关于窗口这里不在展开论述,之前已经写到过了,本文重点关注SQL如何实现Flink Window的效果。本次使用的kafka数据JSON格式如下:
"{\"Id\":9990,\"Name\":\"Nmae_9990\",\"Operation\":\"favourite\",\"t\":1630396020,\"opt\":2}"package com.hph.bean;
public class UserAction {
private int Id;
private String Name;
private String Operation;
private Long t;
private int opt;
public int getId() {
return Id;
}
public void setId(int id) {
Id = id;
}
public String getName() {
return Name;
}
public void setName(String name) {
Name = name;
}
public String getOperation() {
return Operation;
}
public void setOperation(String operation) {
Operation = operation;
}
public Long getT() {
return t;
}
public void setT(Long t) {
this.t = t;
}
public int getOpt() {
return opt;
}
public void setOpt(int opt) {
this.opt = opt;
}
public UserAction(int id, String name, String operation, Long t, int opt) {
Id = id;
Name = name;
Operation = operation;
this.t = t;
this.opt = opt;
}
@Override
public String toString() {
return "UserAction{" +
"Id=" + Id +
", Name='" + Name + '\'' +
", Operation='" + Operation + '\'' +
", t=" + t +
", opt=" + opt +
'}';
}
}测试发送kafka数据程序如下。
package com.hph.producer;
import com.google.gson.Gson;
import com.hph.bean.UserAction;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.io.IOException;
import java.util.Properties;
import java.util.Random;
public class UserActionProducer {
public static void main(String[] args) throws IOException, InterruptedException {
Properties props = new Properties();
// Kafka服务端的主机名和端口号
props.put("bootstrap.servers", "hadoop102:9092,hadoop103:9092,hadoop104:9092");
// 等待所有副本节点的应答
props.put("acks", "all");
// 消息发送最大尝试次数
props.put("retries", 0);
// 一批消息处理大小
props.put("batch.size", 16384);
// 请求延时
props.put("linger.ms", 1);
// 发送缓存区内存大小
props.put("buffer.memory", 33554432);
// key序列化
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// value序列化
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Gson gson = new Gson();
Producer<String, String> producer = new KafkaProducer<>(props);
String[] action = {"click", "favourite", "add", "commit", "post"};
for (int i = 0; i < Integer.MAX_VALUE; i++) {
int opt = new Random().nextInt(100);
long timestamp = System.currentTimeMillis() / 1000;
//String id, String name, String operation, Long timestamp, String opt
UserAction userAction = new UserAction(i, "Nmae_" + i, action[new Random().nextInt(3)], timestamp, new Random().nextInt(3));
String json = gson.toJson(userAction);
System.out.println(json);
producer.send(new ProducerRecord<String, String>("us_ac", json));
}
producer.close();
}
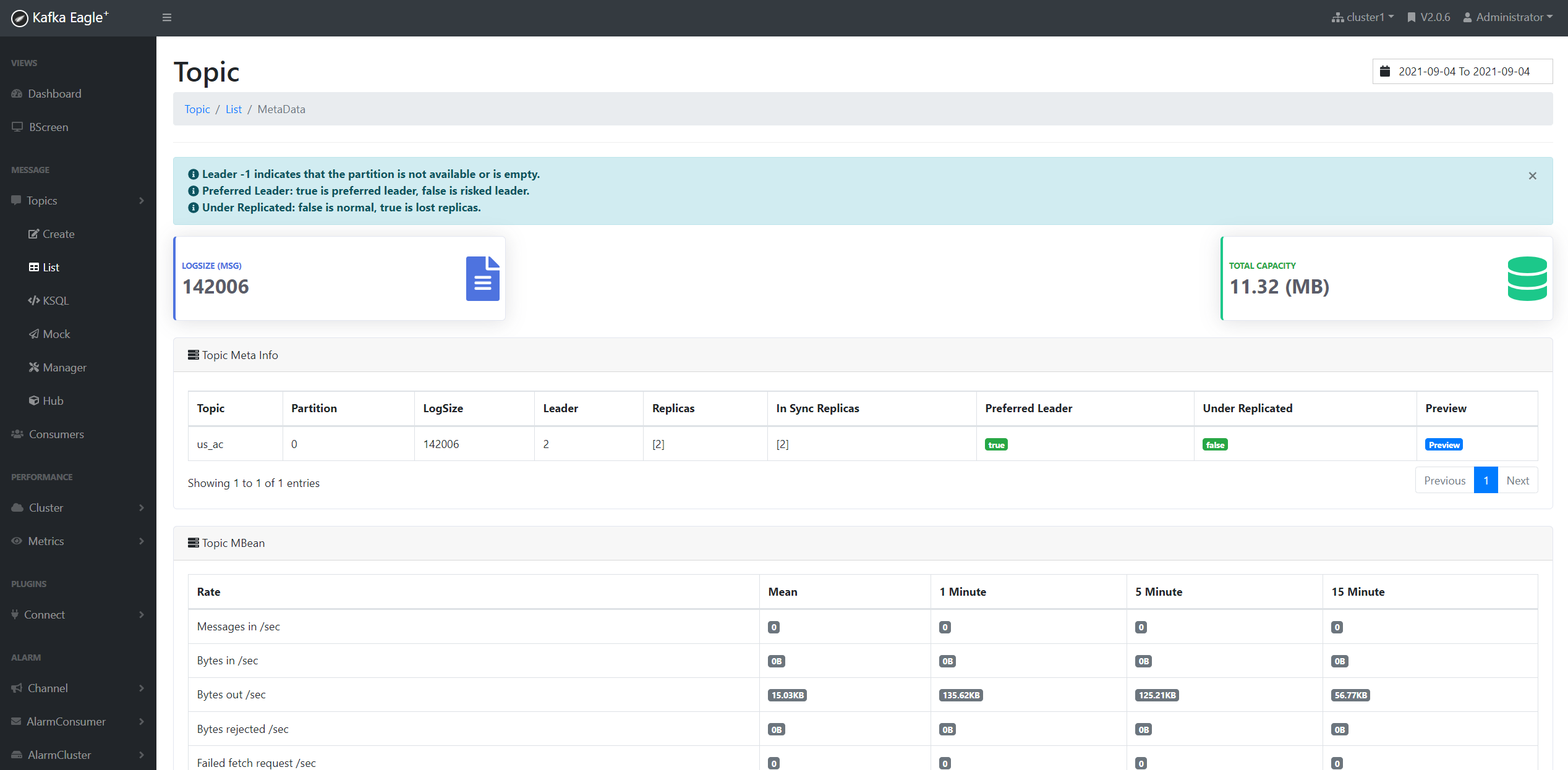
}从Kafka监控中我们可以看到数据总条数为142006条。
下面主要演示的以处理时间为时间属性的Window SQL
ProcessTime
TumbleWindowsSQL
package com.hph.sql.window.processtime;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
/**
* 滚动窗口Demo
*/
public class TumbleWindowsSQL {
public static void main(String[] args) {
EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//{"Id":455006,"Name":"Nmae_455006","Operation":"favourite","timestamp":1629293081,"opt":0}
//创建Kafka 数据源
tableEnv.executeSql("CREATE TABLE KafkaTable (\n" +
" `Id` INT,\n" +
" `Name` STRING,\n" +
" `Operation` STRING,\n" +
" `opt` STRING,\n" +
" `t` AS PROCTIME()\n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'us_ac',\n" +
" 'properties.bootstrap.servers' = 'hadoop102:9092,hadoop103:9092,hadoop104:9092',\n" +
" 'properties.group.id' = 'tumble',\n" +
" 'scan.startup.mode' = 'earliest-offset',\n" +
" 'format' = 'json'\n" +
")");
//SQL 1
// GROUP BY TUMBLE(t, INTERVAL '1' MINUTES) 相当于根据1m的时间来划分窗口
// TUMBLE_START(t, INTERVAL '1' MINUTES) 获取窗口的开始时间
// TUMBLE_END(t, INTERVAL '1' MINUTES) 获取窗口的结束时间
/* tableEnv.executeSql("SELECT TUMBLE_START(t, INTERVAL '1' MINUTES) AS window_start," +
"TUMBLE_END(t, INTERVAL '1' MINUTES) AS window_end, count(Id) as One_PV FROM KafkaTable"
+ " GROUP BY TUMBLE(t, INTERVAL '1' MINUTES)").print();
*/
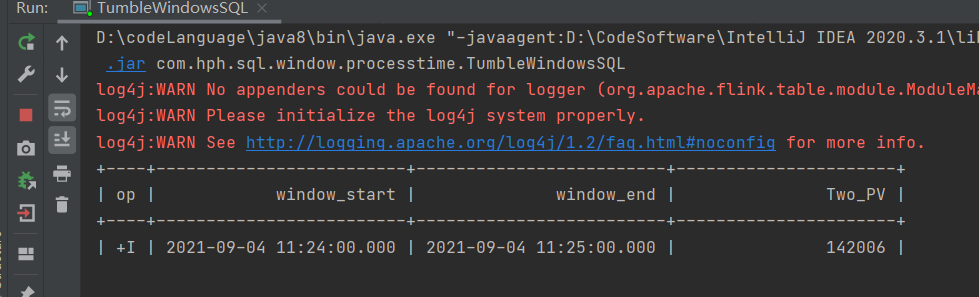
// SQL2
tableEnv.executeSql(" SELECT window_start, window_end, count(Id) as Two_PV\n" +
" FROM TABLE(\n" +
" TUMBLE(TABLE KafkaTable, DESCRIPTOR(t), INTERVAL '1' MINUTES))\n" +
" GROUP BY window_start, window_end").print();
}
}
CumulateWind
package com.hph.sql.window.processtime;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
public class CumulateWindowSQL {
public static void main(String[] args) {
EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//{"Id":455006,"Name":"Nmae_455006","Operation":"favourite","timestamp":1629293081,"opt":0}
//创建Kafka 数据源
tableEnv.executeSql("CREATE TABLE KafkaTable (\n" +
" `Id` INT,\n" +
" `Name` STRING,\n" +
" `Operation` STRING,\n" +
" `opt` STRING,\n" +
" `t` AS PROCTIME()\n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'us_ac',\n" +
" 'properties.bootstrap.servers' = 'hadoop102:9092,hadoop103:9092,hadoop104:9092',\n" +
" 'properties.group.id' = 'cumulate',\n" +
" 'scan.startup.mode' = 'earliest-offset',\n" +
" 'format' = 'json'\n" +
")");
tableEnv.executeSql("SELECT window_start, window_end, COUNT(Id) AS PV\n" +
" FROM TABLE(\n" +
" CUMULATE(TABLE KafkaTable, DESCRIPTOR(t), INTERVAL '2' SECOND, INTERVAL '2' SECOND))\n" +
" GROUP BY window_start, window_end").print();
}
}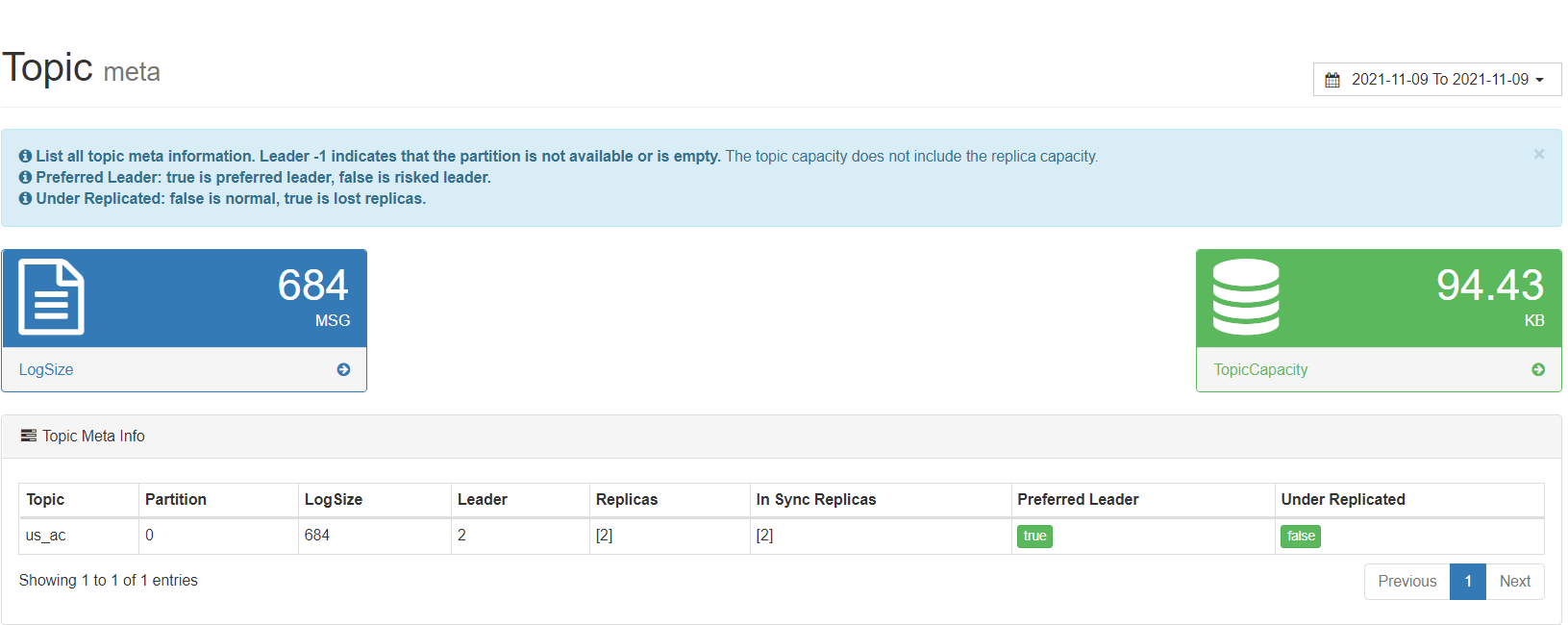
从图中我们可以看到us_ac中已经存在684条数据,在Flink中累计窗口
Cumulate window 就是累计窗口,简单来说,以上图里面时间轴上的一个区间为窗口步长。
第一个 window 统计的是一个区间的数据;
第二个 window 统计的是第一区间和第二个区间的数据;
第三个 window 统计的是第一区间,第二个区间和第三个区间的数据。
累积计算在业务场景中非常常见,如累积 UV 场景。累计PV场景等。

HopWindowsSQL
package com.hph.sql.window.processtime;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
public class HopWindowsSQL {
//滑动窗口
public static void main(String[] args) {
EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//{"Id":455006,"Name":"Nmae_455006","Operation":"favourite","timestamp":1629293081,"opt":0}
//创建Kafka 数据源
tableEnv.executeSql("CREATE TABLE KafkaTable (\n" +
" `Id` INT,\n" +
" `Name` STRING,\n" +
" `Operation` STRING,\n" +
" `opt` STRING,\n" +
" `t` AS PROCTIME()\n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'us_ac',\n" +
" 'properties.bootstrap.servers' = 'hadoop102:9092,hadoop103:9092,hadoop104:9092',\n" +
" 'properties.group.id' = 'hop_process_time',\n" +
" 'scan.startup.mode' = 'earliest-offset',\n" +
" 'format' = 'json'\n" +
")");
// tableEnv.executeSql("SELECT HOP_START(t, INTERVAL '2' SECOND, INTERVAL '2' SECOND) AS window_start,"
// + "HOP_END(t, INTERVAL '2' SECOND, INTERVAL '2' SECOND) AS window_end, COUNT(Id) FROM "
// + "KafkaTable" + " GROUP BY HOP(t, INTERVAL '2' SECOND, INTERVAL '2' SECOND)").print();
// tableEnv.executeSql("SELECT HOP_START(t, INTERVAL '2' SECOND, INTERVAL '2' SECOND) AS window_start,"
// + "HOP_END(t, INTERVAL '2' SECOND, INTERVAL '2' SECOND) AS window_end, COUNT(Id) FROM "
// + "KafkaTable" + " GROUP BY HOP(t, INTERVAL '2' SECOND, INTERVAL '2' SECOND)").print();
tableEnv.executeSql("SELECT window_start, window_end, COUNT(Id) \n" +
" FROM TABLE(\n" +
" HOP(TABLE KafkaTable, DESCRIPTOR(t), INTERVAL '1' MINUTES,INTERVAL '1' MINUTES))\n" +
" GROUP BY window_start, window_end").print();
}
}
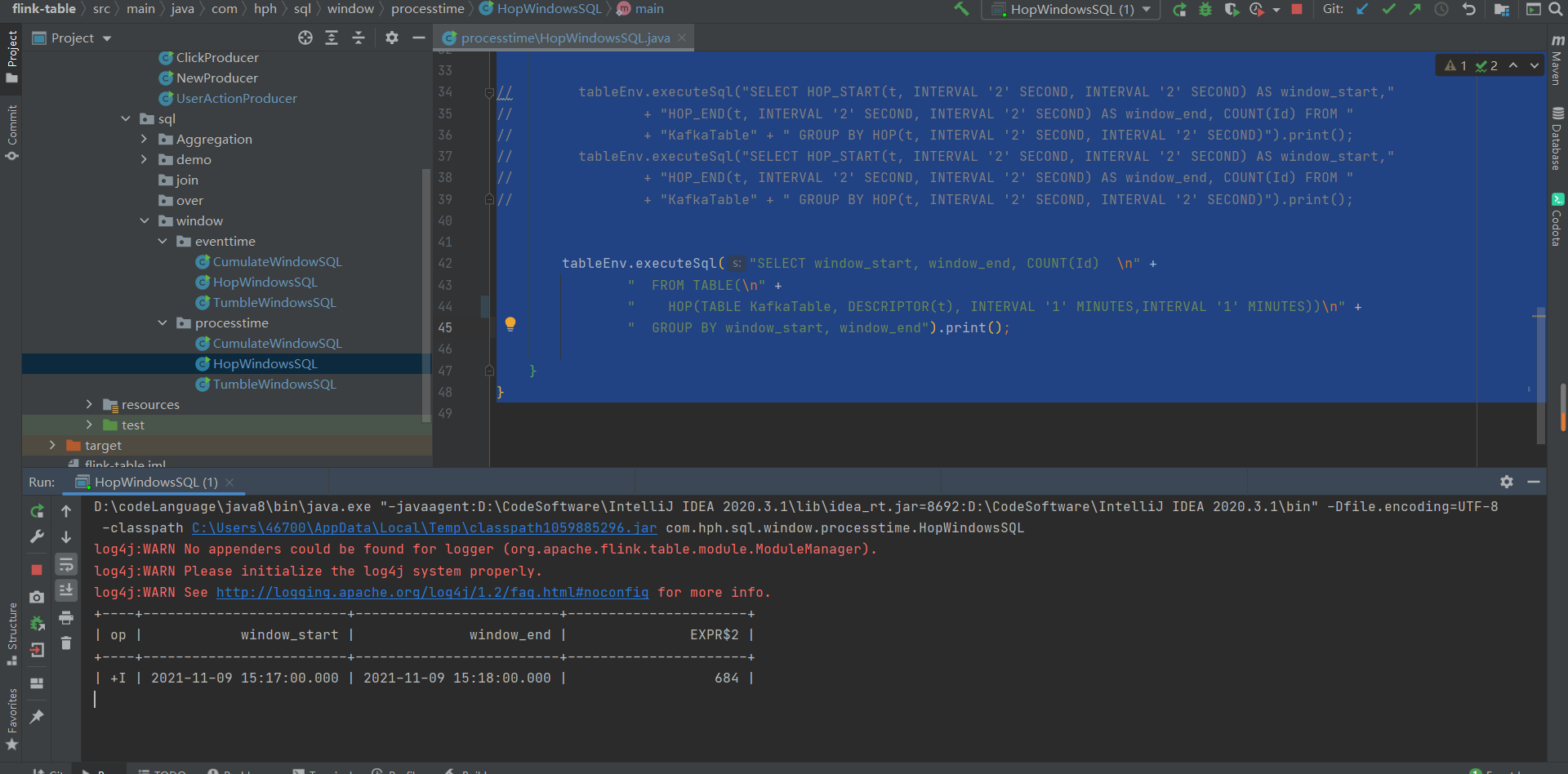
从结果我们可以看到在1分钟之内滑动窗口结果为684,包含了对累计历史累计数据的计算。
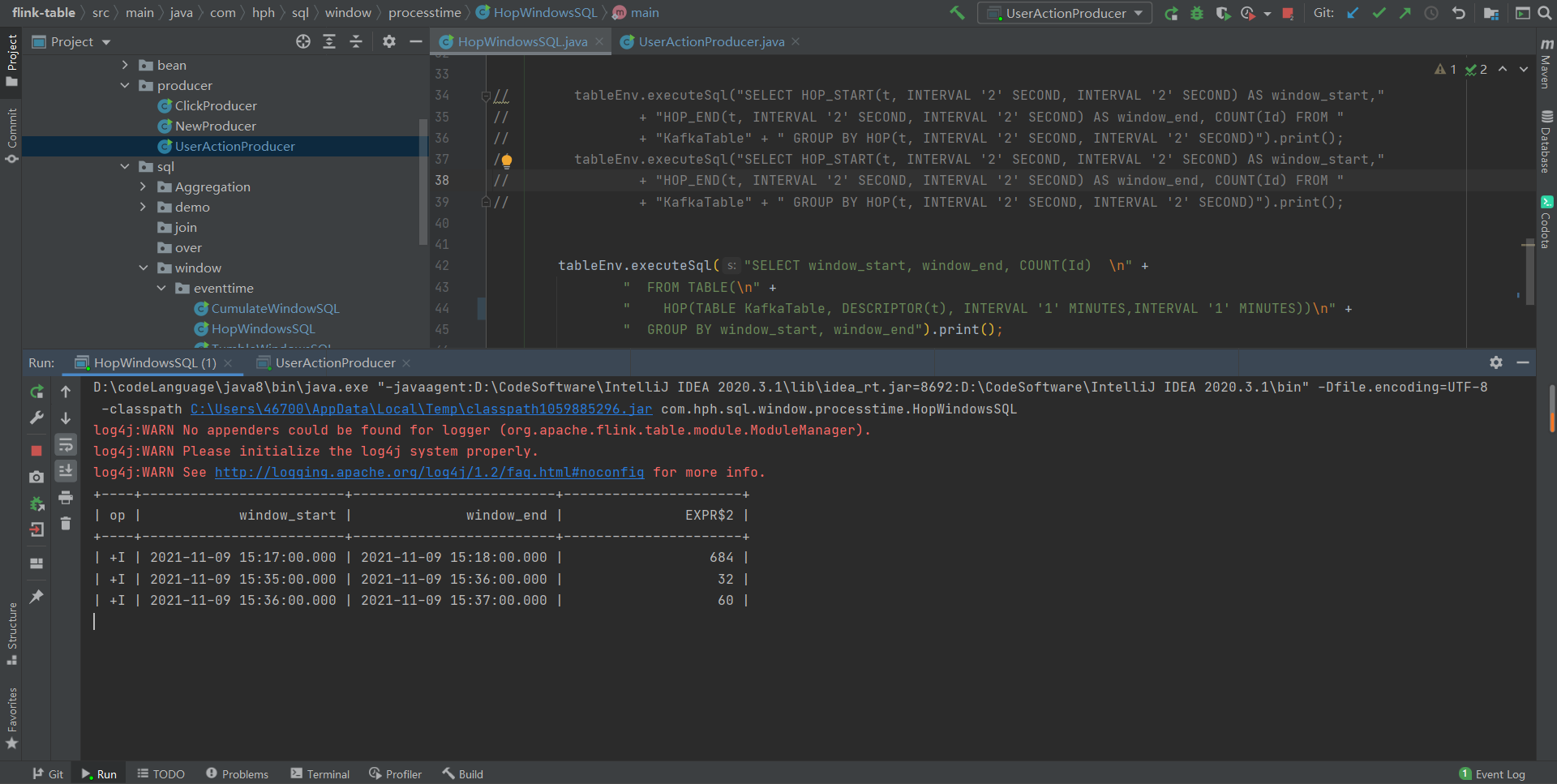
每隔1s发送到kafka1条数据,我们可以看到1分钟的滑动窗口计算结果复合我们的预期。
EventTime
EventTimeCumulateWindowSQL
package com.hph.sql.window.eventtime;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
public class EventTimeCumulateWindowSQL {
public static void main(String[] args) {
EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//{"Id":455006,"Name":"Nmae_455006","Operation":"favourite","timestamp":1629293081,"opt":0}
//创建Kafka 数据源
tableEnv.executeSql("CREATE TABLE KafkaTable (\n" +
" `Id` INT,\n" +
" `Name` STRING,\n" +
" `Operation` STRING,\n" +
" `t` BIGINT, \n" +
" `opt` STRING,\n" +
" time_ltz AS TO_TIMESTAMP_LTZ(t, 0),\n" +
" WATERMARK FOR time_ltz AS time_ltz - INTERVAL '0' SECOND \n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'us_ac',\n" +
" 'properties.bootstrap.servers' = 'hadoop102:9092,hadoop103:9092,hadoop104:9092',\n" +
" 'properties.group.id' = 'cumulate',\n" +
" 'scan.startup.mode' = 'earliest-offset',\n" +
" 'format' = 'json'\n" +
")");
tableEnv.executeSql("SELECT window_start, window_end, COUNT(Id) AS cnt\n" +
" FROM TABLE(\n" +
" CUMULATE(TABLE KafkaTable, DESCRIPTOR(time_ltz), INTERVAL '1' MINUTES, INTERVAL '1' MINUTES))\n" +
" GROUP BY window_start, window_end").print();
}
}
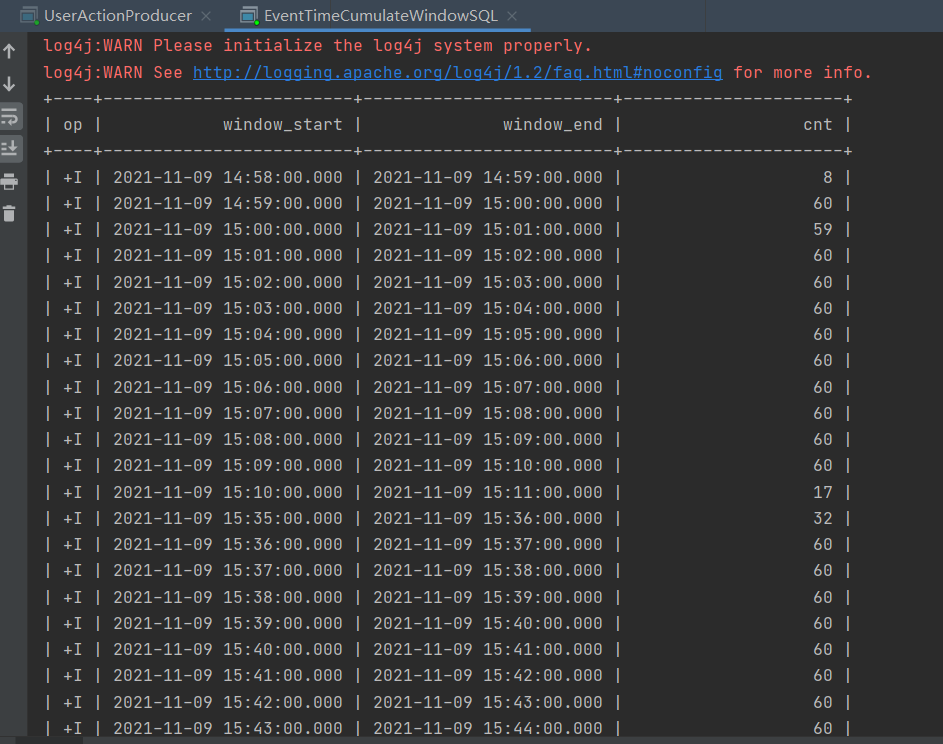
由于是EventTime,当满足窗口时便会触发计算。
EventTimeHopWindowsSQL
package com.hph.sql.window.eventtime;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
public class EventTimeHopWindowsSQL {
//滑动窗口
public static void main(String[] args) {
EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//{"Id":455006,"Name":"Nmae_455006","Operation":"favourite","timestamp":1629293081,"opt":0}
//创建Kafka 数据源
tableEnv.executeSql("CREATE TABLE KafkaTable (\n" +
" `Id` INT,\n" +
" `Name` STRING,\n" +
" `Operation` STRING,\n" +
" `opt` STRING,\n" +
" `t` BIGINT, \n" +
" time_ltz AS TO_TIMESTAMP_LTZ(t, 0),\n" +
" WATERMARK FOR time_ltz AS time_ltz - INTERVAL '2' SECOND \n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'us_ac',\n" +
" 'properties.bootstrap.servers' = 'hadoop102:9092,hadoop103:9092,hadoop104:9092',\n" +
" 'properties.group.id' = 'hop_process_time',\n" +
" 'scan.startup.mode' = 'earliest-offset',\n" +
" 'format' = 'json'\n" +
")");
// tableEnv.executeSql("SELECT HOP_START(t, INTERVAL '2' SECOND, INTERVAL '2' SECOND) AS window_start,"
// + "HOP_END(t, INTERVAL '2' SECOND, INTERVAL '2' SECOND) AS window_end, COUNT(Id) FROM "
// + "KafkaTable" + " GROUP BY HOP(t, INTERVAL '2' SECOND, INTERVAL '2' SECOND)").print();
// tableEnv.executeSql("SELECT HOP_START(t, INTERVAL '2' SECOND, INTERVAL '2' SECOND) AS window_start,"
// + "HOP_END(t, INTERVAL '2' SECOND, INTERVAL '2' SECOND) AS window_end, COUNT(Id) FROM "
// + "KafkaTable" + " GROUP BY HOP(t, INTERVAL '2' SECOND, INTERVAL '2' SECOND)").print();
tableEnv.executeSql("SELECT window_start, window_end, COUNT(Id) \n" +
" FROM TABLE(\n" +
" HOP(TABLE KafkaTable, DESCRIPTOR(time_ltz), INTERVAL '1' MINUTES,INTERVAL '2' MINUTES))\n" +
" GROUP BY window_start, window_end").print();
}
}
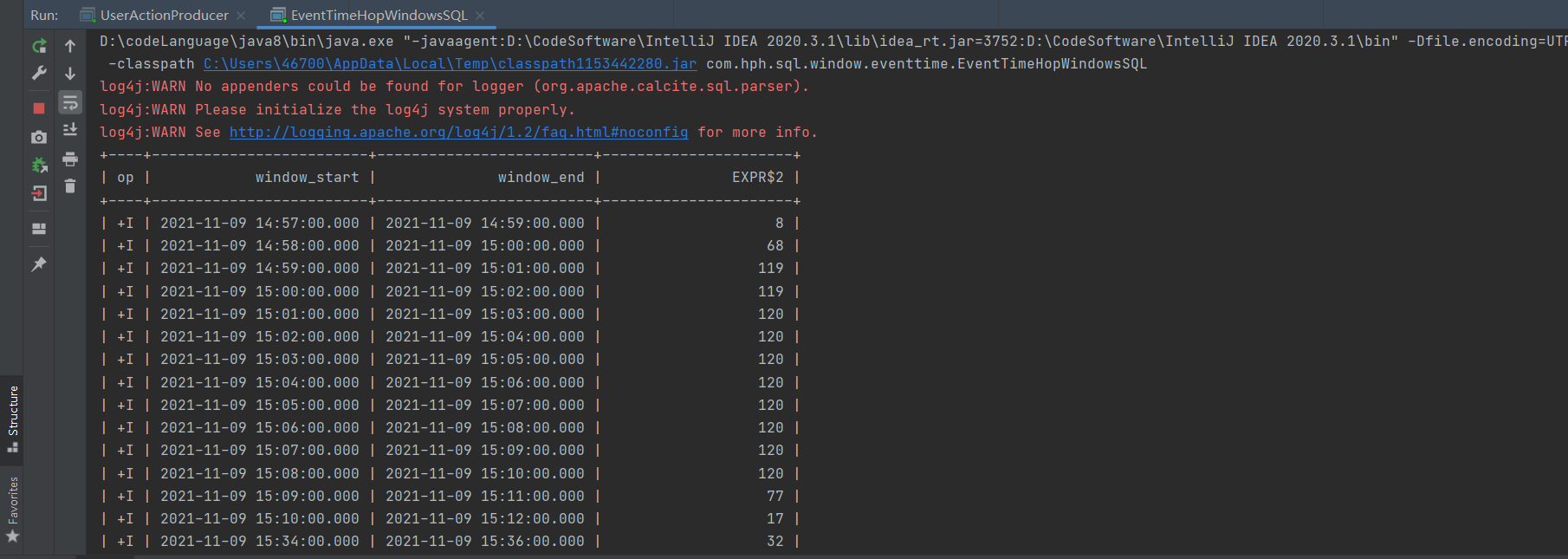
步长为1分钟,滑动窗口为2分钟时,计算结果如图所示。
EventTimeTumbleWindowsSQL
package com.hph.sql.window.eventtime;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
public class EventTimeTumbleWindowsSQL {
public static void main(String[] args) {
EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//{"Id":455006,"Name":"Nmae_455006","Operation":"favourite","timestamp":1629293081,"opt":0}
//创建Kafka 数据源
tableEnv.executeSql("CREATE TABLE KafkaTable (\n" +
" `Id` INT,\n" +
" `Name` STRING,\n" +
" `Operation` STRING,\n" +
" `opt` STRING,\n" +
" `t` BIGINT,\n" +
" time_ltz AS TO_TIMESTAMP_LTZ(t, 0),\n" +
" WATERMARK FOR time_ltz AS time_ltz - INTERVAL '4' SECOND \n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'us_ac',\n" +
" 'properties.bootstrap.servers' = 'hadoop102:9092,hadoop103:9092,hadoop104:9092',\n" +
" 'properties.group.id' = 'tumble',\n" +
" 'scan.startup.mode' = 'earliest-offset',\n" +
" 'format' = 'json'\n" +
")");
// GROUP BY TUMBLE(t, INTERVAL '4' SECOND) 相当于根据4s的时间来划分窗口
// TUMBLE_START(t, INTERVAL '2' SECOND) 获取窗口的开始时间
// TUMBLE_END(t, INTERVAL '2' SECOND) 获取窗口的结束时间
// tableEnv.executeSql("SELECT TUMBLE_START(t, INTERVAL '2' SECOND) AS window_start," +
// "TUMBLE_END(t, INTERVAL '2' SECOND) AS window_end, count(Id) as PV FROM KafkaTable"
// + " GROUP BY TUMBLE(t, INTERVAL '2' SECOND)").print();
tableEnv.executeSql(" SELECT window_start, window_end, count(Id) as PV\n" +
" FROM TABLE(\n" +
" TUMBLE(TABLE KafkaTable, DESCRIPTOR(time_ltz), INTERVAL '4' SECOND))\n" +
" GROUP BY window_start, window_end").print();
}
}


