公司业务需要需要调研hudi相关数据湖开源组件,下面简单记录下对应的踩坑记录
基础环境准备
| 组件 | 版本 |
|---|---|
| Flink | 1.17.0 |
| Hudi | 0.14.0 |
| Hive | 2.3.1 |
| CDH | 6.3.2 |
| Kafka | 2.2.1 |
| Spark | 3.2.1 |
添加 cdh 对应的pom依赖
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos</url>
</repository>修改Hadoop版本为3.0.0
运行编译命令
mvn clean install -DskipTests -DskipITs -Dcheckstyle.skip=true -Drat.skip=true -Dhadoop.version=3.0.0 -Pflink-bundle-shade-hive2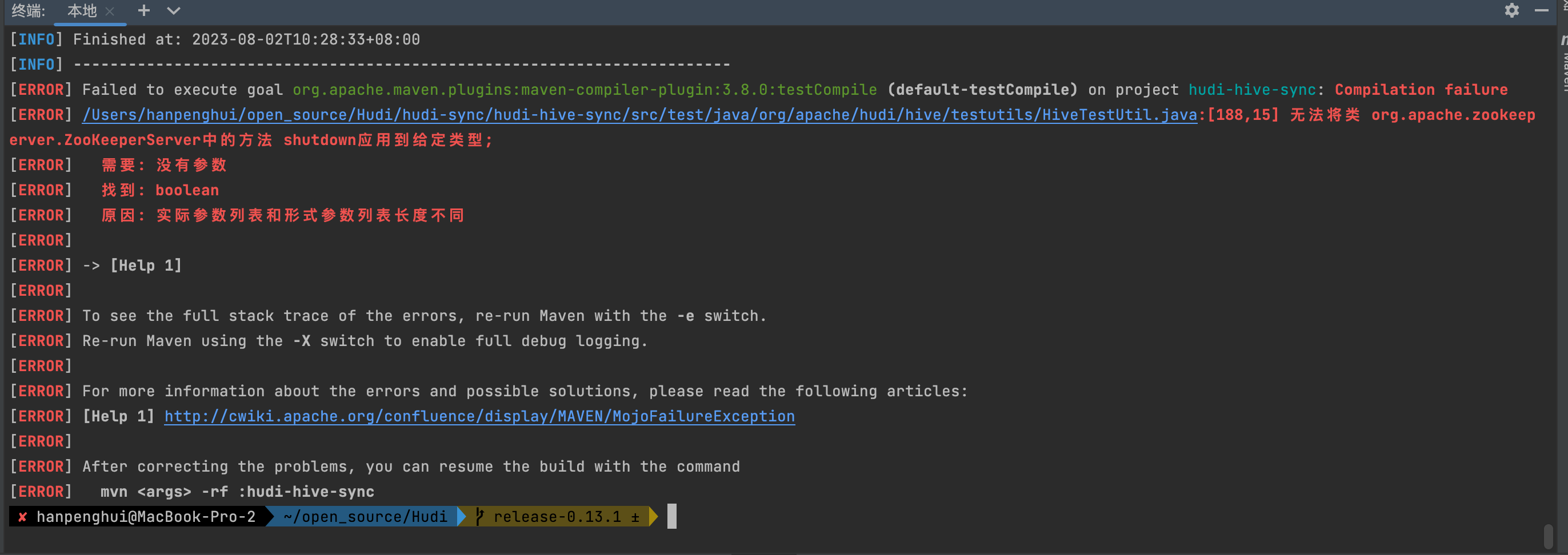
修改对应的代码为
zkServer.shutdown();编译master分支成功
安装flink1.17.1 stanlone模式
需要添加对应的jar包依赖
wget https://repository.cloudera.com/artifactory/cloudera-repos/org/apache/flink/flink-shaded-hadoop-3-uber/3.1.1.7.2.9.0-173-9.0/flink-shaded-hadoop-3-uber-3.1.1.7.2.9.0-173-9.0.jar
rz hudi-flink1.17-bundle-0.14.0-SNAPSHOT.jar启动sql-client 添加下面的作业
CREATE TABLE source_orders (
id bigint,
order_number BIGINT,
price DECIMAL(5,2),
buyer string,
order_time TIMESTAMP_LTZ(3)
) WITH (
'connector' = 'datagen',
'rows-per-second'= '1'
);
set execution.checkpointing.interval=1000;
set state.checkpoints.dir=file:///tmp/checkpoints
set execution.checkpointing.externalized-checkpoint-retention=RETAIN_ON_CANCELLATION;
CREATE TABLE hudi_orders (
id bigint,
order_number BIGINT,
price DECIMAL(5,2),
buyer string,
order_time TIMESTAMP_LTZ(3)
)
WITH (
'connector' = 'hudi'
, 'path' = 'hdfs://node0/tmp/hudi/hudi_orders'
, 'hoodie.datasource.write.recordkey.field' = 'id' -- 主键
, 'write.precombine.field' = 'order_time' -- 相同的键值时,取此字段最大值,默认ts字段
, 'write.tasks' = '1'
, 'compaction.tasks' = '1'
, 'write.rate.limit' = '2000' -- 限制每秒多少条
, 'table.type' = 'MERGE_ON_READ' -- 默认COPY_ON_WRITE
, 'compaction.async.enabled' = 'true' -- 在线压缩
, 'compaction.trigger.strategy' = 'num_commits' -- 按次数压缩
, 'compaction.delta_commits' = '1' -- 默认为5
, 'hive_sync.enable' = 'true' -- 启用hive同步
, 'hive_sync.mode' = 'hms' -- 启用hive hms同步,默认jdbc
, 'hive_sync.metastore.uris' = 'thrift://node0:9083' -- required, metastore的端口
, 'hive_sync.jdbc_url' = 'jdbc:hive2://node0:10000' -- required, hiveServer地址
, 'hive_sync.table' = 'hudi_table' -- required, hive 新建的表名
, 'hive_sync.db' = 'hudi' -- required, hive 新建的数据库名
, 'hive_sync.username' = 'hdfs' -- required, HMS 用户名
, 'hive_sync.password' = '' -- required, HMS Password
, 'hive_sync.skip_ro_suffix' = 'true' -- 去除ro后缀
);
insert into hudi_orders select * from source_orders;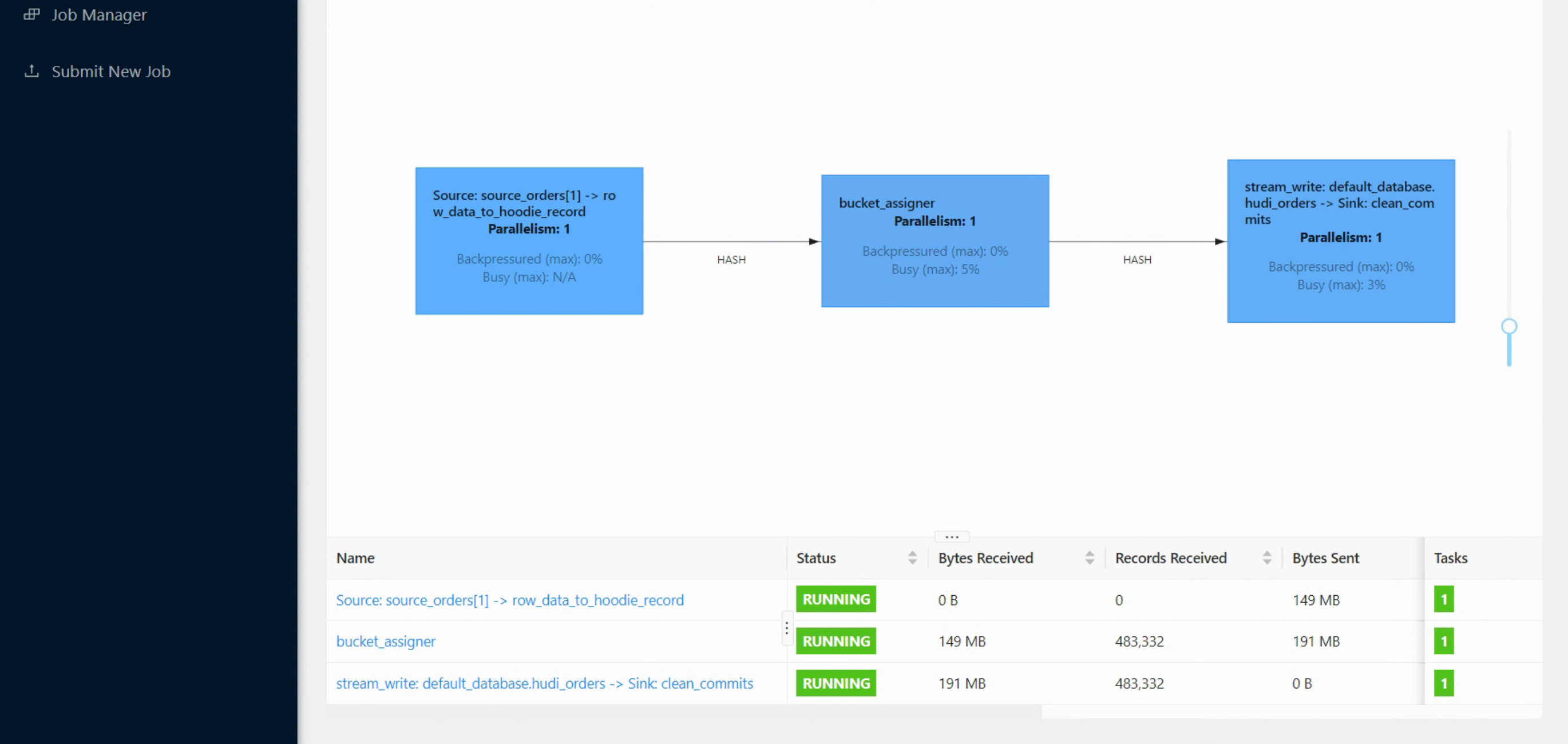
页面上已经出现任务了,但是在查询hive 的时候数据和表结构还是没有同步过去,需要进行下面的操作。
1.将 下面的包需要放到flink 的lib包下
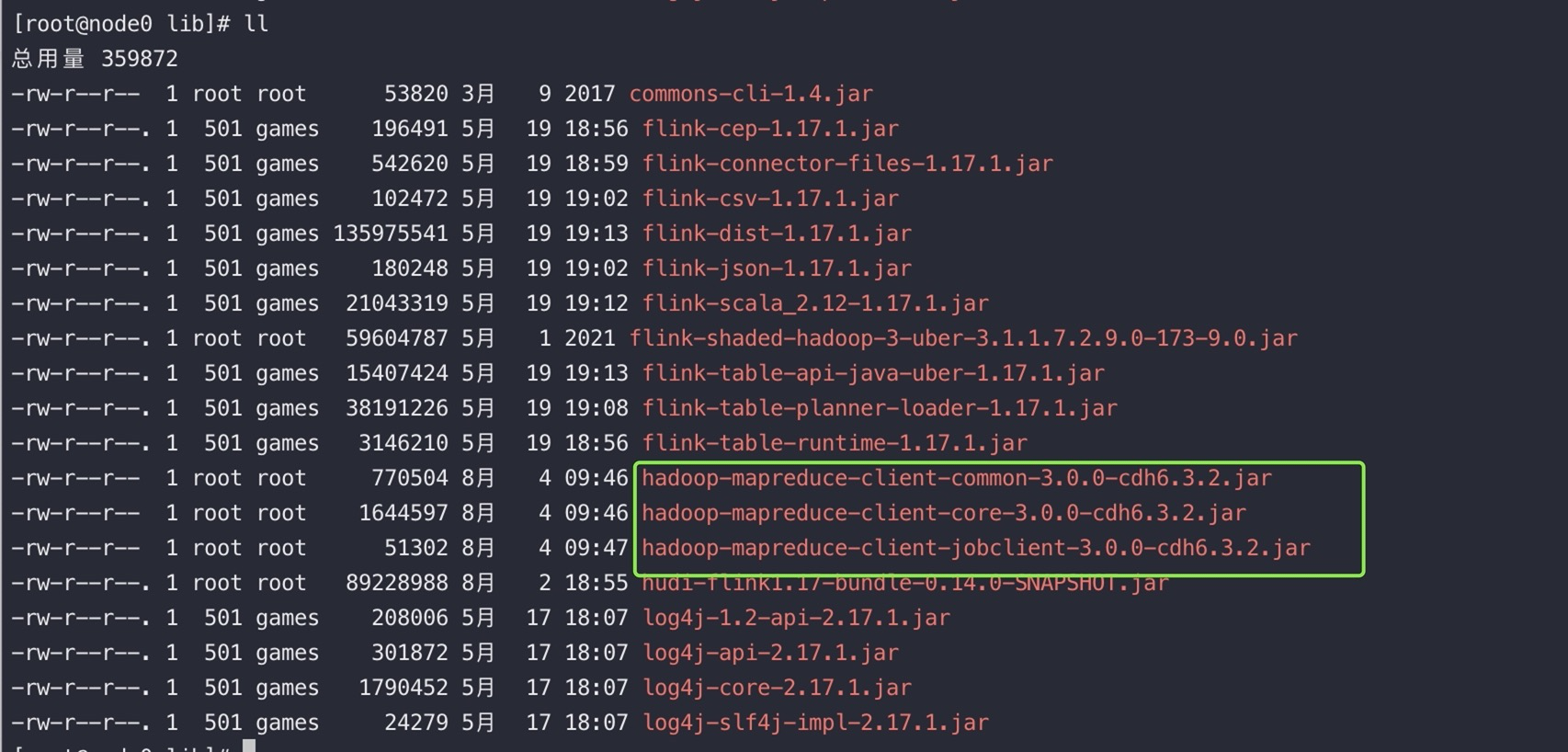
2.安装 YARN MapReduce 框架 JAR
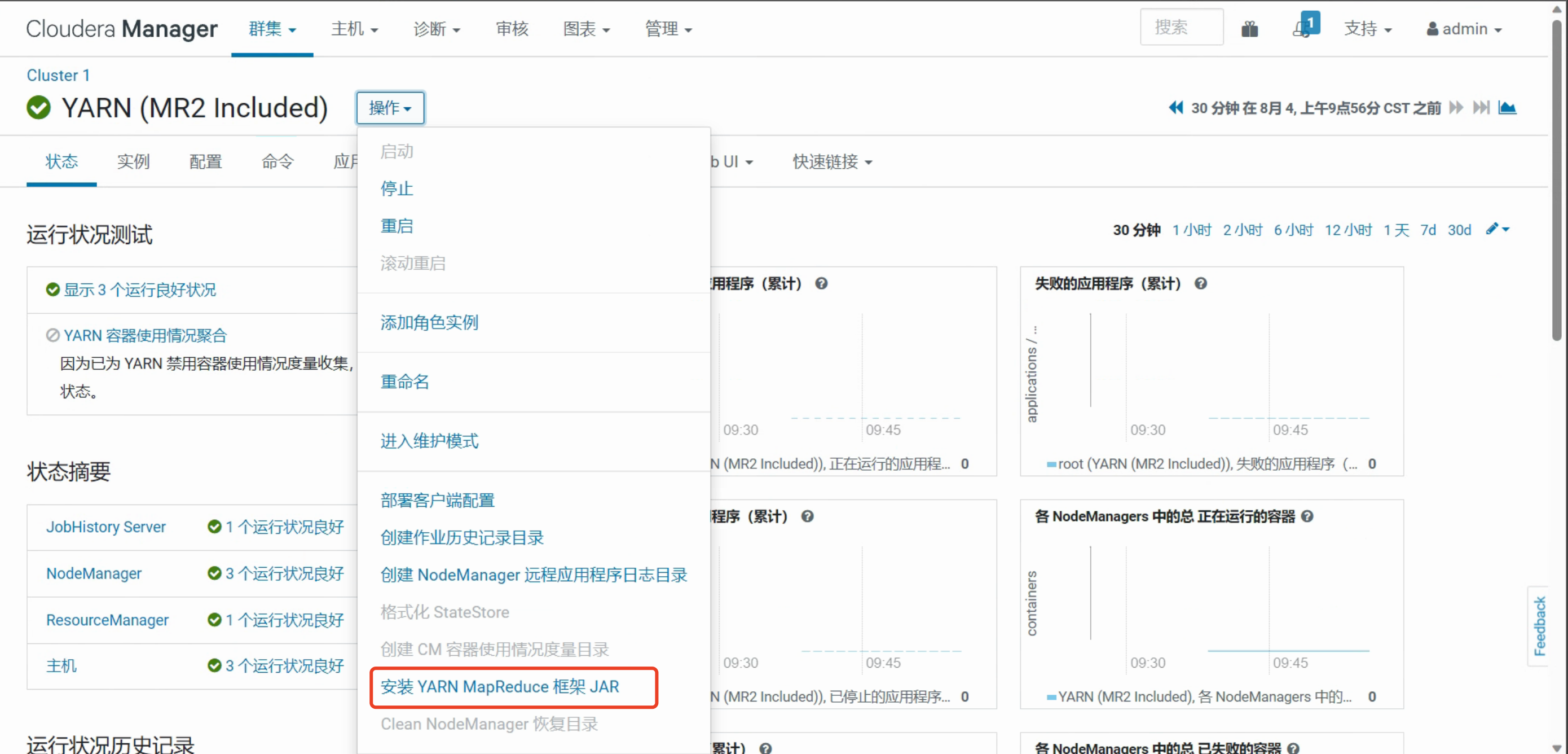
3.配置Hive的辅助jar包


对应的jar包如图所示
4.由于CDH-6.3.2对应的hive版本为 hive 2.1.1,修改hive依赖需要改的源码比较多,印次我们这边需要将hive版本从2.1.1 升级到2.3.1
解压对应版本的hive tar包
tar -zxvf apache-hive-2.3.1-bin.tar.gz
cp -r /opt/soft/apache-hive-2.3.1-bin/lib/ /opt/cloudera/parcels/CDH/lib/hive/lib231
cd /opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/hive/bin/
vim hive 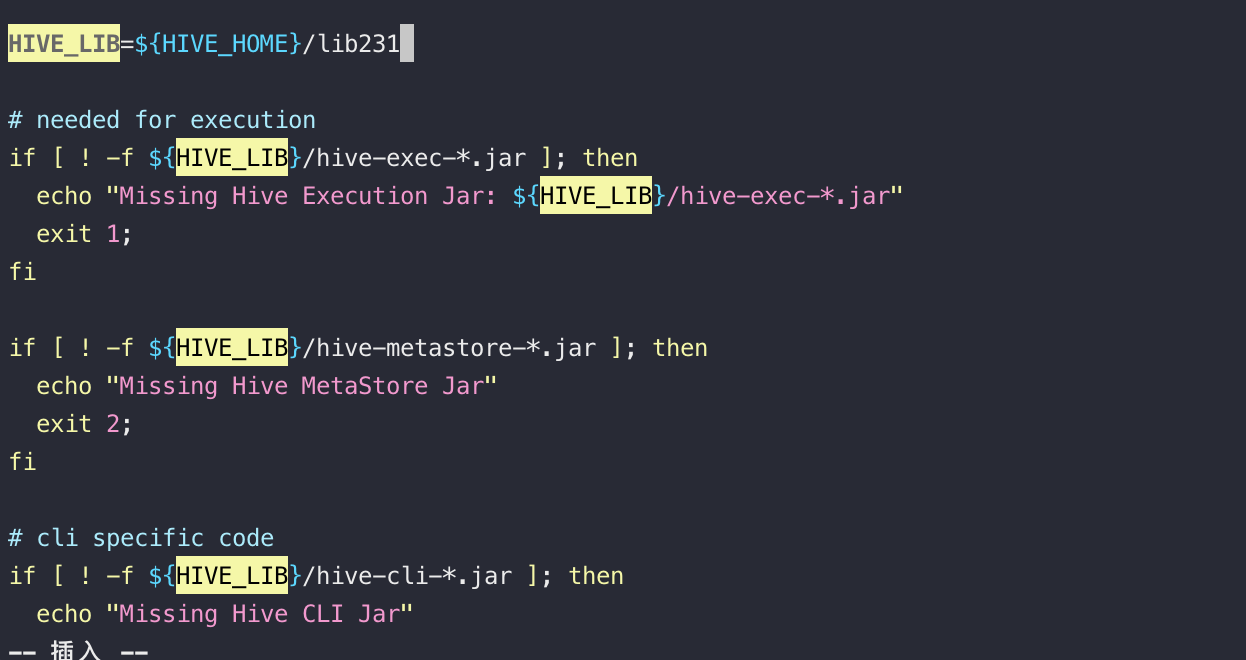
修改为上图所示
备份元数据
mysqldump -u root -p metastore > /home/hive_meatastore.sql升级对应的hive,逐步升级
source /opt/soft/apache-hive-2.3.1-bin/scripts/metastore/upgrade/mysql/upgrade-2.1.0-to-2.2.0.mysql.sql;
source /opt/soft/apache-hive-2.3.1-bin/scripts/metastore/upgrade/mysql/upgrade-2.2.0-to-2.3.0.mysql.sql;


