数据仓库
数据仓库是一个用于存储、分析、报告的数据系统,目的是构建面向分析的集成化数据环境,分析结果为企业提供决策支持。数据仓库本身不生产数据,也不消费数据。而是按照一定的方法论,将企业的业务需求划分为不同的层次,根据分层思想理论上可以分为三个层:操作型数据层(ODS)、数据仓库层(DW)和数据应用层(DA)。
数据湖
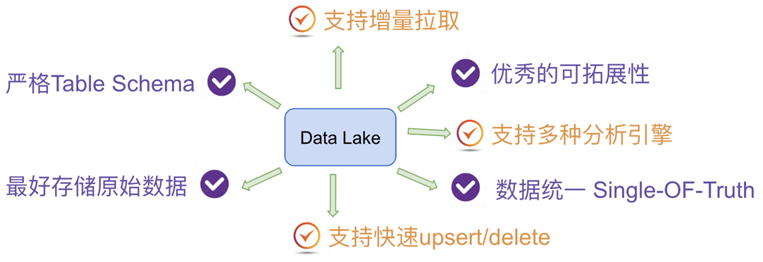
数据湖是一个以原始格式(通常是对象块或文件)存储数据的系统或存储库,通常是所有企业数据的单一存储。数据湖可以包括来自关系数据库的结构化数据(行和列)、半结构化数据(CSV、日志、XML、JSON)、非结构化数据(电子邮件、文档、pdf)和二进制数据(图像、音频、视频)。
数据湖越来越多的用于描述任何的大型数据池,数据都是以原始数据方式存储,知道需要查询应用数据的时候才会开始分析数据需求和应用架构。原始数据是指尙未针对特定目的处理过的数据。数据科学家可在需要时用比较先进的分析工具或预测建模法访问原始数据。
通过数据湖,用户能够以自己的方式访问和探索数据,无需将数据移入其他系统。不同于定期从其他平台或数据库提取分析报告,数据湖的分析和报告通常可以临时获取。但是,用户可在必要时通过模式和自动化复制报告。
你需要监管和持续维护数据湖,才能确保数据时刻可用和可访问。如果维护不当,您的数据就可能会沦为一堆垃圾,无法访问、难以操作、价格高昂而且毫无用处。用户无法访问的数据湖,就成了”数据沼泽”。
区别
| 特性 | 数据仓库 | 数据湖 |
|---|---|---|
| 数据 | 来自于事物系统、业务系统相关应用程序 | 来自Iot、网站、移动式应用程序、社交媒体和企业应用程序的非关系和关系数据库 |
| Schema | 设计在数据仓库事实之前(写入型Schema) | 写入在分析时(读取型Schema) |
| 性价比 | 更快的查询,冗余存储,存储成本高 | 更快的查询,更低的存储成本 |
| 数据质量 | 重要的事实依据,可以高度监管数据 | 管控较难 |
| 用户 | 业务分析师 | 数据科学家,数据开发人员,业务分析师 |
| 分析 | 批处理、BI和可视化 | 机器学习、预测分析、数据发现和分析 |
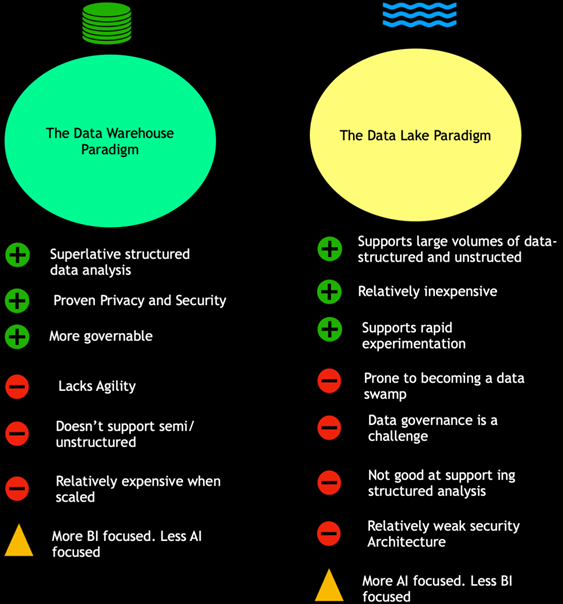
数据湖并不能够替代数据仓库,数据仓库在高效的报表和可视化分析中仍有优势。
湖仓一体
Data Lakehouse(湖仓一体)是新出现的一种数据架构,它同时吸收了数据仓库和数据湖的优势,数据分析师和数据科学家可以在同一个数据存储中对数据进行操作,同时它也能为公司进行数据治理带来更多的便利性。
LakeHouse使用新的系统设计:直接在用于数据湖的低成本存储上实现与数据仓库中类似的数据结构和数据管理功能,是一种结合数据湖和数据仓库****优势的新范式,从根本上简化企业数据基础架构,并且有望在机器学习已渗透到每个行业的时代加速创新。

数据湖框架
目前市面上流行的三大开源数据湖方案分别为:Delta Lake、Apache Iceberg和Apache Hudi
| 方案 | 厂商 | 特点 | 链接 |
|---|---|---|---|
| Delta Lake | DataBricks | Spark强绑定 | https://delta.io/ |
| Apache Iceberg | Netflix | 类似于SQL的形式高性能的处理大型的开放式表 | https://iceberg.apache.org/ |
| Apache Hudi | Uber | 管理大型分析数据集在HDFS上的存储,(更新) | https://hudi.apache.org/ |
Delta Lake
Delta Lake 是一个存储层,为 Apache Spark 和大数据 workloads 提供 ACID 事务能力,其通过写和快照隔离之间的乐观并发控制(optimistic concurrency control),在写入数据期间提供一致性的读取,从而为构建在 HDFS 和云存储上的数据湖(data lakes)带来可靠性。Delta Lake 还提供内置数据版本控制,以便轻松回滚。
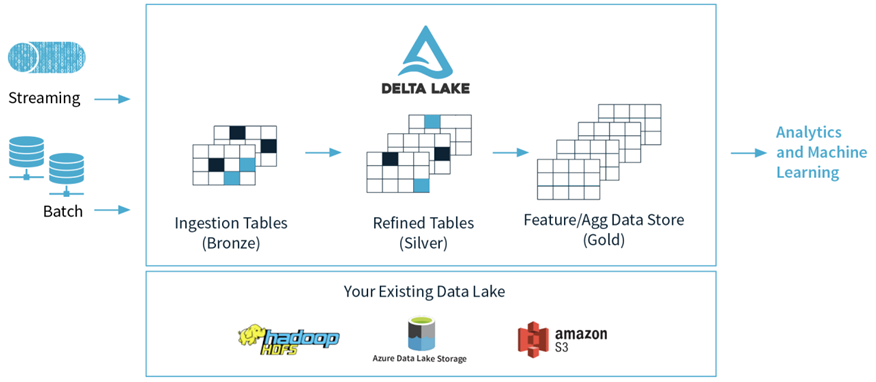
由于出自Databricks,Spark的所有数据写入方式,包括基于dataframe的批式、流式,以及SQL的Insert、Insert Overwrite等都是支持的(开源的SQL写暂不支持,EMR做了支持)。
数据写入方面,Delta 与 Spark 是强绑定的;在查询方面,开源 Delta 目前支持 Spark 与 Presto,但是,Spark 是不可或缺的,因为 delta log 的处理需要用到 Spark。流批一体的Data Lake存储层,支持 update/delete/merge
Apache Iceberg
Apache Iceberg 由 Netflix 开发开源的,其于 2018年11月16日进入 Apache 孵化器,是 Netflix 公司数据仓库基础。
Apache Iceberg是一种开放的数据湖表格式。您可以借助Iceberg快速地在HDFS或者云上构建自己的数据湖存储服务,并借助开源大数据生态的Spark、Flink、Hive和Presto等计算引擎来实现数据湖的分析。
Apache Iceberg设计初衷是为了解决Hive数仓上云的问题,经过多年迭代已经发展成为云上构建数据湖服务的表格式标准。
在查询方面,Iceberg 支持 Spark、Presto,提供了建表的 API,用户可以使用该 API 指定表明、schema、partition 信息等,然后在 Hive catalog 中完成建表。
Apache Hudi
Apache Hudi 在 HDFS 的数据集上提供了插入更新和增量拉取的流原语。
一般来说,我们会将大量数据存储到 HDFS,新数据增量写入,而旧数据鲜有改动,特别是在经过数据清洗,放入数据仓库的场景。而且在数据仓库如 hive 中,对于 update 的支持非常有限,计算昂贵。另一方面,若是有仅对某段时间内新增数据进行分析的场景,则 hive、presto、hbase 等也未提供原生方式,而是需要根据时间戳进行过滤分析。
在此需求下,Hudi 可以提供这两种需求的实现。第一个是对 record 级别的更新,另一个是仅对增量数据的查询。且 Hudi 提供了对 Hive、presto、Spark 的支持,可以直接使用这些组件对 Hudi 管理的数据进行查询。
Hudi 是一个通用的大数据存储系统,主要特性:
- 摄取和查询引擎之间的快照隔离,包括 Apache Hive、Presto 和 Apache Spark。
- 支持回滚和存储点,可以恢复数据集。
- 自动管理文件大小和布局,以优化查询性能准实时摄取,为查询提供最新数据。
- 实时数据和列数据的异步压缩。
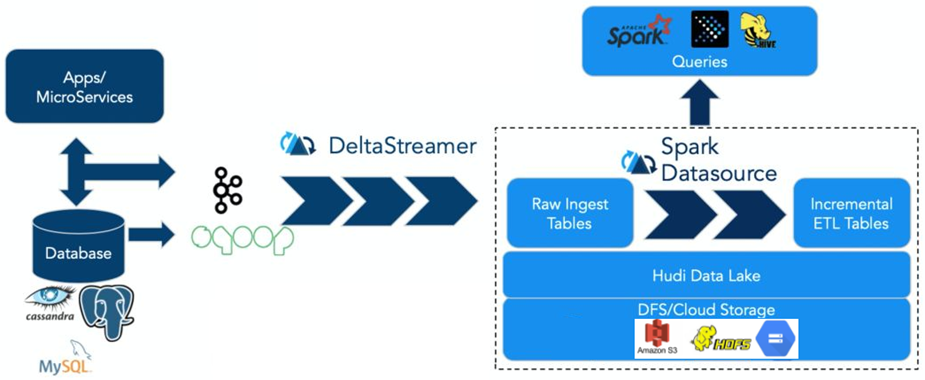
Apache Hudi 强调其主要支持Upserts、Deletes和Incrementa数据处理,支持三种数据写入方式:UPSERT,INSERT 和 BULK_INSERT。
对比
| Iceberg | Hudi | Iceberg | |
|---|---|---|---|
| Incremental Ingestion | Spark | Spark | Spark |
| ACID updates | HDFS, S3 (Databricks), OSS | HDFS | HDFS, S3 |
| Upserts/Delete/Merge/Update | Delete/Merge/Update | Upserts/Delete | No |
| Streaming sink | Yes | Yes | Yes(not ready?) |
| Streaming source | Yes | No | No |
| FileFormats | Parquet | Avro,Parquet | Parquet, ORC |
| Data Skipping | File-Level Max-Min stats + Z-Ordering (Databricks) | File-Level Max-Min stats + Bloom Filter | File-Level Max-Min Filtering |
| Concurrency control | Optimistic | Optimistic | Optimistic |
| Data Validation | Yes (Databricks) | No | Yes |
| Merge on read | No | Yes | No |
| Schema Evolution | Yes | Yes | Yes |
| File I/O Cache | Yes (Databricks) | No | No |
| Cleanup | Manual | Automatic | No |
| Compaction | Manual | Automatic | No |



