开源生态系统多个系统都在尝试多种方式来解决容错问题。容错机制的设计将对框架设计预计编程模型都有深远的影响,导致难以在现有的流式框架上类似插件机制一样扩展实现不一样的容错策略。因此,流式计算内框架时,容错策略非常重要。我们讨论一下其他的流式计算框架的容错机制
记录确认
以Apache Storm代表的Record acknowledgements
- 当前 Operator 处理完成每条记录时都会向前一个 Operator 发回针对这条记录处理过的确认。中间失败就会重新发送该记录到下游。这种机制虽然不会丢数据但是会导致重复数据的产生,会导致同一条记录被多次发送到下游进行处理,无法保证exactly-once(精确一次) ,数据的重复问题交由开发者解决,该容错机制还有一个弊端,如果出现背压,记录确认的容错方式会导致上游节点错误地认为数据处理出现了 Fail。因此Storm已经逐渐被大众所遗弃。
微批处理
以 Apache Storm Trident,Apache Spark Streaming代表的Micro batches (微批处理)
- 微批处理(离散化流)是将连续的流切分为一个个离散的、小批次的微批进行处理,将流数据收敛切分为一批一批微批的、原子的数据进行类似 Batch 的计算,如果batch的数据出现失败,对失败的一小批数据进行处理即可。
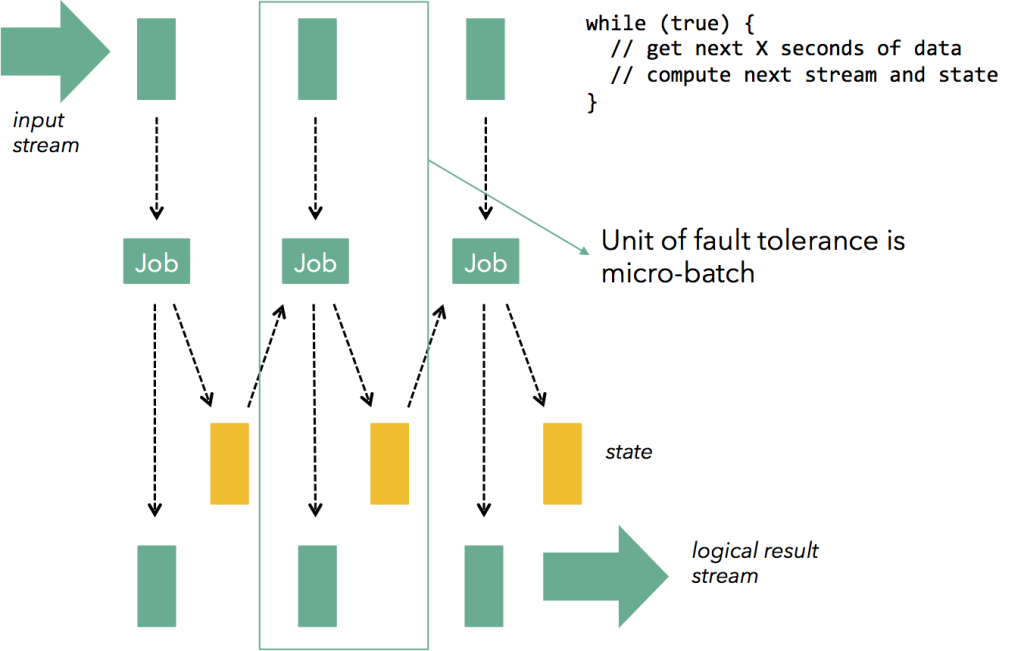
微批处理有以下缺点:
编程模型:由于微批次模型,无法使用计数或会话窗口。
流量控制:上游数据处理速度快,下游数据处理速度慢,数据内存排队等待被处理,最终会导致OOM,批次之间的时间间隔增大数据可能不精确。
延迟:微批次加大了流计算的计算延迟,需要亚秒级别的计算场景会无法解决。
总结:微批次可以实现高吞吐和一次性保证,但是丧失了低延迟,流量控制和流式变成为代价。
事务更新
以 Google Cloud Dataflow代表的Transactional updates
- 在 Google Cloud Dataflow 中实现的模型 将计算模型抽象为一次部署并长期运行持续计算的 Operator DAG。 在 Dataflow 中,数据的 shuffle 是流式的而非批模式,同时计算结果亦不需要物化 (数据的计算结果放在内存中)。 这种模型不仅解决了流式计算低延迟问题,同时还天然支持自然流量控制机制,因为 DAG 不同阶段的 Operator 之间存有中间结果的 Buffer,这些中间缓冲区可以缓解反压,直到反压恶化到最源头的 Operator,即 DataFlow Source 节点。而基于 Pull 模型的流式数据源,如 Kafka 消费者可以处理这个问题,即 Source 节点的中间结果 Buffer 会出现积压导致读取 Kafka 变慢,但不会影响上游的流数据采集。 系统还支持一套干净的流编程模型,支持复杂的窗口,同时还提供对状态的更新操作。 值得一提的是,这套流编程模型包含微批量模型。
- 这种架构中的容错设计如下:通过 Operator 的每个中间记录,和本 Operator 计算带来的状态更新,以及有本条记录派生的新记录,一起做一次原子事务并提交到事务性日志系统或者数据库系统。 在系统出现失败的情况下,之前数据库的记录将被重放,用于恢复计算的中间状态,同时将丢失没有来得及计算的数据重新读取进行计算。
分布式快照
以Apache Flink 代表的Distributed Snapshots
- 提供 exactly-once 流式处理语义保证的核心问题就是 确定当前流式计算的状态 (包括正在处理的数据,以及 Operator 状态),生成该状态的一致快照,并存储在持久存储中。如果可以经常执行状态保存的操作,则从故障恢复意味着仅从持久存储中恢复最新快照,将源头 Source 回退到快照生成时刻再次进行”播放”。
- Flink 的快照机制基于 Chandy 和 Lamport 于 1985 年设计的算法,用于生成分布式系统当前状态的一致快照,不会丢失信息且不记录重复项。 Flink 使用的是 Chandy Lamport 算法的一个变种,定期对正在运行的流拓扑的状态做快照,并将这些快照存储到持久存储(例如,存储到 HDFS 或内存中文件系统)。 这些做快照的频率是可配置的。这种做法类似于微批次做法,其中两个检查点之间的所有计算都作为一个整体原子地成功或失败。
- Chandy Lamport 算法的一个重要特点是我们永远不必按流处理中的“暂停”:全局状态检测算法应该被设计在基础 (业务) 计算之上:它必须与此基础 (业务) 计算同时并行进行,但不能侵入改变基础 (业务) 计算。
- 该架构将应用程序开发与流量控制、吞吐量控制分开。 更改快照持久化的间隔时间对流作业的结果完全没有影响,因此下游应用程序可以安全地依赖于接收正确的结果。
Flink 的检查点机制基于 stream barriers(可以理解为 Chandy Lamport 中的“标记”),这些 barrier 像正常的业务数据一样在 Operator 和 Operator 之间的数据管道中流动。Barrier 在 Source 节点中被注入到普通流数据中(如果使用 Apache Kafka 作为源,Barrier 将与 Kafka 的读取偏移对齐),并且作为数据流的一部分与数据记录一起流过下游的 DAG。 Barrier 将业务数据流分为两组:当前快照的一部分(Barrier 表示检查点的开始),以及属于下一个快照的那些组。
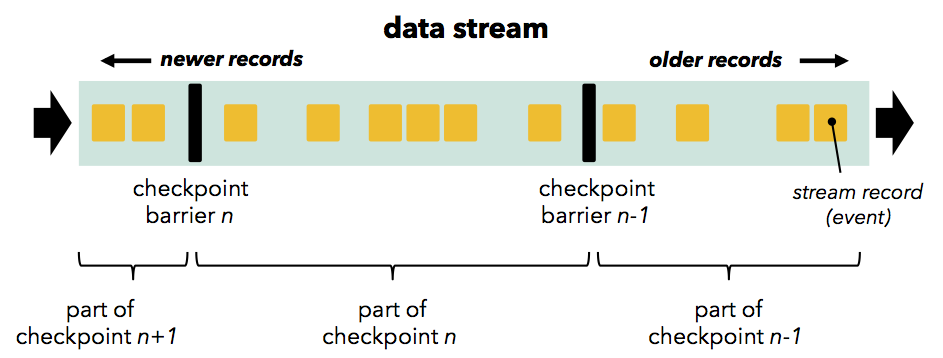
Barrier 流向下游并在通过 Operator 时触发状态快照。 Operator 首先将 Barrier 与所有传入的流分区(通常 Barrier 具有多个输入)对齐,上游来源较快的流分区将被缓冲数据以等待来源较慢的流分区。 当 Operator 从每个输入流分区都收到 Barrier 时,它会检查其状态(如果有)并写入持久存储,这个过程我们称之为状态写检查。一旦完成状态检查点,Operator 就将 Barrier 向下游转发。 请注意,在此机制中,如果 Operator 支持,则状态检查点既可以是异步(在写入状态时继续处理),也可以是增量(仅写入更改)。
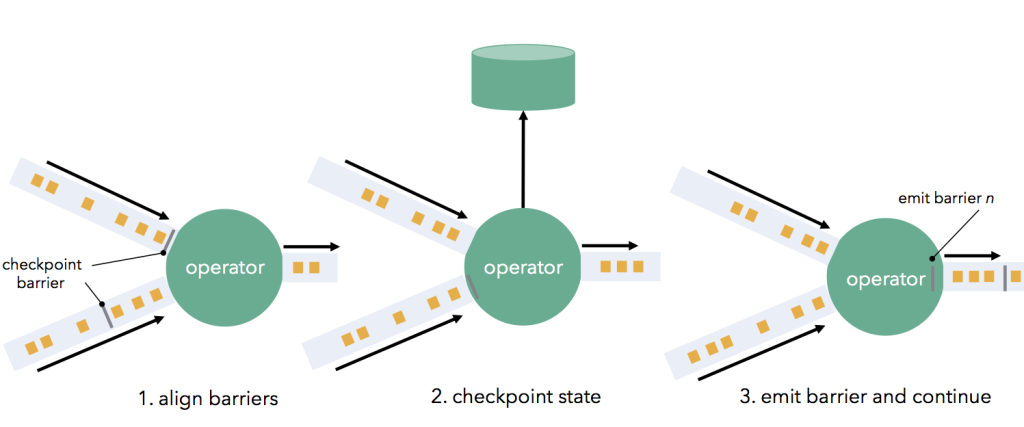
一旦所有数据写出端 (即 Flink Sink 节点) 都收到 Barrier,当前检查点就完成了。 故障恢复意味着只需恢复最新的检查点状态,并从最新的 Barrier 记录的偏移量重新启动 Source 节点。 分布式快照在我们在本文开头所要达到的所有需求中得分很高。 它们实现了高吞吐量、一次性保证,同时保留了连续的 Operator 模型、低延迟以及自然流量控制。
对比分析
| item | Record ACK | Micro-batching | Transactional updates | Distributed snapshots |
|---|---|---|---|---|
| 语义保证 | At least once | Exactly once | Exactly once | Exactly once |
| 延迟 | 低 | 高 | 较低 (事务延迟) | 低 |
| 吞吐 | 低 | 高 | 较高 (取决于做事务存储吞吐) | 高 |
| 计算模型 | 流 | 微批 | 流 | 流 |
| 容错开销 | 高 | 低 | 较低 (取决于事务存储的吞吐) | 低 |
| 流控 | 较差 | 较差 | 好 | 好 |
| 业务灵活性 (业务和容错分离) | 部分 | 紧耦合 | 分离 | 分离 |
Flink Checkpoint 机制
Flink Checkpoint 基于 Chandy-Lamport 算法,将分布式系统抽象成 DAG(暂时不考虑有闭环的图),节点表示进程,边表示两个进程间通信的管道。分布式快照的目的是记录下整个系统的状态,即可以分为节点的状态(进程的状态)和边的状态(信道的状态,即传输中的数据)。系统状态是由输入的消息序列驱动变化的,我们可以将输入的消息序列分为多个较短的子序列,图的每个节点或边先后处理完某个子序列后,都会进入同一个稳定的全局统状态。利用这个特性,系统的进程和信道在子序列的边界点分别进行本地快照,即使各部分的快照时间点不同,最终也可以组合成一个有意义的全局快照。

从实现上看,Flink 通过在 DAG 数据源定时向数据流注入名为 Barrier 的特殊元素,将连续的数据流切分为多个有限序列,对应多个 Checkpoint 周期。每当接收到 Barrier,算子进行本地的 Checkpoint 快照,并在完成后异步上传本地快照,同时将 Barrier 以广播方式发送至下游。当某个 Checkpoint 的所有 Barrier 到达 DAG 末端且所有算子完成快照,则标志着全局快照的成功。
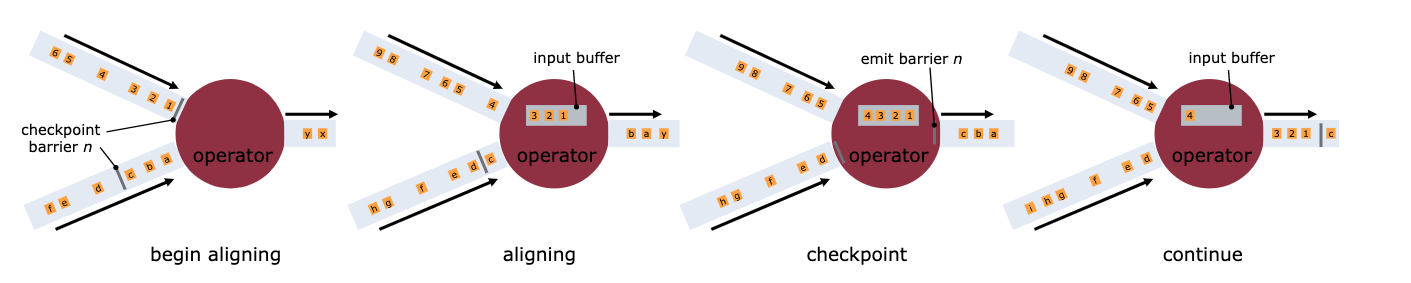
在有多个输入 Channel 的情况下,为了数据准确性,算子会等待所有流的 Barrier 都到达之后才会开始本地的快照,这种机制被称为 Barrier 对齐。在对齐的过程中,算子只会继续处理的来自未出现 Barrier Channel 的数据,而其余 Channel 的数据会被写入输入队列,直至在队列满后被阻塞。当所有 Barrier 到达后,算子进行本地快照,输出 Barrier 到下游并恢复正常处理。
比起其他分布式快照,该算法的优势在于辅以 Copy-On-Write 技术的情况下不需要 “Stop The World” 影响应用吞吐量,同时基本不用持久化处理中的数据,只用保存进程的状态信息,大大减小了快照的大小。
Checkpoint执行过程
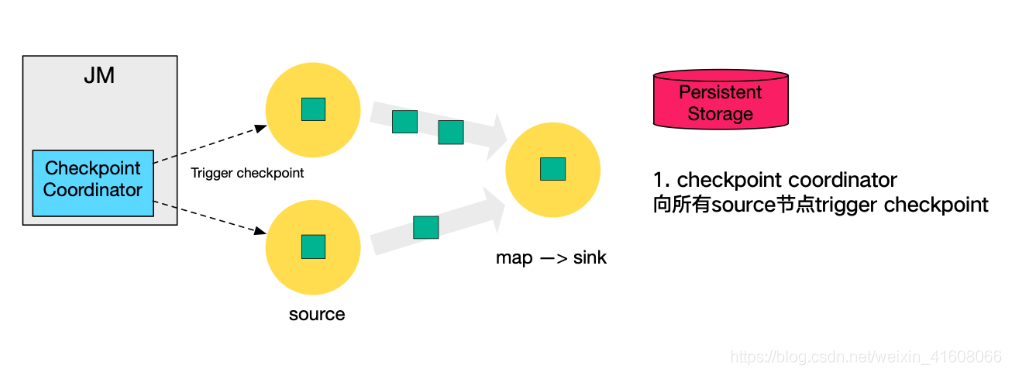
1.在JobManger中有一个Checkpoint Coordinator组件,该组件协调触发Checkpoint操作,这里的触发仅是触发Source节点的操作。
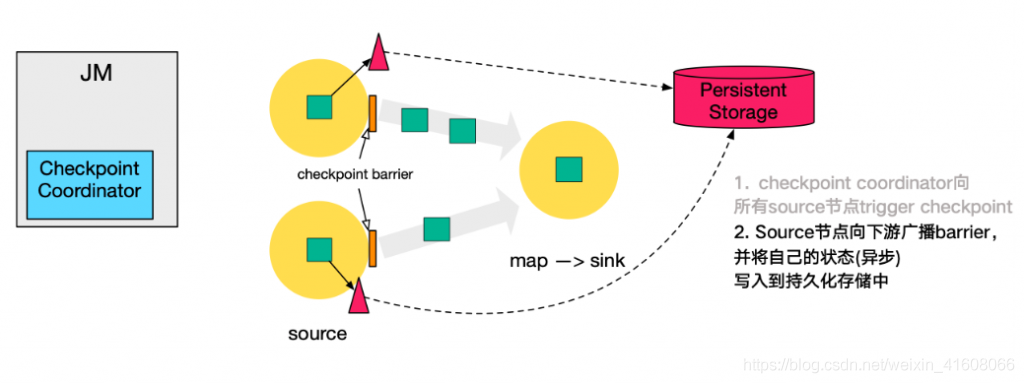
2.Source节点一旦通过Checkpoint Coordinator触发相应的Checkpoint操作,都会把内部Checkpint的数据去进行持久化操作,同时Source向下游广播barrier。他会进行一个异步的持久化过程。
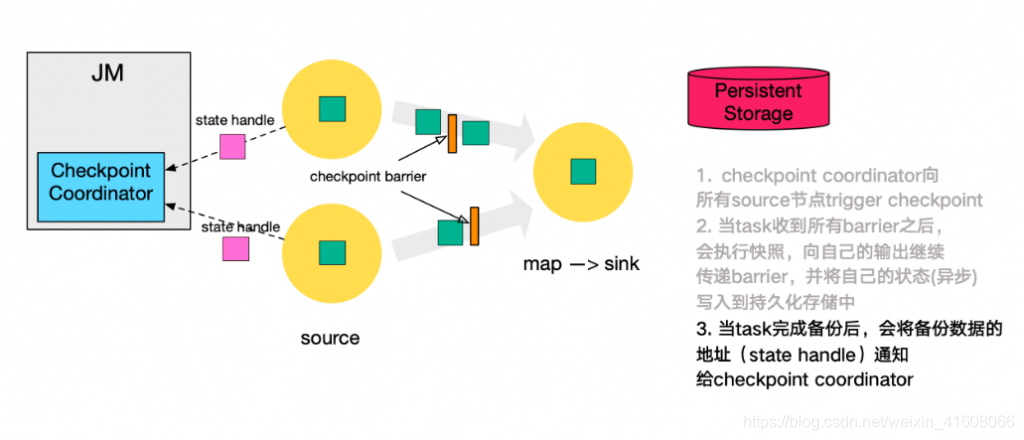
3.当Source节点snapshot完毕后,所有的数据一旦写入持久化的介质里面,会将所有的checkpoint 信息(state handle)反写到Checkpoint Coordinator,表示自己的状态已经完成持久化。
总体流程
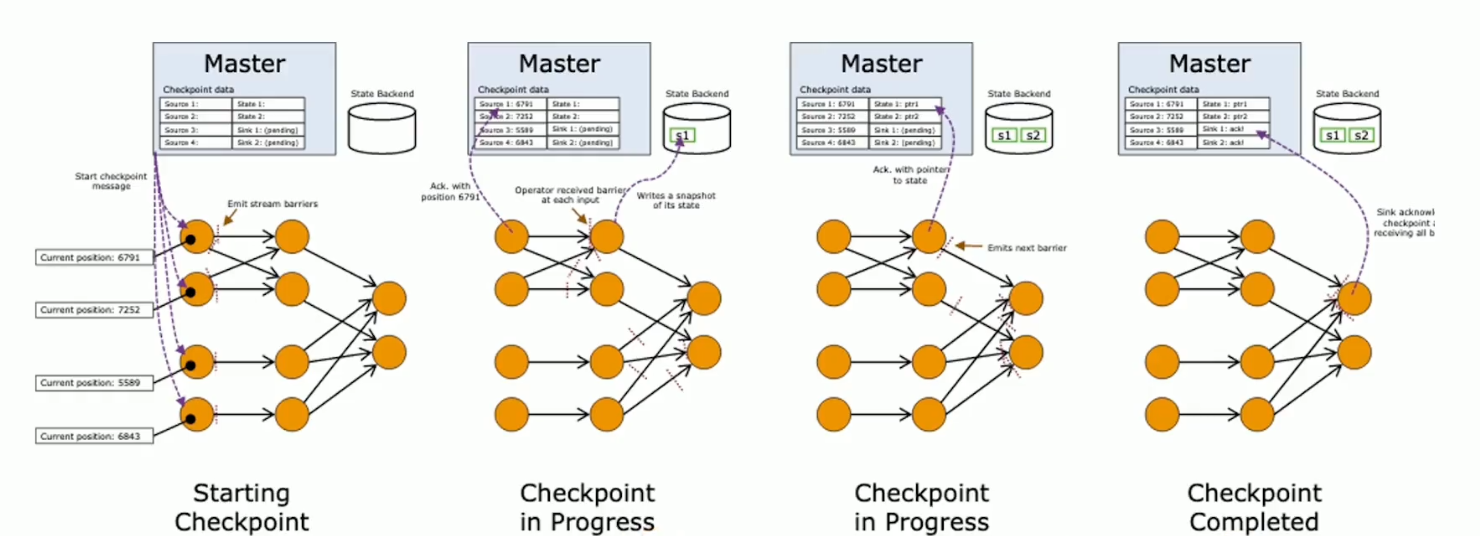
1.JobManager去触发每个Source节点的Checkpoint操作, 在每个Source注入checkpoint事件。
2.下游的算子同时接收上游算子实例的checkpoint barrier之后,完成一次对齐后,就会触发一次Checkpoint输出操作,此时将checkpoint时间输出到下游直到Sink阶段
3.Sink阶段全部接收到上游的barrier时间并做了对齐处理,这里会做一次snapshot操作,由于Sink阶段没有下游,至此完成Checkpoint,然后通知给Checkpoint Coordinator
Barrier
从字面意思,check Barrier叫做栅栏,是将DataStream数据切分为不同的部分,每一部分对应一次Checkpoint,上游做一次checkpoint发送给下游,下游会在算子中做一个对齐操作,如果某一个checkpoint某一个状态出现了问题,某一个算子实例出现异常,可以通过当前的checkpoint恢复。
checkpoint Barrier Align
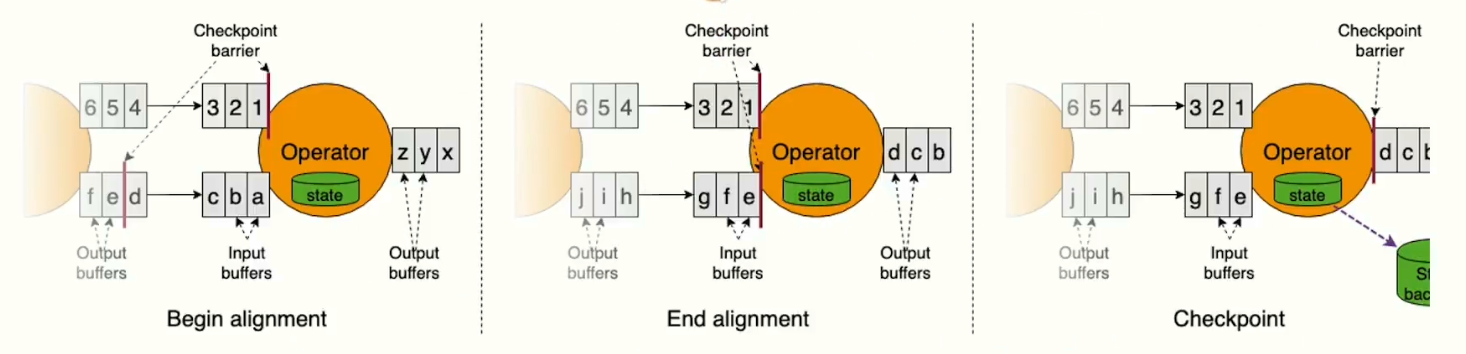
在数据处理的过程中,我们会通过Barrier进行对齐的操作,尽可能保证checkpoint的数据一致性,一旦对齐完成后触发checkpoint写操作。
Unaligned Checkpointing
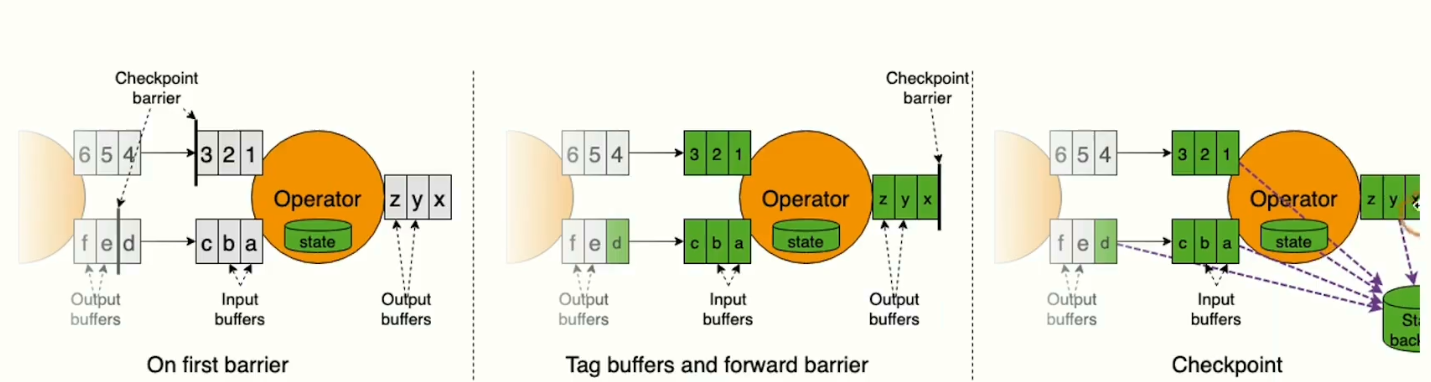
一般而言Checkpoint的写操作都是通过异步的snapshot操作去完成Checkpoint的触发流程,这个过程中,在对齐Barrier的过程中,数据不会在算子里面继续处理,仅对于上游算子来说,发送到下游的数据是一个阻塞的过程,在aligned对齐的过程中,数据流仅仅会在当前的Operator进行一个Block的操作,需要等待其他事件流的数据,当两个Barrier的数据全部到达后才会触发一次写操作,再去把数据发送给下游。如果checkpoint的数据量比较大的情况下,会导致整个作业的处理性能下降。
在Flink1.11中引入了 Unaligned Checkpointting,主要解决了checkpoint中barrier对齐的过程中导致整个系统作业处理能力下降,新版Flink中Operator无需等待上下游节点的所有Operator中传递过来的barrier时间全部对齐后再去触发操作,而是继续处理数据,把barrier事件里面的Buffer数据进行一次缓存,缓存的过程之中所有的,Barrier对齐之后再把所有所有Operator中所有的数据加上已经发送出的的一些状态数据(已在checkpoint中存储),然后需要我们对需要进行合并的一些数据进行状态合并在写道state backend 里面。
对比
比起 Aligned Checkpoint 中不同 Checkpoint 周期的数据以算子快照为界限分隔得很清晰,Unaligned Checkpoint 进行快照和输出 Barrier 时,部分本属于当前 Checkpoint 的输入数据还未计算(因此未反映到当前算子状态中),而部分属于当前 Checkpoint 的输出数据却落到 Barrier 之后(因此未反映到下游算子的状态中)。这也正是 Unaligned 的含义: 不同 Checkpoint 周期的数据没有对齐,包括不同输入 Channel 之间的不对齐,以及输入和输出间的不对齐。而这部分不对齐的数据会被快照记录下来,以在恢复状态时重放。换句话说,从 Checkpoint 恢复时,不对齐的数据并不能由 Source 端重放的数据计算得出,同时也没有反映到算子状态中,但因为它们会被 Checkpoint 恢复到对应 Channel 中,所以依然能提供只计算一次的准确结果。
当然,Unaligned Checkpoint 并不是百分百优于 Aligned Checkpoint,它会带来的已知问题就有:
- 由于要持久化缓存数据,State Size 会有比较大的增长,磁盘负载会加重。
- 随着 State Size 增长,作业恢复时间可能增长,运维管理难度增加。
目前看来,Unaligned Checkpoint 更适合容易产生高反压同时又比较重要的复杂作业。对于像数据 ETL 同步等简单作业,更轻量级的 Aligned Checkpoint 显然是更好的选择。
总结
Flink 1.11 的 Unaligned Checkpoint 主要解决在高反压情况下作业难以完成 Checkpoint 的问题,同时它以磁盘资源为代价,避免了 Checkpoint 可能带来的阻塞,有利于提升 Flink 的资源利用率。随着流计算的普及未来的 Flink 应用大概会越来越复杂,在未来经过实战打磨完善后 Unaligned Checkpoint 很有可能会取代 Aligned Checkpoint 成为 Flink 的默认 Checkpoint 策略。
参考资料
High-throughput, low-latency, and exactly-once stream processing with Apache Flink™
Flink 1.11 Unaligned Checkpoint 解析
极客时间

