简介
FlinkTable API和DataStream相似,有相同的编程模型,需要构建相应的TableEnviroment环境,才能够使用相应API。
开发环境
使用Table需要引入相关的依赖这里以Flink 1.13.2为例,所需部分依赖如下
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.11</artifactId>
<version>1.13.2</version>
<!-- <scope>provided</scope>-->
</dependency>
<!-- or.. (for the new Blink planner) -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.11</artifactId>
<version>1.13.2</version>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.13.2</version>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>1.13.2</version>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.13.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>1.13.2</version>
</dependency>样例1
读取文本文件实现Flink对数据的输出
package com.hph.app;
import com.hph.bean.Iris;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
public class FlinkTableDemo {
public static void main(String[] args) throws Exception {
//初始化Stream环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
//创建表环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//读取数据
DataStreamSource<String> dataSource = env.readTextFile("D:\\data\\iris.csv");
//对数据处理
SingleOutputStreamOperator<Iris> map = dataSource.map(x -> {
String[] words = x.split(",");
return new Iris(Double.valueOf(words[0]), Double.valueOf(words[1]), Double.valueOf(words[2]), Double.valueOf(words[3]), words[4]);
//声明返回类型
}).returns(Iris.class);
//转换为表
Table table = tableEnv.fromDataStream(map);
//已经弃用
Table result = table.select("*");
//打印schema
result.printSchema();
//Append-only数据打印
DataStream<Iris> rowDataStream = tableEnv.toAppendStream(result, Iris.class);
rowDataStream.print();
env.execute("job");
}
}
package com.hph.bean;
public class Iris {
//sepal length,sepal width,petal length,petal width,class
private double sepalLength;
private double sepalWidth;
private double petalLength;
private double petalWidth;
private String type;
public double getSepalLength() {
return sepalLength;
}
public void setSepalLength(double sepalLength) {
this.sepalLength = sepalLength;
}
public double getSepalWidth() {
return sepalWidth;
}
public void setSepalWidth(double sepalWidth) {
this.sepalWidth = sepalWidth;
}
public double getPetalLength() {
return petalLength;
}
public void setPetalLength(double petalLength) {
this.petalLength = petalLength;
}
public double getPetalWidth() {
return petalWidth;
}
public void setPetalWidth(double petalWidth) {
this.petalWidth = petalWidth;
}
public String getType() {
return type;
}
public void setType(String type) {
this.type = type;
}
public Iris() {
}
public Iris(double sepalLength, double sepalWidth, double petalLength, double petalWidth, String type) {
this.sepalLength = sepalLength;
this.sepalWidth = sepalWidth;
this.petalLength = petalLength;
this.petalWidth = petalWidth;
this.type = type;
}
@Override
public String toString() {
return "Iris{" +
"sepalLength=" + sepalLength +
", sepalWidth=" + sepalWidth +
", petalLength=" + petalLength +
", petalWidth=" + petalWidth +
", type='" + type + '\'' +
'}';
}
}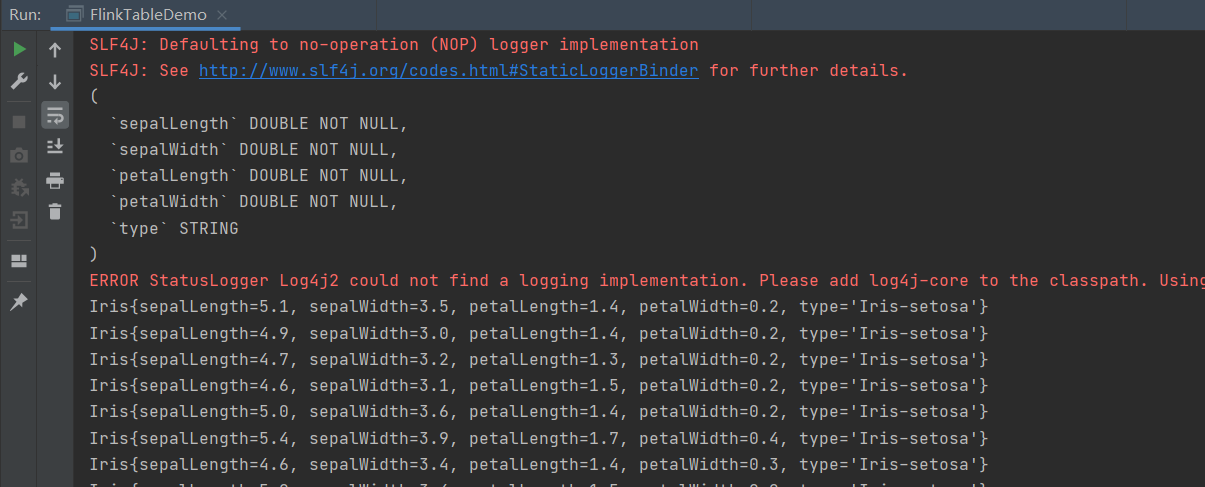
已经成功读取到本地的文件,注意对于Flink中是用lamda的时候最好是声明数据返回类型是什么,否则可能出现报错。这里使用了toAppendStream追加流,数据不存在更新只追加的情况下使用。
样例2
求出数据集的某一最大项数值是多少。
package com.hph.app;
import com.hph.bean.Iris;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import static org.apache.flink.table.api.Expressions.$;
public class FlinkTableAggregateDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
DataStreamSource<String> dataSource = env.readTextFile("D:\\data\\iris.csv");
SingleOutputStreamOperator<Iris> map = dataSource.map(x -> {
String[] words = x.split(",");
return new Iris(Double.valueOf(words[0]), Double.valueOf(words[1]), Double.valueOf(words[2]), Double.valueOf(words[3]), words[4]);
}).returns(Iris.class);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
Table table = tableEnv.fromDataStream(map);
Table maxTable = table.groupBy($("type"))
.aggregate($("sepalLength").max().as("maxLength"))
.select($("type"), $("maxLength"));
DataStream<Tuple2<Boolean, Row>> rowDataStream = tableEnv.toRetractStream(maxTable, Row.class);
rowDataStream.print();
env.execute("job");
}
}
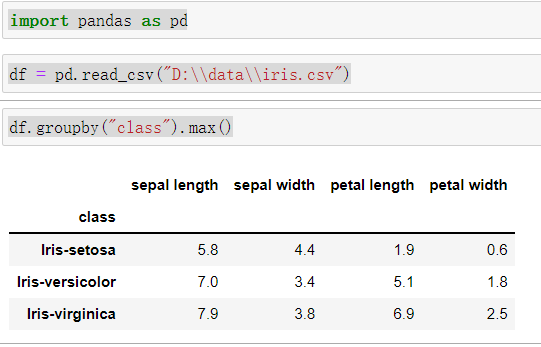
从图中结果来看Iris-setosa 类型的 sepalLength最大值为 5.8,Iris-versicolor为 7.0,Iris-virginica 为7.9,
通过Pandas分分析得出结果我们可以得知Flink得出了正确的结果,撤回流主要应用在存在数值更新的情况下。因此我们在这种情况下使用的是撤回流。
样例3
package com.hph.app;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.descriptors.FileSystem;
import org.apache.flink.table.descriptors.OldCsv;
import org.apache.flink.table.descriptors.Schema;
import org.apache.flink.types.Row;
public class FlinkTableFileSource {
public static void main(String[] args) throws Exception {
//创建运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//指定schema
Schema schema = new Schema()
.field("sepalLength", DataTypes.DOUBLE())
.field("sepalWidth", DataTypes.DOUBLE())
.field("petalLength", DataTypes.DOUBLE())
.field("petalWidth", DataTypes.DOUBLE())
.field("type", DataTypes.STRING());
//读取CSV文件创建临时表
tableEnv.connect(new FileSystem().path("D:\\data\\iris.csv"))
.withFormat(new OldCsv().ignoreFirstLine().fieldDelimiter(",").lineDelimiter("\n"))
.withSchema(schema)
.createTemporaryTable("tmp");
//TABLE api 读取数据
Table tmp = tableEnv.from("tmp");
//append流
DataStream<Row> resultDataStream = tableEnv.toAppendStream(tmp, Row.class);
resultDataStream.print();
env.execute("FileSourceTableJob");
}
}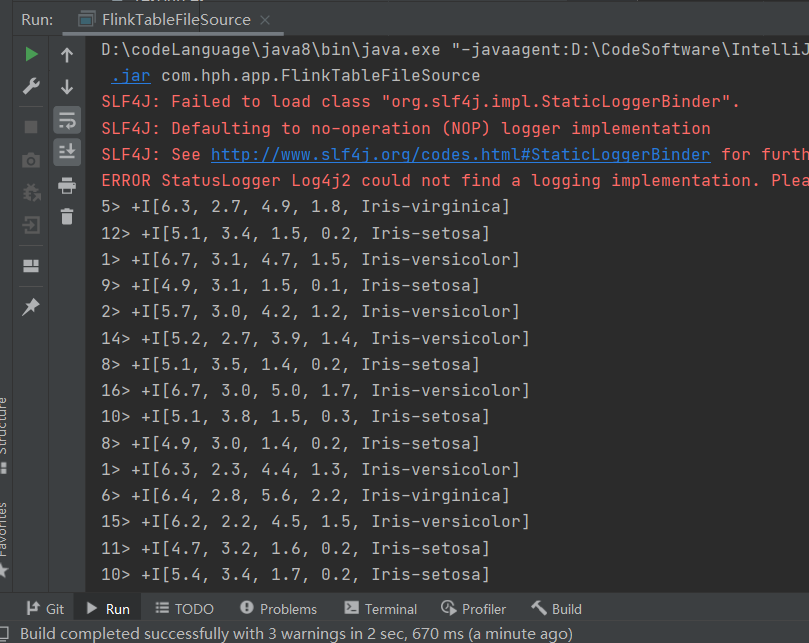
数据是并行化读取的,这个默认的并行度为CPU的个数。
样例4
读取kafka中的数据使用Table api
package com.hph.producer;
import com.google.gson.Gson;
import com.hph.bean.Iris;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.util.LinkedList;
import java.util.List;
import java.util.Properties;
public class NewProducer {
public static void main(String[] args) throws IOException {
Properties props = new Properties();
// Kafka服务端的主机名和端口号
props.put("bootstrap.servers", "hadoop102:9092,hadoop103:9092,hadoop104:9092");
// 等待所有副本节点的应答
props.put("acks", "all");
// 消息发送最大尝试次数
props.put("retries", 0);
// 一批消息处理大小
props.put("batch.size", 16384);
// 请求延时
props.put("linger.ms", 1);
// 发送缓存区内存大小
props.put("buffer.memory", 33554432);
// key序列化
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// value序列化
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Gson gson = new Gson();
Producer<String, String> producer = new KafkaProducer<>(props);
List<Iris> irises = readCsvToJson();
for (Iris iris : irises) {
String irisJson = gson.toJson(iris);
producer.send(new ProducerRecord<String, String>("iris", irisJson));
}
producer.close();
}
private static List<Iris> readCsvToJson() throws IOException {
BufferedReader reader = new BufferedReader(new FileReader("D:\\data\\iris.csv"));
LinkedList<Iris> list = new LinkedList<>();
String line = null;
while ((line = reader.readLine()) != null) {
if (!line.contains("sepal length")) {
String words[] = line.split(",");//CSV格式文件为逗号分隔符文件,这里根据逗号切分
Iris iris = new Iris(Double.valueOf(words[0]), Double.valueOf(words[1]), Double.valueOf(words[2]), Double.valueOf(words[3]), words[4]);
list.add(iris);
}
}
return list;
}
}Flink Table API消费 Kafka中的数据。

虽然Flink Table API已经简化了Flink编程的难度,但是依旧还是比较繁琐。后面会重点介绍Flink SQL。
总结
Flink Table API 和 SQL 是流批统一的 API, 在批式输入还是无限的流式输入下,都具有相同的语义。因为传统的关系代数以及 SQL 最开始都是为了批式处理而设计的,关系型查询在流式场景下不如在批式场景下容易懂。
动态表
SQL和关系代数设计时针对的是有限数据集合的概念,未考虑流式数据。
下表比较了传统的关系代数和流处理与输入数据、执行和输出结果的关系。
| 关系代数 | 流处理 |
|---|---|
| 关系 (或表) 是有界 (多) 元组集合 | 流是一个无限元组序列 |
| 对批数据 (例如关系数据库中的表) 执行 的查询可以访问完整的输入数据 | 流式查询在启动时不能访问所有数据,必须“等待”数据流入 |
| 批处理查询在产生固定大小的结果后终止 | 流查询不断地根据接收到的记录更新其结果,并且始终不会结束 |
尽管存在这些差异,但是使用关系查询和 SQL 处理流并不是不可能的。高级关系数 据库系统提供了一个称为物化视图 (Materialized Views) 的特性。物化视图被定义为一条流式概念 SQL 查询,就像常规的虚拟视图一样。与虚拟视图相反,物化视图缓存查询的结果,因此在访问视图时不需要对查询进行计算。缓存的一个常见难题是防止缓存为过期的结果提供服务。当其定义查询的基表被修改时,物化视图将过期。即时视图维护 (Eager View Maintenance) 是一种一旦更新了物化视图的基表就立即更新视图的技术。
对此视图的维护和SQL查询之间联系如下:
数据库表是 INSERT、UPDATE 和 DELETE DML 语句的 stream 的结果,通常称为 changelog stream 。
物化视图被定义为一条 SQL 查询。为了更新视图,查询不断地处理视图的基本关 系的 changelog 流。
物化视图是流式 SQL 查询的结果。
动态表是 Flink 的支持流数据的 Table API 和 SQL 的核心概念。与表示批处理数据的静态表不同,动态表是随时间变化的。可以像查询静态批处理表一样查询它们。查询动态表将生成一个连续查询。一个连续查询永远不会终止,结果会生成一个动态表。查询不断更新其 (动态) 结果表,以反映其 (动态) 输入表上的更改。本质上,动态表上的连续查询非常类似于定义物化视图的查询。连续查询的结果在语义上总是等价于以批处理模式在输入表快照上执行的相同查询的结果。
下图显示了流、动态表和连续查询之间的关系:

为了使用SQL查询处理流,必须将其转换成 Table。流的每条记录都被解释为对结果表的 INSERT 操作。本质上我们正在从一个 INSERT-only 的 changelog 流构建表。
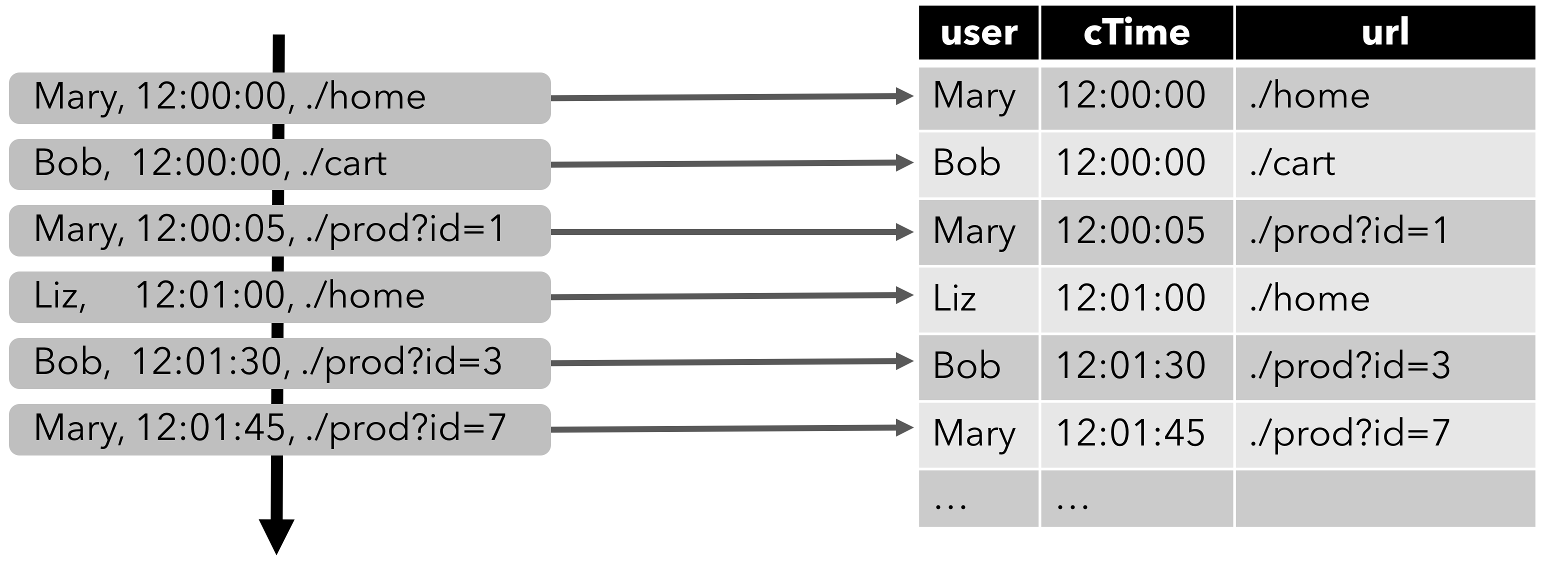
与批处理查询不同,连续查询从不终止,并根据其输入表上的更新更新结果表。在任何时候,连续查询的结果在语义上与以批处理模式在输入表快照上执行的相同查询的结果相同。
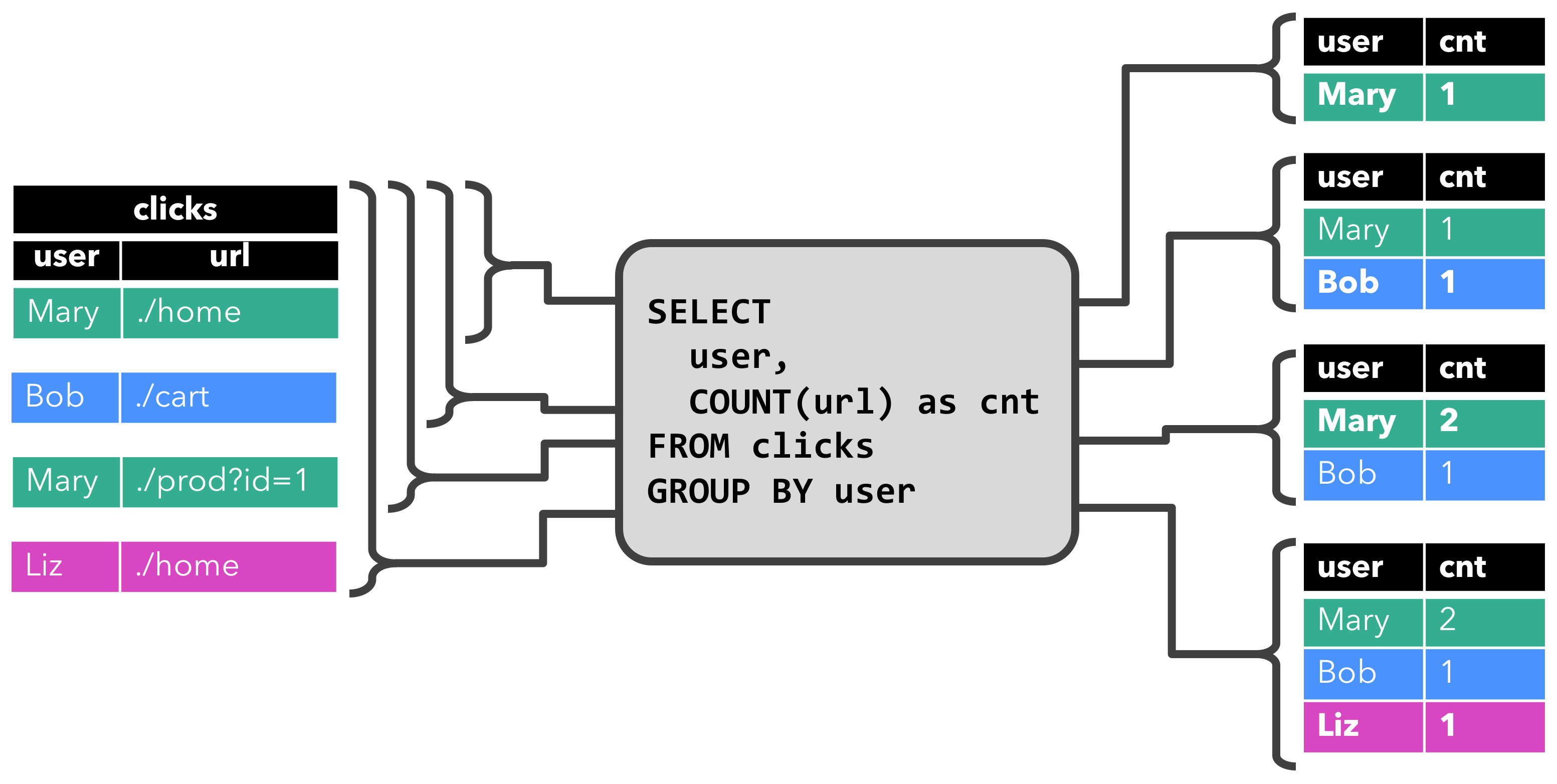
上图基于user 字段对 clicks 表进行分组,并统计访问的 URL 的数量。
查询开始,clicks 表(左侧)是空的。当第一行数据被插入到 clicks 表时,查询开始计算结果表。第一行数据 [Mary,./home] 插入后,结果表(右侧,上部)由一行 [Mary, 1] 组成。当第二行 [Bob, ./cart] 插入到 clicks 表时,查询会更新结果表并插入了一行新数据 [Bob, 1]。第三行 [Mary, ./prod?id=1] 将产生已计算的结果行的更新,[Mary, 1] 更新成 [Mary, 2]。最后,当第四行数据加入 clicks 表时,查询将第三行 [Liz, 1] 插入到结果表中。
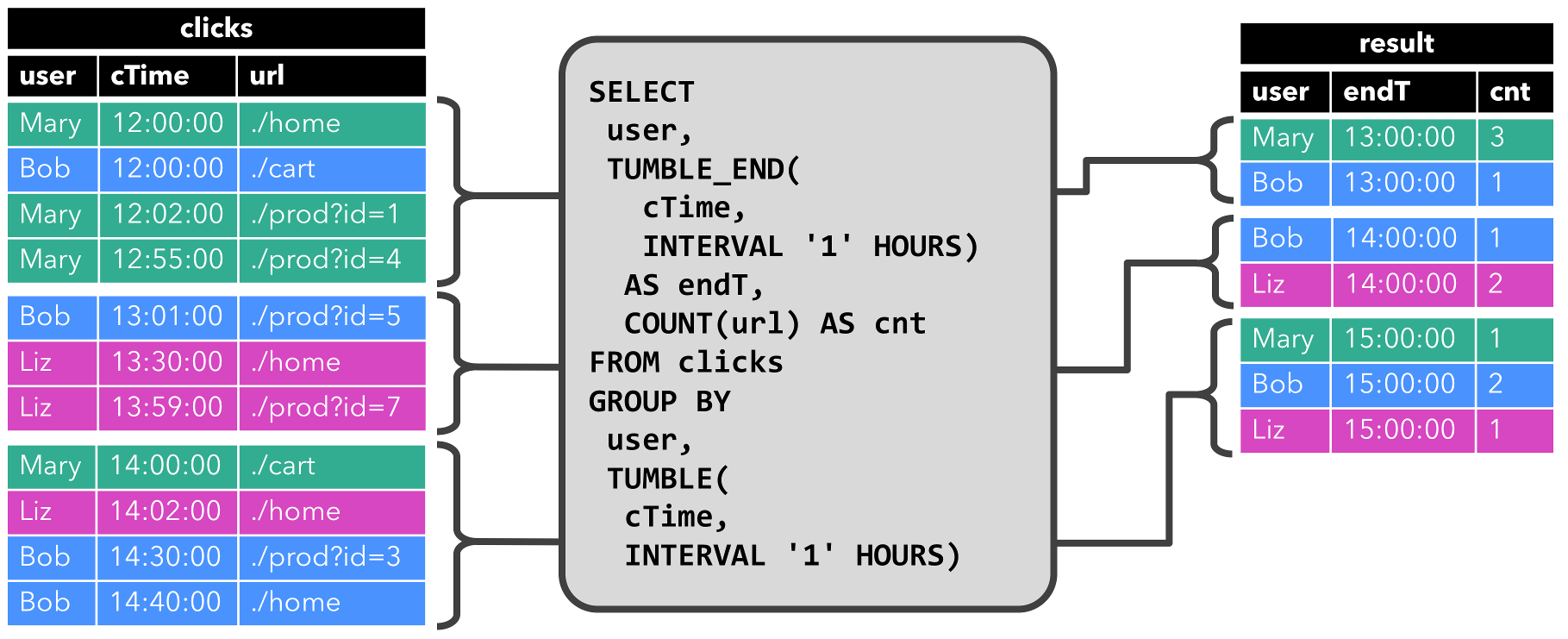
上图查询和图1基本类似,但是除了用户属性之外,还将 clicks 分组至每小时滚动窗口中,然后计算 url 数量。
表到流的转换
- Append-only 流: 仅通过
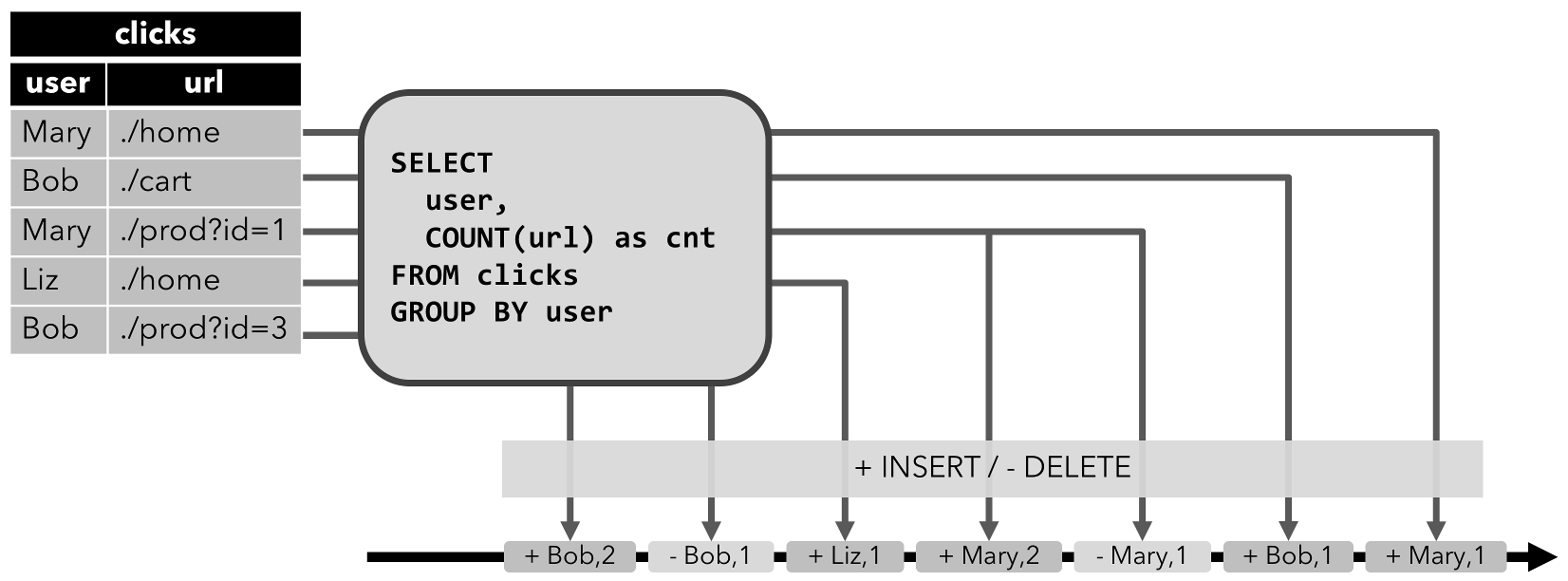
INSERT操作修改的动态表可以通过输出插入的行转换为流。 - Retract 流: retract 流包含两种类型的 message: add messages 和 retract messages 。通过将
INSERT操作编码为 add message、将DELETE操作编码为 retract message、将UPDATE操作编码为更新(先前)行的 retract message 和更新(新)行的 add message,将动态表转换为 retract 流。下图显示了将动态表转换为 retract 流的过程。
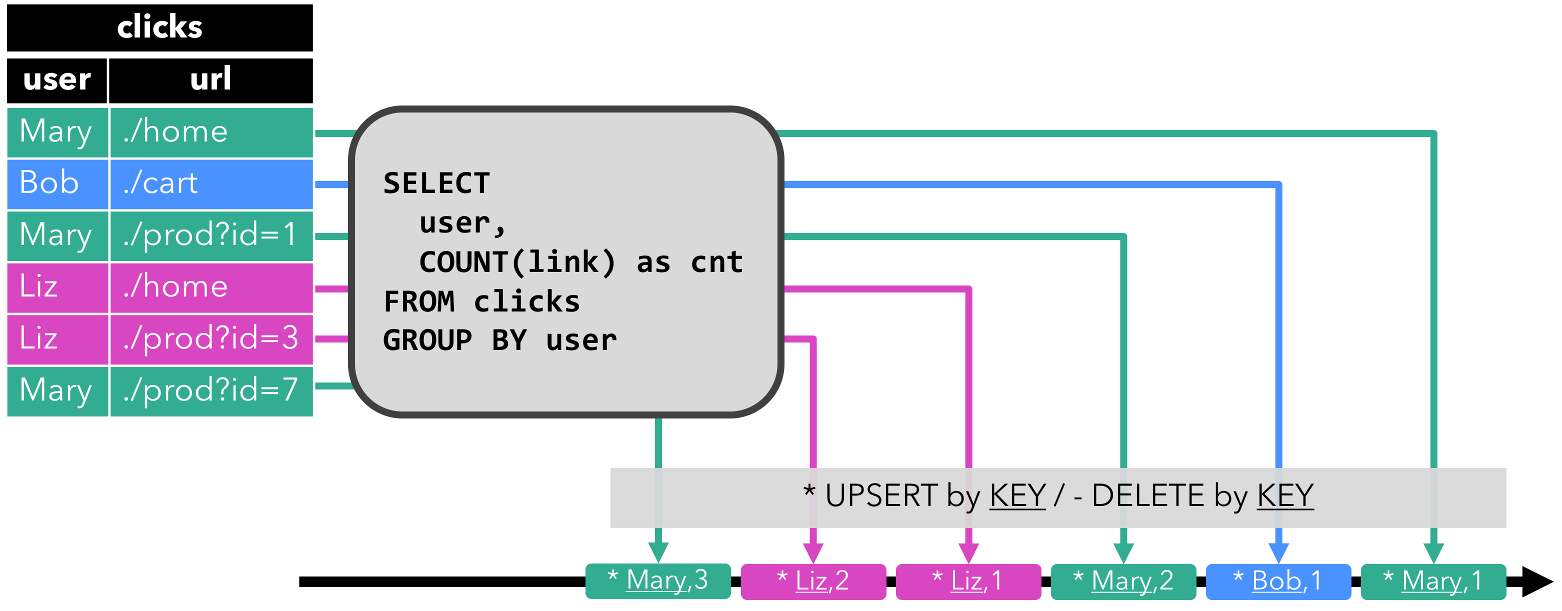
- Upsert 流: upsert 流包含两种类型的 message: upsert messages 和delete messages。转换为 upsert 流的动态表需要(可能是组合的)唯一键。通过将
INSERT和UPDATE操作编码为 upsert message,将DELETE操作编码为 delete message ,将具有唯一键的动态表转换为流。消费流的算子需要知道唯一键的属性,以便正确地应用 message。与 retract 流的主要区别在于UPDATE操作是用单个 message 编码的,因此效率更高。下图显示了将动态表转换为 upsert 流的过程。
注意:动态表转换为 DataStream 时,只支持 append 流和 retract 流。

