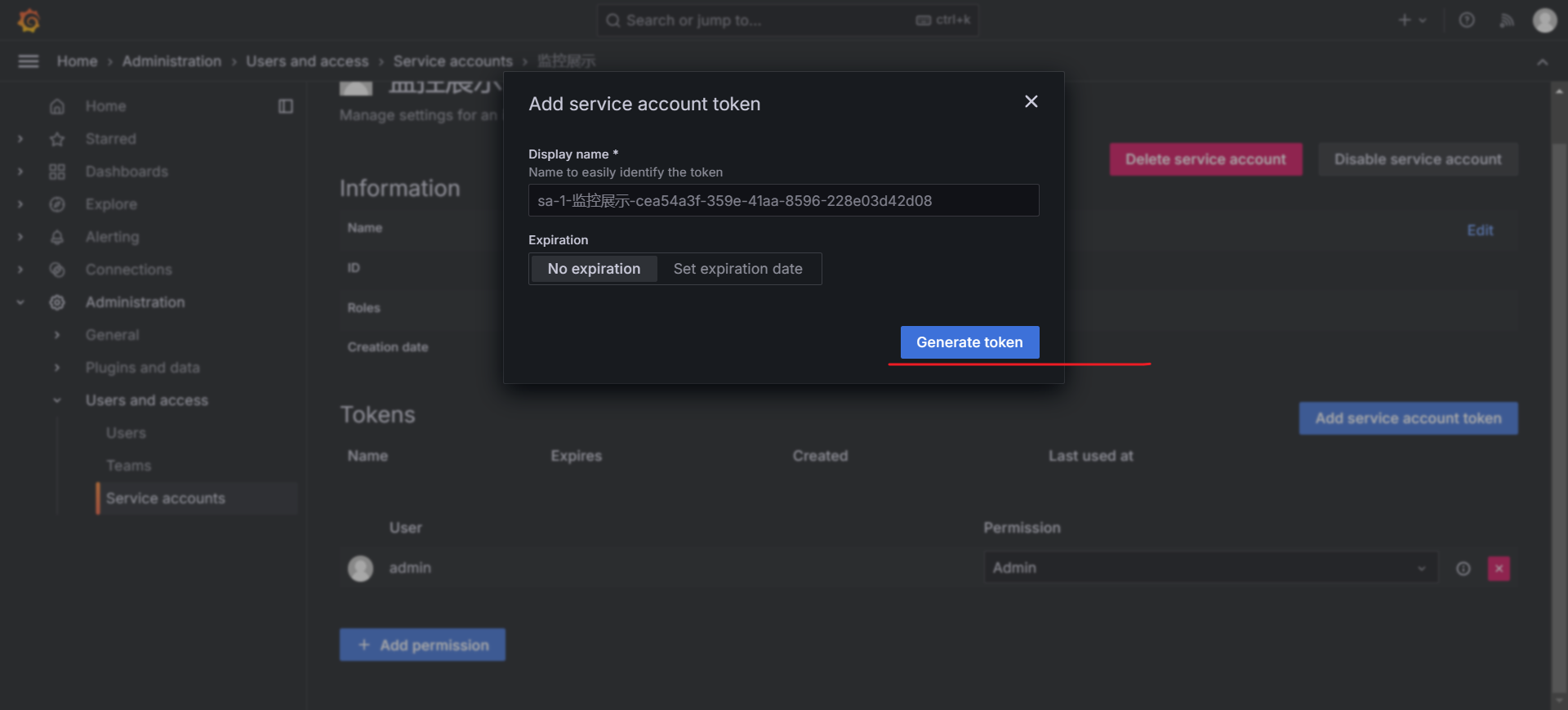
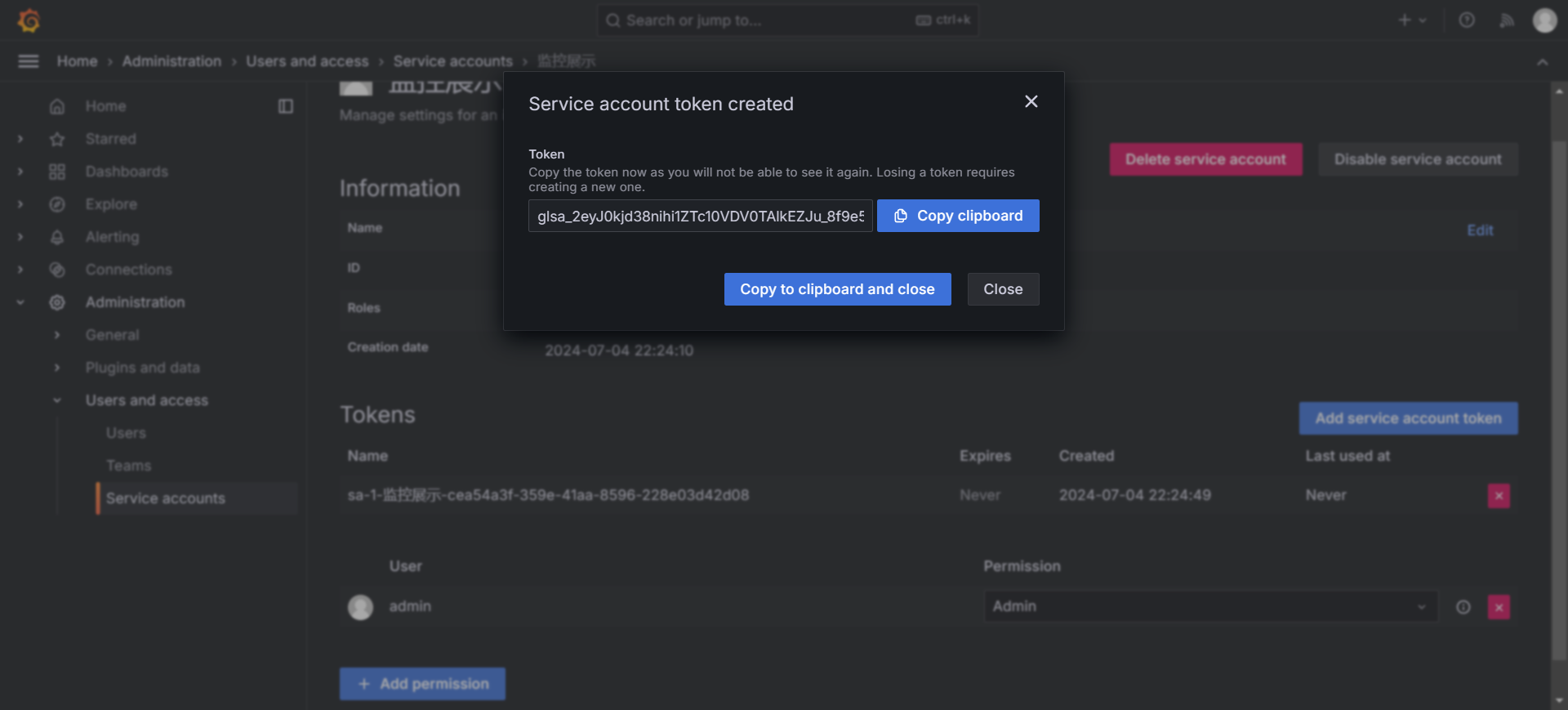
在grafana中引入id为 16098,即可有下面的样式最近7天P99的指标需要等1个小时左右会出来。
## nginx 日志配置json 格式化在实现日志分析之前,主要还需要把对应的日志数据JSON化,下面是Nginx 日志对应的配置
log_format json_analytics escape=json
'{"@timestamp":"$time_iso8601",'
'"host":"$hostname",'
'"server_ip":"$server_addr",'
'"client_ip":"$remote_addr",'
'"xff":"$http_x_forwarded_for",'
'"domain":"$host",'
'"url":"$uri",'
'"referer":"$http_referer",'
'"args":"$args",'
'"upstreamtime":"$upstream_response_time",'
'"responsetime":"$request_time",'
'"request_method":"$request_method",'
'"status":"$status",'
'"size":"$body_bytes_sent",'
'"request_body":"$request_body",'
'"request_length":"$request_length",'
'"protocol":"$server_protocol",'
'"upstreamhost":"$upstream_addr",'
'"file_dir":"$request_filename",'
'"http_user_agent":"$http_user_agent"'
'}';
access_log /var/log/json_access.log json_analytics;点击页面,日志格式如下图所示

这里我们的参考方案是基于使用filebeat将数据采集到redis中,使用redis缓存数据,下游使用logstash 使用GeoLite2-City.mmdb 添加对应的ip工具的经纬度,并将加工好的数据写入到elasticsearch中。所需要配置的组件配置如下
version: '3'
services:
elasticsearch:
container_name: elasticsearch
image: "docker.elastic.co/elasticsearch/elasticsearch:7.11.0"
environment:
- discovery.type=single-node
- indices.query.bool.max_clause_count=8192 # Adjust as needed
- search.max_buckets=100000 # Adjust based on your requirements
- ES_JAVA_OPTS=-Xms512m -Xmx512m
volumes:
- /etc/localtime:/etc/localtime
deploy:
resources:
limits:
memory: 512M
networks:
- hph_net
logstash:
container_name: logstash
depends_on:
- elasticsearch
image: "docker.elastic.co/logstash/logstash:7.11.0"
volumes:
- ./GeoLite2-City.mmdb:/usr/share/logstash/GeoLite2-City.mmdb
- ./logstash.conf:/usr/share/logstash/pipeline/logstash.conf
links:
- elasticsearch
deploy:
resources:
limits:
memory: 256M
networks:
- hph_net
filebeat:
container_name: filebeat
depends_on:
- elasticsearch
- logstash
image: "docker.elastic.co/beats/filebeat:7.11.0"
volumes:
- ./filebeat.yml:/usr/share/filebeat/filebeat.yml:ro
- /var/log/json_access.log:/var/log/json_access.log:ro
user: root
environment:
- strict.perms=false
links:
- logstash
deploy:
resources:
limits:
memory: 128M
networks:
- hph_net
redis:
container_name: redis
image: "redis:5"
environment:
- BIND=0.0.0.0
deploy:
resources:
limits:
memory: 128M
networks:
- hph_net
networks:
hph_net:
external: truefilebeat.yml
使用filebeat将数据采集和清洗,写入到redis中。
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/json_access.log
tags: ["nginx_logs"]
json.keys_under_root: true
json.overwrite_keys: true
json.add_error_key: true
fields_under_root: true
fields:
logs_type: "nginx_logs"
processors:
- drop_fields:
fields: ["ecs","agent","host","cloud","@version"]
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 1
output.redis:
hosts: ["redis:6379"]
key: "bole-nginx_logs"
db: 0
timeout: 5
keys:
- key: "bole-nginx_logs"
when.contains:
logs_type: "nginx_logs"
processors:
- add_host_metadata: ~
- add_cloud_metadata: ~logstash.conf
这Logstash配置文件用于处理两种不同类型的日志数据。对于nginx_logs类型,它从Redis的bole-nginx_logs列表中获取数据,应用GeoIP过滤器以提取客户端IP的地理信息,调整字段类型并删除不必要的字段,然后使用User Agent过滤器从http_user_agent字段中提取客户端信息。对于tomcat_logs类型,使用Grok过滤器解析日志内容,使用Date过滤器将时间字段解析为日期,并删除不必要的字段。最终,处理后的nginx_logs数据通过Elasticsearch输出插件发送到Elasticsearch进行索引,使用每天一个索引的模式(logstash-nginx-年月日)。
### logstash
input {
# bole-nginx
redis {
data_type =>"list"
key =>"bole-nginx_logs"
host =>"redis"
port => 6379
db => 0
type => nginx_logs
}
}
filter {
if [type] in "nginx_logs" {
geoip {
#multiLang => "zh-CN"
target => "geoip"
source => "client_ip"
database => "/usr/share/logstash/GeoLite2-City.mmdb"
add_field => [ "[geoip][coordinates]", "%{[geoip][longitude]}" ]
add_field => [ "[geoip][coordinates]", "%{[geoip][latitude]}" ]
# 去掉显示 geoip 显示的多余信息
remove_field => ["[geoip][latitude]", "[geoip][longitude]", "[geoip][country_code]", "[geoip][country_code2]", "[geoip][country_code3]", "[geoip][timezone]", "[geoip][continent_code]", "[geoip][region_code]"]
}
mutate {
convert => [ "size", "integer" ]
convert => [ "status", "integer" ]
convert => [ "responsetime", "float" ]
convert => [ "upstreamtime", "float" ]
convert => [ "[geoip][coordinates]", "float" ]
# 过滤 filebeat 没用的字段,这里过滤的字段要考虑好输出到es的,否则过滤了就没法做判断
remove_field => [ "ecs","agent","host","cloud","@version","input","logs_type" ]
}
# 根据http_user_agent来自动处理区分用户客户端系统与版本
useragent {
source => "http_user_agent"
target => "ua"
# 过滤useragent没用的字段
remove_field => [ "[ua][minor]","[ua][major]","[ua][build]","[ua][patch]","[ua][os_minor]","[ua][os_major]" ]
}
}
if [type] in "tomcat_logs" {
grok {
match => { "message" => "%{TIMESTAMP_ISO8601:access_time}\s+\[(?<level>[\s\S]*)\]\s+\[%{DATA:exception_info}\](?<content>[\s\S]*)" }
}
date {
match => [ "access_time","MMM d HH:mm:ss", "MMM dd HH:mm:ss", "ISO8601"]
}
mutate {
# 过滤 filebeat 没用的字段,这里过滤的字段要考虑好输出到es的,否则过滤了就没法做判断
remove_field => [ "ecs","agent","host","cloud","@version","message","input" ]
}
}
}
output {
# 收集服务器 nginx 日志
if [type] in "nginx_logs" {
elasticsearch {
hosts => "elasticsearch"
user => "elastic"
index => "logstash-nginx-%{+YYYY.MM.dd}"
}
}
}ELF环境
需要使用到Redis、Elasticsearch 、Logstash 、Filebeat、下面是启动的对应docker-compose
version: '3'
services:
elasticsearch:
container_name: elasticsearch
image: "docker.elastic.co/elasticsearch/elasticsearch:7.11.0"
environment:
- discovery.type=single-node
- indices.query.bool.max_clause_count=8192 # Adjust as needed
- search.max_buckets=100000 # Adjust based on your requirements
- ES_JAVA_OPTS=-Xms512m -Xmx512m
volumes:
- /etc/localtime:/etc/localtime
deploy:
resources:
limits:
memory: 512M
networks:
- hph_net
logstash:
container_name: logstash
depends_on:
- elasticsearch
image: "docker.elastic.co/logstash/logstash:7.11.0"
volumes:
- ./GeoLite2-City.mmdb:/usr/share/logstash/GeoLite2-City.mmdb
- ./logstash.conf:/usr/share/logstash/pipeline/logstash.conf
links:
- elasticsearch
deploy:
resources:
limits:
memory: 256M
networks:
- hph_net
filebeat:
container_name: filebeat
depends_on:
- elasticsearch
- logstash
image: "docker.elastic.co/beats/filebeat:7.11.0"
volumes:
- ./filebeat.yml:/usr/share/filebeat/filebeat.yml:ro
- /var/log/json_access.log:/var/log/json_access.log:ro
user: root
environment:
- strict.perms=false
links:
- logstash
deploy:
resources:
limits:
memory: 128M
networks:
- hph_net
redis:
container_name: redis
image: "redis:5"
environment:
- BIND=0.0.0.0
deploy:
resources:
limits:
memory: 128M
networks:
- hph_net
networks:
hph_net:
external: true添加es的数据源

在dashboard 中倒入 11190的图表

需要安装grafana-worldmap-panel和grafana-piechart-panel
grafana-cli plugins install grafana-worldmap-panel
grafana-cli plugins install grafana-piechart-panel界面访问地图加载过慢

实际请求的地址为
https://cartodb-basemaps-{s}.global.ssl.fastly.net/light_all/{z}/{x}/{y}.png
https://cartodb-basemaps-{s}.global.ssl.fastly.net/dark_all/{z}/{x}/{y}.png无代理情况下加载缓慢 最新版本需要修改
修改源码中的 url 为

http://{s}.basemaps.cartocdn.com/light_all/{z}/{x}/{y}.png
http://{s}.basemaps.cartocdn.com/dark_all/{z}/{x}/{y}.png打完包后将dist目录拷贝到grafana中的plugins目录中的grafana-worldmap-panel
在defaults.ini 添加
allow_loading_unsigned_plugins = grafana-worldmap-panel最终效果如图所示



