Hive 简介
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。 Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。Hive 没有专门的数据格式。 Hive 可以很好的工作在 Thrift 之上,控制分隔符,也允许用户指定数据格式。
本质是:将HQL转化成MapReduce程序

Hive的基本架构
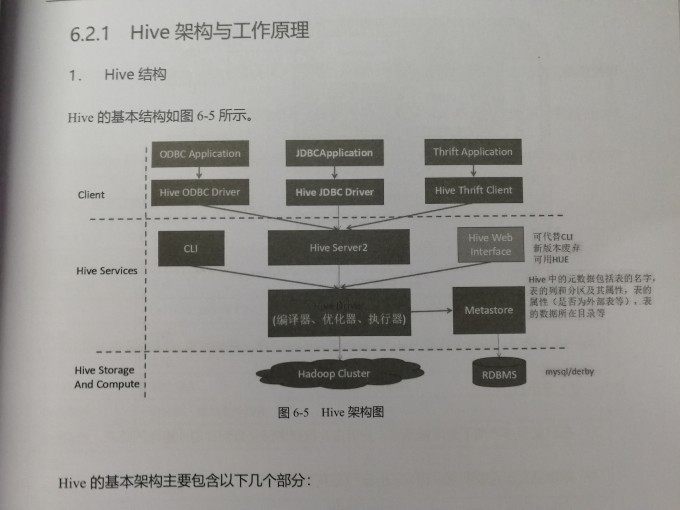
| 单元名称 | 功能 |
|---|---|
| CLI | Hive的命令行借口(shell环境) |
| hiveserver2 | 让Hive以提供Thrift服务,允许用不同语言编写的客户端访问。 |
| Hive Web Interface | Hive的web借口,这个简单的Web可以替代CLI。但新版本已经被废弃 |
| Metastore | 用于保存Hive中的元数据的服务模式 |
| RDBMS | 可以使Mysql或Derby(嵌入的数据库) |
| Hive Driver | 包含Hive编辑器、优化器、执行器。 |
Hive的执行引擎
Hive的原始设计是以MapReduce作为执行引擎(目前仍然还是)。Hive的执行引擎还包括Apache Tez,对Spark的支持也在开发中,Tez和Spark都是通用有向无环图(DAG)他们比MapReduce更加灵活,性能更加优越。在Mapreduce过程中,中间的作业输出会被“物化”存储到HDFS上,Tez和Spark则不同,他们根据Hive的规划器请求,把中间结果写到本地的磁盘上,甚至在内存中缓存,可以避免额外的复制开销。
**执行引擎由属性hive.execution.engine来控制,默认值是mr(MapReduce)**可以通过下面的语句设置Tez为Hive的执行引擎。
hive> SET hive.execution.engine=tez;Hive服务
cli Hive命令行接口(shell环境)默认
hiveserver2 让Hive以提供Thrift服务的服务器的形式运行,允许不同语言编写的客户端进行访问,hiverserver2支持认证多用户并发,使用Thrift、JDBC和ODBC链接客户端需要运行Hive服务器和Hive进行通信。通过设置hive.server2.thrift.port 配置属性来知名服务器所监听的端口号默认是(10000)
beeline 以嵌入式的方式工作的Hive命令行接口(类似于常规的CLI),或者使用JDBC连接到HiveServer2进程。
hwi Hive 的Web借口。在没有安装任何客户端软件的情况下,这个简单的Web借口可以代替CLI。另外,Hue是一个更加全面的Web借口,其中包括运行Hive的查询和浏览Hive meatastore的应用程序。
- jar 和 hadoop jar类似 是运行类路径中 包含Hadoop 和Hive类Java应用程序的简便方法。
- metastore 默认情况下metastore和Hive服务运行在同一个进程里。使用这个服务,可以让meatstore作为一个单独的(远程)进程运行,通过设置METASTORE_PORT环境变量(或者使用 -p 的命令来制定服务器监听的端口号默认是9083)
### Hive客户端
如果以服务器的方式运行Hive(hive - - server hiveserver2 ),可以在应用程序中以不同的机制连接到服务器,Hive客户端和服务之间的联系如图所示Hive的工作原理

查询解析和编译
Hive接口如命令行或者Web UI 发送查询驱动程序(任何数据库驱动程序,如JDBC、ODBC等)来执行
在驱动的帮助下查询编译器分析查询检查的语法和查询计划或者查询的要求。
编译器发送元数据请求到MetaStore。
MetaStore发送元数据,以编译器响应。
编译器检查要求,重新发送计划给驱动程序。到此为止,查询解析和编译完成。
驱动器发送的执行计划到执行引擎
内部执行
- 在内部执行作业的过程是一个MapReduce工作,Hadoop 2.0采用的就是MapReduce2.0,它是在YARN中运行。
- 与此同时,在执行引擎可以通过Metastore执行元数据操作。
- 执行应请接受来自数据节点的结果。
- 执行引擎发送这些结果值给驱动程序。
- 驱动程序将结果发给Hive接口。
架构原理
1.用户接口:Client
CLI(hive shell)、JDBC/ODBC(java访问hive)、WEBUI(浏览器访问hive)
2.元数据:Metastore
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;
默认存储在自带的derby数据库中,推荐使用MySQL存储Metastore
3.Hadoop
使用HDFS进行存储,使用MapReduce进行计算。
4.驱动器:Driver
(1)解析器(SQL Parser):将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
(2)编译器(Physical Plan):将AST编译生成逻辑执行计划。
(3)优化器(Query Optimizer):对逻辑执行计划进行优化。
(4)执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是MR/Spark。

Hive通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的Driver,结合元数据(MetaStore),将这些指令翻译成MapReduce,提交到Hadoop中执行,最后,将执行返回的结果输出到用户交互接口。
Hive 和传统数据库的比较
| 比较项 | 传统数据库 | HiveQL |
|---|---|---|
| ANSI SQL | 支持 | 不完全支持 |
| 更新 | UPDATE\INSERT\DELETE | insert OVERWRITE\INTO TABLE(不建议update) |
| 事务 | 支持 | 不支持 |
| 模式 | 写模式 | 读模式 |
| 数据保存 | 块设备、本地文件系统 | HDFS |
| 延时 | 低 | 高 |
| 多表插入 | 不支持 | 支持 |
| 子查询 | 完全支持 | 只能用在From子句中 |
| 视图 | Updatable | Read-only |
| 可扩展性 | 低 | 高 |
| 数据规模 | 小 | 大 |
Hive安装
1.把apache-hive-1.2.1-bin.tar.gz上传到linux的/opt/software目录下
tar -zxvf apache-hive-1.2.1-bin.tar.gz -C /opt/module/2.修改apache-hive-1.2.1-bin.tar.gz的名称为hive
mv apache-hive-1.2.1-bin/ hive3.修改/opt/module/hive/conf目录下的hive-env.sh.template名称为hive-env.sh
mv hive-env.sh.template hive-env.sh4.配置hive-env.sh文件
##配置HADOOP_HOME路径
export HADOOP_HOME=/opt/module/hadoop
### 配置HIVE_CONF_DIR路径
export HIVE_CONF_DIR=/opt/module/hive/confHadoop集群配置
启动hdfs和yarn
start-dfs.sh
start-yarn.sh创建工作目录
hadoop fs -mkdir /tmp
hadoop fs -mkdir -p /user/hive/warehouse或者在配置文件中关闭权限检查 在hadoop 的hdfs-site.xml 中
<property>
<name>dfs.permissions.enable</name>
<value>false</value>
</property>MySql安装:
软件链接:https://pan.baidu.com/s/1MMfHnjd8HY41ShbYtvqGZg 提取码:ycwm
Metastore默认存储在自带的derby数据库中,推荐使用MySQL存储Metastore;
1.查看mysql是否安装,如果安装了,卸载mysql
rpm -qa|grep mysql
mysql-libs-5.1.73-7.el6.x86_64
rpm -e --nodeps mysql-libs-5.1.73-7.el6.x86_642.安装Mysql
rpm -ivh MySQL-server-5.6.24-1.el6.x86_64.rpm3.查看随机密码
cat /root/.mysql_secret4.查看Mysql状态
service mysql status
service mysql start5.安装客户端
rpm -ivh MySQL-client-5.6.24-1.el6.x86_64.rpm6.登录mysql
mysql -uroot -p你的密码7.修改密码
mysql>SET PASSWORD=PASSWORD('123456');user表配置
## 登录mysql
mysql -uroot -p123456
## 使用mysql数据库
mysql>use mysql;
## 展示mysql数据库中的所有表
mysql>show tables;
## 展示user表的结构
mysql>desc user;
## mysql>select User, Host, Password from user;
mysql>update user set host='%' where host='localhost';
## 删除root用户的其他host
mysql>delete from user where Host='daanode1';
mysql>delete from user where Host='127.0.0.1';
mysql>delete from user where Host='::1';
## 刷新权限
mysql>flush privileges;
## 退出
mysql>quit;Hive元数据配置到MySql
cp mysql-connector-java-5.1.27-bin.jar /opt/module/hive/lib/[hadoop@datanode1 conf]$ pwd
/opt/module/hive/conf
[hadoop@datanode1 conf]$ vim hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://datanode1:3306/metastore?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against metastore database</description>
</property>
</configuration>配置完毕后,如果启动hive异常,可以重新启动虚拟。
1.连接mysql
[hadoop@datanode1 conf]$ mysql -uroot -p
Enter password:mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| metastore |
| mysql |
| mysqlsource |
| oozie |
| performance_schema |
| student |
+--------------------+
7 rows in set (0.00 sec)常见属性配置
Hive数据仓库位置配置
(1)Default数据仓库的最原始位置是在hdfs上的:/user/hive/warehouse路径下。
(2)在仓库目录下,没有对默认的数据库default创建文件夹。如果某张表属于default数据库,直接在数据仓库目录下创建一个文件夹。
(3)修改default数据仓库原始位置(将hive-default.xml.template如下配置信息拷贝到hive-site.xml文件中)。
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>配置同组用户有执行权限
bin/hdfs dfs -chmod g+w /user/hive/warehouse查询后信息显示配置
(1)在hive-site.xml文件中添加如下配置信息,就可以实现显示当前数据库,以及查询表的头信息配置。
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>Hive运行日志信息配置
1.Hive的log默认存放在/tmp/hadoop/hive.log目录下(当前用户名下)
2.修改hive的log存放日志到/opt/module/hive/logs
修改 hive-log4j.properties.template 文件名称为 hive-log4j.properties
[hadoop@datanode1 conf]$ pwd
/opt/module/hive/conf
[hadoop@datanode1 conf]$ mv hive-log4j.properties.template hive-log4j.properties
[hadoop@datanode1 conf]$ vim hive-log4j.properties
## 设置存储位置为
hive.log.dir=/opt/module/hive/logs参数配置方式
1.查看当前所有的配置信息
hive>set;2.参数的配置三种方式
(1)配置文件方式
默认配置文件:hive-default.xml 用户自定义配置文件:hive-site.xml
注意:用户自定义配置会覆盖默认配置。另外,Hive也会读入Hadoop的配置,因为Hive是作为Hadoop的客户端启动的,Hive的配置会覆盖Hadoop的配置。配置文件的设定对本机启动的所有Hive进程都有效。
(2)命令行参数方式
启动Hive时,可以在命令行添加-hiveconf param=value来设定参数仅对本次hive启动有效。
例如:
[hadoop@datanode1 hive]$ bin/hive -hiveconf mapred.reduce.tasks=10;
hive > set mapred.reduce.tasks;
mapred.reduce.tasks=10(3)参数声明方式
hive> set mapred.reduce.tasks=100;
hive> set mapred.reduce.tasks;
mapred.reduce.tasks=100上述三种设定方式的优先级依次递增。即配置文件<命令行参数<参数声明。注意某些系统级的参数,例如log4j相关的设定,必须用前两种方式设定,因为那些参数的读取在会话建立以前已经完成了。
Hive 命令操作
1.在hive cli命令窗口中如何查看hdfs文件系统
hive> dfs -ls /;
Found 11 items2.在hive cli命令窗口中如何查看本地文件系统
hive> ! ls /opt/module/;3.查看在hive中输入的所有历史命令
[hadoop@datanode1 ~]$ pwd
/home/hadoop
[hadoop@datanode1 ~]$ cat .hivehistory交互命令
bin/hive -help
usage: hive
-d,--define <key=value> Variable subsitution to apply to hive
commands. e.g. -d A=B or --define A=B
--database <databasename> Specify the database to use
-e <quoted-query-string> SQL from command line
-f <filename> SQL from files
-H,--help Print help information
--hiveconf <property=value> Use value for given property
--hivevar <key=value> Variable subsitution to apply to hive
commands. e.g. --hivevar A=B
-i <filename> Initialization SQL file
-S,--silent Silent mode in interactive shell
-v,--verbose Verbose mode (echo executed SQL to the console)1.“-e”不进入hive的交互窗口执行sql语句
[hadoop@datanode1 hive]$ bin/hive -e "select id from student;"2.“-f”执行脚本中sql语句
[hadoop@datanode1 datas]$ vim hivef.sql
select *from student;
## 执行
[hadoop@datanode1 hive]$ bin/hive -f /opt/module/datas/hivef.sql
## 将结果写入文件中
[hadoop@datanode1 hive]$ bin/hive -f /opt/module/datas/hivef.sql > /opt/module/datas/hive_result.txt


