Sink是经历了转换操作之后的结果数据集,这种结果数据集需要传输或存储到校友的消息中间件内。Flink中将DataStream输出到外部的系统的过程称为DataSink操作,默认支持的有Kafka,Cassandra、ElasticSearch、HDFS、RabbitMQ、NIFI等。利用 Apache Bahir可以将数据写入到Activice MQ、Flume、Redis、Akka、Netty等三方系统中,当然我们也可以自定义Sink写入到我们想要写入的三方系统中。
KafkaSink
KafkaSink相对来说比较简单,只需要读取数据,经过ETL处理数据后,添加到相对应的Topic即可。
/**
* @Classname KafkaSink
* @Description TODO
* @Date 2020/8/9 16:38
* @Created by hph
*/
package com.hph.sink;
import com.google.gson.Gson;
import com.hph.bean.OrderBean;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer011;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer010;
import org.apache.kafka.clients.producer.KafkaProducer;
import java.util.Properties;
public class KafkaSink {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
Properties props = new Properties();
//指定kafka的Broker地址
props.setProperty("bootstrap.servers", "hadoop102:9092,hadoop103:9092,hadoop104:9092");
//设置组ID
props.setProperty("group.id", "flink");
props.setProperty("auto.offset.reset", "earliest");
//kafka自动提交偏移量,
props.setProperty("enable.auto.commit", "false");
// key序列化
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// value序列化
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
DataStreamSource<String> order = environment.addSource(new FlinkKafkaConsumer<>(
"Order_Reduce",
new SimpleStringSchema(),
props
));
order.addSink(new FlinkKafkaProducer010<String>(
//添加KafkaBroker
"hadoop102:9092,hadoop103:9092,hadoop104:9092",
//指定topic
"kafkaSink",
//指定Schema
new SimpleStringSchema()
));
environment.execute("KafkaSink Demo");
}
}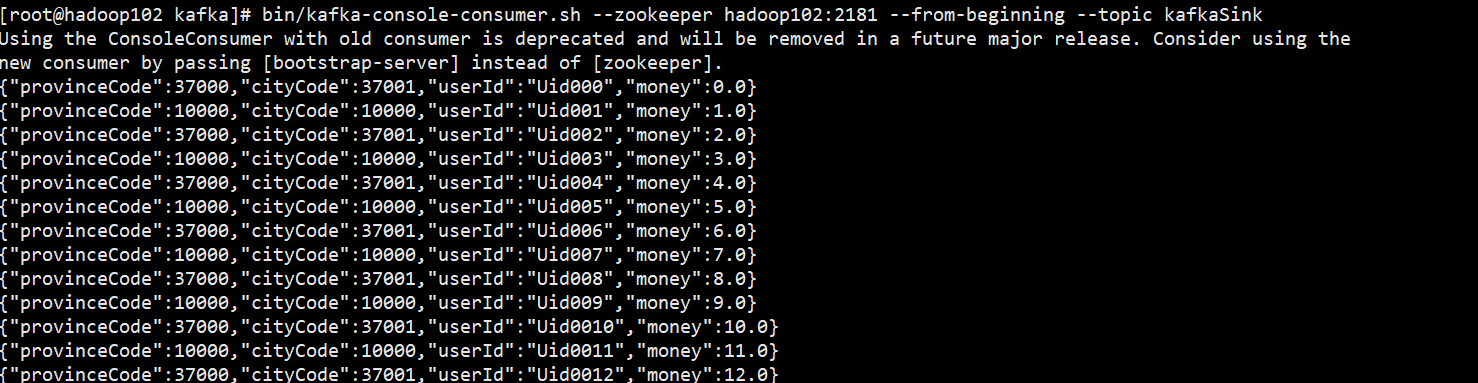
通过消费KafkaSink这个Topic里面的数据我们发现数据已经成功写入。
RabbitMQ
RabbitMQ和Kafka的sink基本也类似。值得注意的是RabbitMQ需要设置一个用户允许我们写入并访问。
/**
* @Classname RabbitMQSINK
* @Description TODO
* @Date 2020/8/9 17:20
* @Created by hph
*/
package com.hph.sink;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.rabbitmq.RMQSink;
import org.apache.flink.streaming.connectors.rabbitmq.common.RMQConnectionConfig;
import java.util.Properties;
public class RabbitMQSink {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
Properties props = new Properties();
//指定kafka的Broker地址
props.setProperty("bootstrap.servers", "hadoop102:9092,hadoop103:9092,hadoop104:9092");
//设置组ID
props.setProperty("group.id", "flink");
props.setProperty("auto.offset.reset", "earliest");
//kafka自动提交偏移量,
props.setProperty("enable.auto.commit", "false");
// key序列化
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// value序列化
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
DataStreamSource<String> order = environment.addSource(new FlinkKafkaConsumer<>(
"Order_Reduce",
new SimpleStringSchema(),
props
));
//指定RabbitMQ相关配置
RMQConnectionConfig rmqConnectionConfig = new RMQConnectionConfig.Builder().setHost("hadoop102").setVirtualHost("/").setPort(5672).setUserName("test").setPassword("123456").build();
order.addSink(new RMQSink<>(rmqConnectionConfig,
"RabbitSink",
new SimpleStringSchema()));
environment.execute("RabbitSink");
}
}再次查看web界面,数据已经写入。
通过Queues查看数据
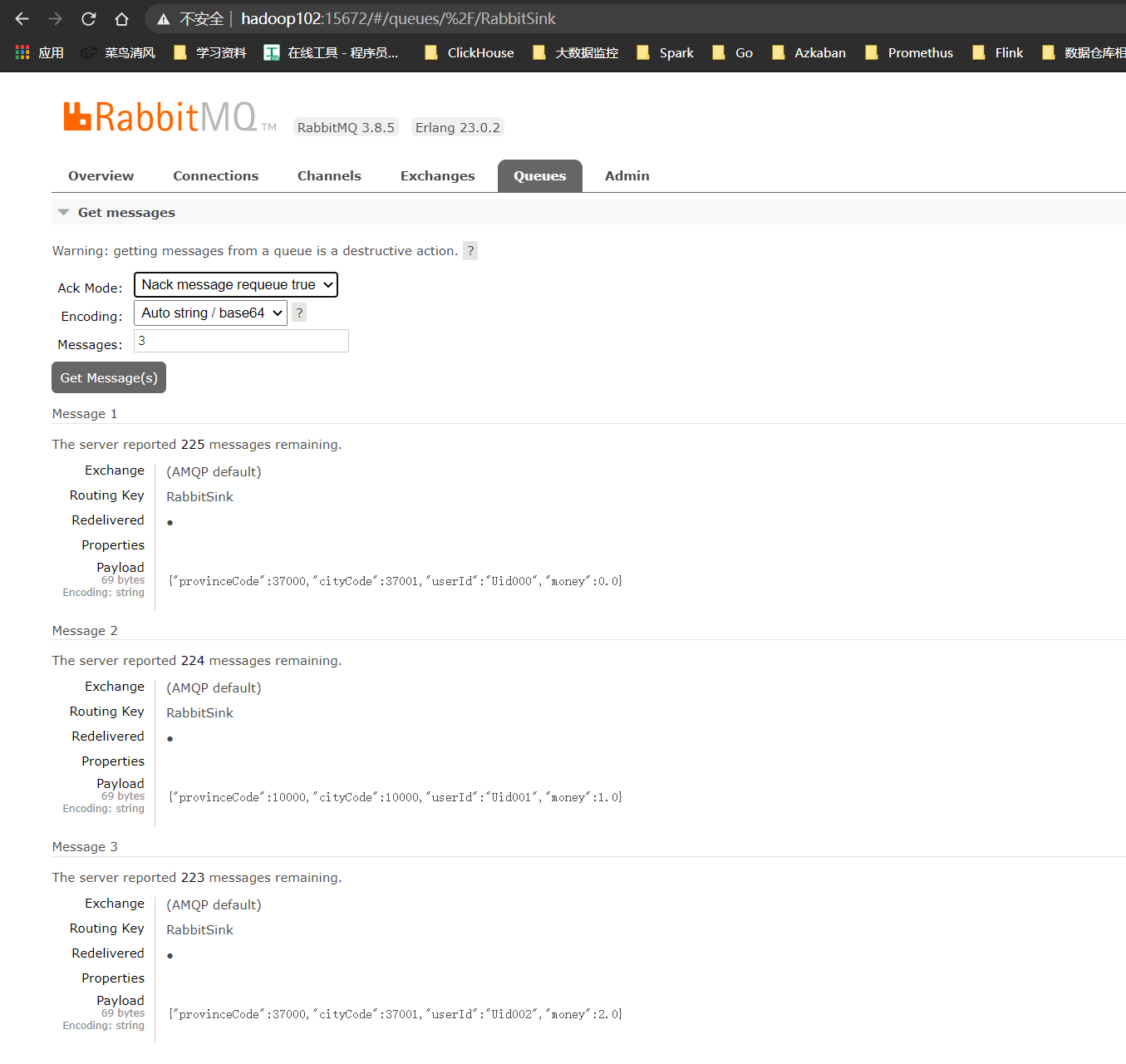
数据写入OK。
ElasticSearchSink
Flink对Elasticsearch有相应的连接器,如果需要ElasticSearch的连接器,那么就需要将其依赖导入。
| Maven Dependency | Supported since | Elasticsearch version |
|---|---|---|
| flink-connector-elasticsearch5_2.11 | 1.3.0 | 5.x |
| flink-connector-elasticsearch6_2.11 | 1.6.0 | 6.x |
| flink-connector-elasticsearch7_2.11 | 1.10.0 | 7 and later versions |
这里我用到的Elasticsearch为elasticsearch-6.8.10,因此我需要导入的Maven依赖应该为
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-elasticsearch6_2.11</artifactId>
<version>1.11.1</version>
</dependency>在开发的过程中遇到了问题,如图所示
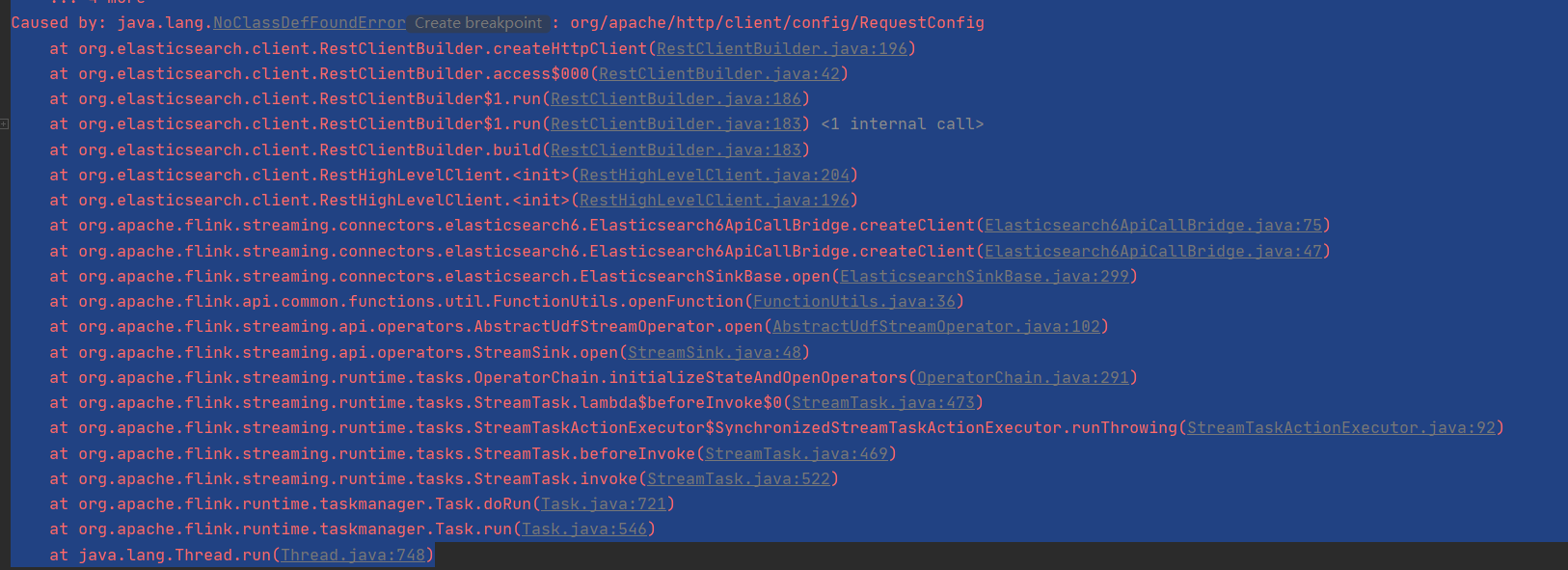
这是由于http的版本过低存在的问题,此时需要我们引入高版本的httpclient。将依赖添加至pom文件并导入。
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.10</version>
</dependency>package com.hph.sink;
import org.apache.flink.api.common.functions.RuntimeContext;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.elasticsearch.ElasticsearchSinkFunction;
import org.apache.flink.streaming.connectors.elasticsearch.RequestIndexer;
import org.apache.flink.streaming.connectors.elasticsearch.util.RetryRejectedExecutionFailureHandler;
import org.apache.flink.streaming.connectors.elasticsearch6.ElasticsearchSink;
import org.apache.flink.streaming.connectors.elasticsearch6.RestClientFactory;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.http.HttpHost;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.Requests;
import org.elasticsearch.client.RestClientBuilder;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Map;
import java.util.Properties;
public class ESsinkDemo {
public static void main(String[] args) throws Exception {
//初始化环境
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
Properties props = new Properties();
//指定kafka的Broker地址
props.setProperty("bootstrap.servers", "hadoop102:9092,hadoop103:9092,hadoop104:9092");
//设置组ID
props.setProperty("group.id", "flink");
props.setProperty("auto.offset.reset", "earliest");
//kafka自动提交偏移量,
props.setProperty("enable.auto.commit", "false");
// key序列化
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// value序列化
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
DataStreamSource<String> order = environment.addSource(new FlinkKafkaConsumer<>(
"Order_Reduce",
new SimpleStringSchema(),
props
));
ArrayList<HttpHost> httpHosts = new ArrayList<>();
httpHosts.add(new HttpHost("hadoop102", 9200, "http"));
ElasticsearchSink.Builder<String> esSinkBuilder = new ElasticsearchSink.Builder<>(
httpHosts,
new ElasticsearchSinkFunction<String>() {
public IndexRequest createIndexRequest(String element) {
Map<String, String> json = new HashMap<>();
json.put("data", element);
return Requests.indexRequest()
.index("order_from_kafka") //注意 索引必须全部为小写
.type("my-type")
.source(json);
}
@Override
public void process(String element, RuntimeContext ctx, RequestIndexer indexer) {
indexer.add(createIndexRequest(element));
}
}
);
esSinkBuilder.setBulkFlushMaxActions(1);
esSinkBuilder.setFailureHandler(new RetryRejectedExecutionFailureHandler());
order.addSink(esSinkBuilder.build());
environment.execute("elasticsearch test");
}
}
这里虽然是写入数据但是我们从查询到的结果看只是将数据写出。对查询还是有一定的影响。这里我们对这段程序改造一下。
/**
* @Classname ElasticSearchSink
* @Description TODO
* @Date 2020/8/9 18:38
* @Created by hph
*/
package com.hph.sink;
import com.google.gson.Gson;
import com.hph.bean.OrderBean;
import org.apache.flink.api.common.functions.RuntimeContext;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.elasticsearch.ElasticsearchSinkFunction;
import org.apache.flink.streaming.connectors.elasticsearch.RequestIndexer;
import org.apache.flink.streaming.connectors.elasticsearch.util.RetryRejectedExecutionFailureHandler;
import org.apache.flink.streaming.connectors.elasticsearch6.ElasticsearchSink;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.http.HttpHost;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.Requests;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Map;
import java.util.Properties;
public class ESSink {
public static void main(String[] args) throws Exception {
//初始化环境
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
Properties props = new Properties();
//指定kafka的Broker地址
props.setProperty("bootstrap.servers", "hadoop102:9092,hadoop103:9092,hadoop104:9092");
//设置组ID
props.setProperty("group.id", "flink");
props.setProperty("auto.offset.reset", "earliest");
//kafka自动提交偏移量,
props.setProperty("enable.auto.commit", "false");
// key序列化
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// value序列化
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
DataStreamSource<String> order = environment.addSource(new FlinkKafkaConsumer<>(
"Order_Reduce",
new SimpleStringSchema(),
props
));
ArrayList<HttpHost> httpHosts = new ArrayList<>();
httpHosts.add(new HttpHost("hadoop102", 9200, "http"));
Gson gson = new Gson();
ElasticsearchSink.Builder<String> esSinkBuilder = new ElasticsearchSink.Builder<>(
httpHosts,
new ElasticsearchSinkFunction<String>() {
public IndexRequest createIndexRequest(String element) {
OrderBean orderBean = gson.fromJson(element, OrderBean.class);
Map<String, String> json = new HashMap<>();
json.put("province_code", String.valueOf(orderBean.getProvinceCode()));
json.put("city_code", String.valueOf(orderBean.getCityCode()));
json.put("user_id", String.valueOf(orderBean.getUserId()));
json.put("money", String.valueOf(orderBean.getMoney()));
return Requests.indexRequest()
.index("order_from_kafka")
.type("my-type")
.source(json);
}
@Override
public void process(String element, RuntimeContext ctx, RequestIndexer indexer) {
indexer.add(createIndexRequest(element));
}
}
);
esSinkBuilder.setBulkFlushMaxActions(1);
esSinkBuilder.setFailureHandler(new RetryRejectedExecutionFailureHandler());
order.addSink(esSinkBuilder.build());
environment.execute("elasticsearch test");
}
}
这个问题主要是Gson为非序列化的对象,我们把Gson放到ElasticsearchSinkFunction中即可解决问题。
/**
* @Classname ElasticSearchSink
* @Description TODO
* @Date 2020/8/9 18:38
* @Created by hph
*/
package com.hph.sink;
import com.google.gson.Gson;
import com.hph.bean.OrderBean;
import org.apache.flink.api.common.functions.RuntimeContext;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.elasticsearch.ElasticsearchSinkFunction;
import org.apache.flink.streaming.connectors.elasticsearch.RequestIndexer;
import org.apache.flink.streaming.connectors.elasticsearch.util.RetryRejectedExecutionFailureHandler;
import org.apache.flink.streaming.connectors.elasticsearch6.ElasticsearchSink;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.http.HttpHost;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.Requests;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Map;
import java.util.Properties;
public class ESSink {
public static void main(String[] args) throws Exception {
//初始化环境
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
Properties props = new Properties();
//指定kafka的Broker地址
props.setProperty("bootstrap.servers", "hadoop102:9092,hadoop103:9092,hadoop104:9092");
//设置组ID
props.setProperty("group.id", "flink");
props.setProperty("auto.offset.reset", "earliest");
//kafka自动提交偏移量,
props.setProperty("enable.auto.commit", "false");
// key序列化
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// value序列化
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
DataStreamSource<String> order = environment.addSource(new FlinkKafkaConsumer<>(
"Order_Reduce",
new SimpleStringSchema(),
props
));
ArrayList<HttpHost> httpHosts = new ArrayList<>();
httpHosts.add(new HttpHost("hadoop102", 9200, "http"));
ElasticsearchSink.Builder<String> esSinkBuilder = new ElasticsearchSink.Builder<>(
httpHosts,
new ElasticsearchSinkFunction<String>() {
public IndexRequest createIndexRequest(String element) {
Gson gson = new Gson();
OrderBean orderBean = gson.fromJson(element, OrderBean.class);
Map<String, String> json = new HashMap<>();
json.put("province_code", String.valueOf(orderBean.getProvinceCode()));
json.put("city_code", String.valueOf(orderBean.getCityCode()));
json.put("user_id", String.valueOf(orderBean.getUserId()));
json.put("money", String.valueOf(orderBean.getMoney()));
return Requests.indexRequest()
.index("order_from_kafka")
.type("my-type")
.source(json);
}
@Override
public void process(String element, RuntimeContext ctx, RequestIndexer indexer) {
indexer.add(createIndexRequest(element));
}
}
);
esSinkBuilder.setBulkFlushMaxActions(1);
esSinkBuilder.setFailureHandler(new RetryRejectedExecutionFailureHandler());
order.addSink(esSinkBuilder.build());
environment.execute("elasticsearch test");
}
}ElasticSearch将kafka数据写入成功到es。

在Flink中,开启Checkpoint,可以确保请求至少一次传递给Elasticsearch集群,Flink通过在检查点时等待BulkProcessor中所有未决的操作请求来实现。确保了了在继续处理发送到elasticsearch的更多记录之前,Elasticsearch已成功确认触发检查点之前的所有请求。开启checkpoint代码比较简单
env.enableCheckpointing(5000); // 每5s做一次checkpoint在Flink中Elasticsearch操作请求可能由于各种原因而失败,包括临时饱和的节点队列容量或要编制索引的文档格式错误。 Flink Elasticsearch Sink允许用户通过简单地实现ActionRequestFailureHandler并将其提供给构造函数来指定如何处理请求失败。可以通过setFailureHandler设置容错处理
esSinkBuilder.setFailureHandler(new ActionRequestFailureHandler() {
@Override
public void onFailure(ActionRequest action, Throwable failure, int restStatusCode, RequestIndexer indexer) throws Throwable {
if (ExceptionUtils.findThrowable(failure, EsRejectedExecutionException.class).isPresent()) {
// 重新添加文档以建立索引
indexer.add(action);
} else if (ExceptionUtils.findThrowable(failure, ElasticsearchParseException.class).isPresent()) {
//文件格式错误; 只需删除请求而不会接收失败
} else {
// 其他错误
// 用户可以选择自己自定异常,或者直接抛出异常
throw failure;
}
}
});如果仅仅只是想做失败重试,可以直接使用官方提供的默认的 RetryRejectedExecutionFailureHandler ,该处理器会对 EsRejectedExecutionException 导致到失败写入做重试处理。如果你没有设置失败处理器(failure handler),那么就会使用默认的 NoOpFailureHandler 来简单处理所有的异常。
发生故障时在默认情况下,BulkProcessor最多重试8次,并采用指数补偿,将请求重新添加到内部BulkProcessor,会使检查时间点会变长,在接收器在检查点时还需要等待刷新的新请求被刷新。例如,当使用RetryRejectedExecutionFailureHandler时,检查点将需要等待,直到Elasticsearch节点队列具有足够的容量来处理所有挂起的请求。这也意味着,如果重新添加的请求永远不会成功,则检查点将永远不会完成。
在Flink内部可以进一步配置配置内部的BulkProcessor,使其刷新缓冲的动作。这部分内容主要参考了zhisheng的博客。
bulk.flush.backoff.enable #是否开启重试机制
esSinkBuilder.setBulkFlushBackoff(true);
bulk.flush.backoff.type 重试策略,有两种:EXPONENTIAL 指数型(表示多次重试之间的时间间隔按照指数方式进行增长)、CONSTANT 常数型(表示多次重试之间的
时间间隔为固定常数)
esSinkBuilder.setBulkFlushBackoffType(ElasticsearchSinkBase.FlushBackoffType.EXPONENTIAL);
esSinkBuilder.setBulkFlushBackoffType(ElasticsearchSinkBase.FlushBackoffType.CONSTANT);
bulk.flush.backoff.delay 进行重试的时间间隔
esSinkBuilder.setBulkFlushBackoffDelay(1000L);
bulk.flush.backoff.retries 失败重试的次数
esSinkBuilder.setBulkFlushBackoffRetries(8);
bulk.flush.max.actions: 批量写入时的最大写入条数
esSinkBuilder.setBulkFlushMaxActions(100);
bulk.flush.max.size.mb: 批量写入时的最大数据量
esSinkBuilder.setBulkFlushMaxSizeMb(10);
bulk.flush.interval.ms: 批量写入的时间间隔,配置后则会按照该时间间隔严格执行,无视上面的两个批量写入配置
esSinkBuilder.setBulkFlushInterval(100);Mysql
首先创建一个工具类
package com.hph.utils;
import com.alibaba.druid.pool.DruidDataSource;
import java.sql.Connection;
import java.sql.SQLException;
public class MysqlUtils {
private static DruidDataSource dataSource;
public static Connection getConnection() throws SQLException {
dataSource = new DruidDataSource();
dataSource.setDriverClassName("com.mysql.jdbc.Driver");
dataSource.setUrl("jdbc:mysql://hadoop102:3306/flinksink");
dataSource.setUsername("root");
dataSource.setPassword("000000");
//设置初始化连接数,最大连接数,最小闲置数
dataSource.setInitialSize(10);
dataSource.setMaxActive(50);
dataSource.setMinIdle(5);
//返回连接
return dataSource.getConnection();
}
}Flink写入Mysql可以通过继承RichSinkFunction,实现先关的方法写入数据。
package com.hph.sink;
import com.google.gson.Gson;
import com.hph.bean.OrderBean;
import com.hph.utils.MysqlUtils;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import java.sql.Connection;
import java.sql.PreparedStatement;
public class MysqlSqlSink extends RichSinkFunction<String> {
private PreparedStatement ps;
private Connection connection;
private int i;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
//获取数据库连接
connection = MysqlUtils.getConnection();
String sql = "insert into flinksink.order (user_id,province_code,city_code,money) values (?,?,?,?); ";
ps = connection.prepareStatement(sql);
}
@Override
public void close() throws Exception {
super.close();
//关闭并释放资源
if (connection != null) {
connection.close();
}
if (ps != null) {
ps.close();
}
}
@Override
public void invoke(String value, Context context) throws Exception {
//执行写入数据
Gson gson = new Gson();
if (i <= 100) {
OrderBean orderBean = gson.fromJson(value, OrderBean.class);
ps.setString(1, orderBean.getUserId());
ps.setInt(2, orderBean.getProvinceCode());
ps.setInt(3, orderBean.getCityCode());
ps.setDouble(4, orderBean.getMoney());
ps.addBatch();
i++;
}
//100个写入一次
if (i >= 100) {
ps.executeBatch();
i = 0;
}
}
}
主程序入口,数据已经写入成功。
/**
* @Classname MysqlSink
* @Description TODO
* @Date 2020/8/9 18:36
* @Created by hph
*/
package com.hph.sink;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.util.Properties;
public class MysqlSink {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
Properties props = new Properties();
//指定kafka的Broker地址
props.setProperty("bootstrap.servers", "hadoop102:9092,hadoop103:9092,hadoop104:9092");
//设置组ID
props.setProperty("group.id", "flink");
props.setProperty("auto.offset.reset", "earliest");
//kafka自动提交偏移量,
props.setProperty("enable.auto.commit", "false");
// key序列化
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// value序列化
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
DataStreamSource<String> order = environment.addSource(new FlinkKafkaConsumer<>(
"Order_Reduce",
new SimpleStringSchema(),
props
));
//flinksink
order.addSink(new MysqlSqlSink());
environment.execute("Flink MYSQL Sink");
}
}
我们查看一下数据库。
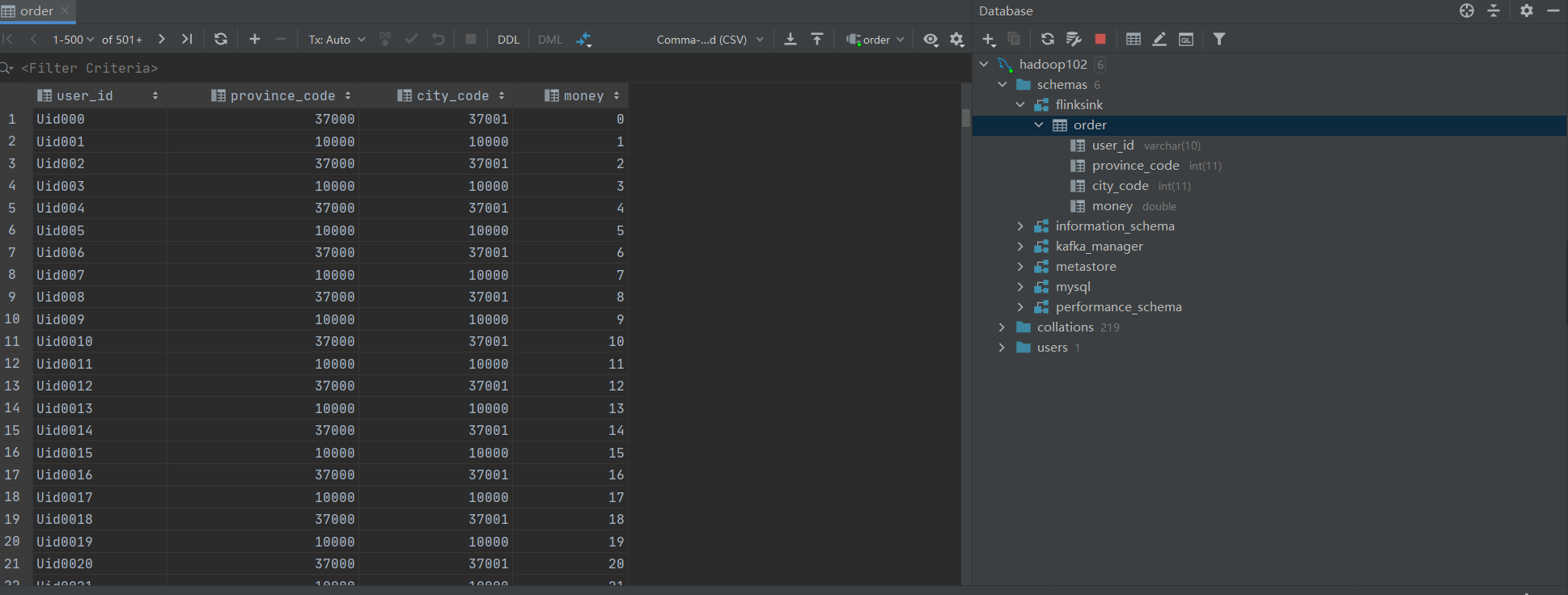
数据已经写入成功。
ClickHouse
ClickHouse是俄罗斯的Yandex(类似于百度)在2016年6月15日开源了一个数据分析的数据库,Clickhouse基于C++开发性能比较强悍,后续也会更新Clickhouse相关的文章,在我工作的公司也使用了Clickhouse。使用Flink写入Clickhouse与写入Mysql基本类似。值得注意的是,写入Clickhosue的时候最好批量写入,或者写入一个Buffer表刷到目的表,这个后续Clickhouse系列的文章会说明的。
首先创建Druid连接池。这里和Mysql链接基本类似这里我引入的Clickhosue的JDBC版本为
<dependency>
<groupId>ru.yandex.clickhouse</groupId>
<artifactId>clickhouse-jdbc</artifactId>
<version>0.1.53</version>
</dependency>
package com.hph.utils;
import com.alibaba.druid.pool.DruidDataSource;
import java.sql.Connection;
import java.sql.SQLException;
public class ClickHouseUtils {
private static DruidDataSource dataSource;
public static Connection getConnection() throws SQLException {
dataSource = new DruidDataSource();
dataSource.setDriverClassName("ru.yandex.clickhouse.ClickHouseDriver");
dataSource.setUrl("jdbc:clickhouse://hadoop102:8123/flinksink");
dataSource.setUsername("default");
//设置初始化连接数,最大连接数,最小闲置数
dataSource.setInitialSize(10);
dataSource.setMaxActive(50);
dataSource.setMinIdle(5);
//返回连接
return dataSource.getConnection();
}
}和Mysql基本类似
package com.hph.sink;
import com.google.gson.Gson;
import com.hph.bean.OrderBean;
import com.hph.utils.ClickHouseUtils;
import com.hph.utils.MysqlUtils;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import java.sql.Connection;
import java.sql.PreparedStatement;
public class ClickHouseSqlSink extends RichSinkFunction<String> {
private PreparedStatement ps;
private Connection connection;
private int i;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
//获取CK数据库连接
connection = ClickHouseUtils.getConnection();
String sql = "insert into flinksink.order (user_id,province_code,city_code,money) values (?,?,?,?); ";
ps = connection.prepareStatement(sql);
}
@Override
public void close() throws Exception {
super.close();
//关闭并释放资源
if (connection != null) {
connection.close();
}
if (ps != null) {
ps.close();
}
}
@Override
public void invoke(String value, Context context) throws Exception {
Gson gson = new Gson();
if (i <= 100) {
OrderBean orderBean = gson.fromJson(value, OrderBean.class);
ps.setString(1, orderBean.getUserId());
ps.setInt(2, orderBean.getProvinceCode());
ps.setInt(3, orderBean.getCityCode());
ps.setDouble(4, orderBean.getMoney());
ps.addBatch();
i++;
}
//攒够100条写出
if (i >= 100) {
ps.executeBatch();
i = 0;
}
}
}
/**
* @Classname MysqlSink
* @Description TODO
* @Date 2020/8/9 18:36
* @Created by hph
*/
package com.hph.sink;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.util.Properties;
public class ClickhouseSink {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
Properties props = new Properties();
//指定kafka的Broker地址
props.setProperty("bootstrap.servers", "hadoop102:9092,hadoop103:9092,hadoop104:9092");
//设置组ID
props.setProperty("group.id", "flink");
props.setProperty("auto.offset.reset", "earliest");
//kafka自动提交偏移量,
props.setProperty("enable.auto.commit", "false");
// key序列化
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// value序列化
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
DataStreamSource<String> order = environment.addSource(new FlinkKafkaConsumer<>(
"Order_Reduce",
new SimpleStringSchema(),
props
));
//flinksink 这里换成Clickhouse的结果即可
order.addSink(new ClickHouseSqlSink());
environment.execute("Flink MYSQL Sink");
}
}
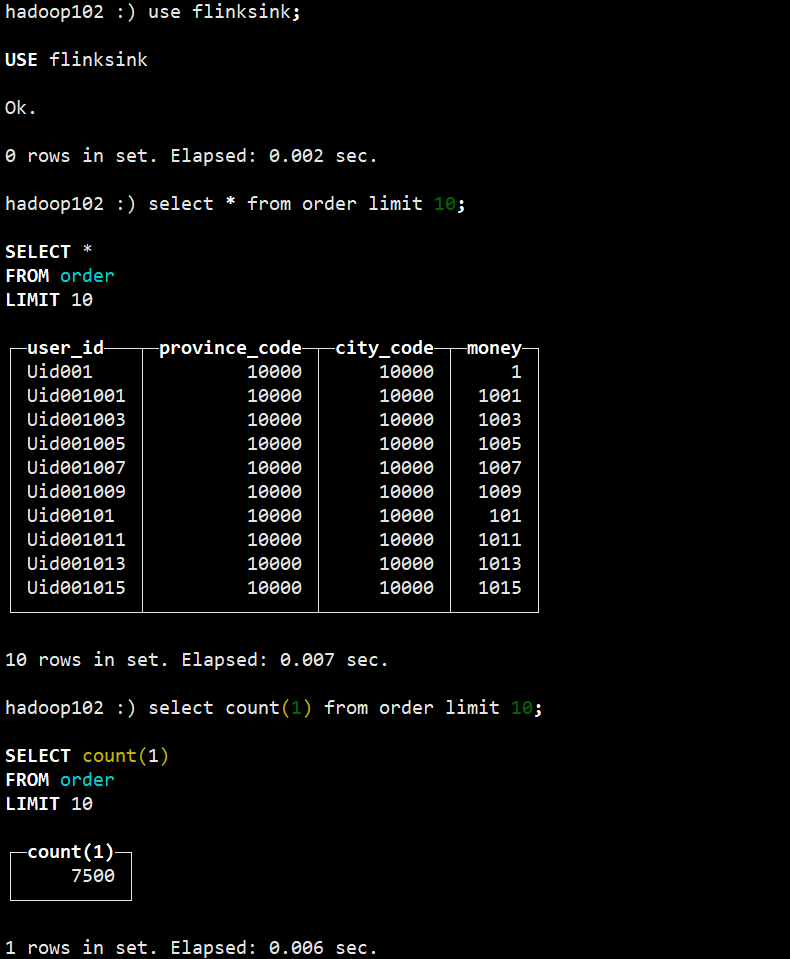
数据写入成功。
Reids
写入Redis是需要引入flink-connector-redis这里我引入的版本为:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-redis_2.11</artifactId>
<version>1.1.5</version>
</dependency>这段代码可以理解为对实时数据的分组求和,目前来说还暂未涉及到时间语义的概念,后续会更新时间语义和window相关内容。
package com.hph.sink;
import com.google.gson.Gson;
import com.hph.bean.OrderBean;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommand;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommandDescription;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisMapper;
import java.text.DecimalFormat;
import java.util.Properties;
public class RedisSink {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
Properties props = new Properties();
//指定kafka的Broker地址
props.setProperty("bootstrap.servers", "hadoop102:9092,hadoop103:9092,hadoop104:9092");
//设置组ID
props.setProperty("group.id", "flink");
props.setProperty("auto.offset.reset", "earliest");
//kafka自动提交偏移量,
props.setProperty("enable.auto.commit", "false");
// key序列化
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// value序列化
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//添加kafka数据源
DataStreamSource<String> order = environment.addSource(new FlinkKafkaConsumer<>(
"Order_Reduce",
new SimpleStringSchema(),
props
));
//映射为Orderbean
SingleOutputStreamOperator<OrderBean> orderBean = order.map(new MapFunction<String, OrderBean>() {
@Override
public OrderBean map(String value) throws Exception {
Gson gson = new Gson();
OrderBean orderBean = gson.fromJson(value, OrderBean.class);
return orderBean;
}
});
//分组求和
SingleOutputStreamOperator<OrderBean> sumed = orderBean.keyBy(new KeySelector<OrderBean, Integer>() {
@Override
public Integer getKey(OrderBean value) throws Exception {
return value.getProvinceCode();
}
}).sum("money");
//选择 k v 写入redis
SingleOutputStreamOperator<Tuple2<Integer, Double>> result = sumed.map(new MapFunction<OrderBean, Tuple2<Integer, Double>>() {
@Override
public Tuple2<Integer, Double> map(OrderBean value) throws Exception {
int provinceCode = value.getProvinceCode();
Double money = value.getMoney();
return Tuple2.of(provinceCode, money);
}
});
//创建Redis链接
FlinkJedisPoolConfig conf = new FlinkJedisPoolConfig.Builder().setHost("hadoop102").setPort(6379).setDatabase(0).build();
//将数据写入Reids redis
result.addSink(new org.apache.flink.streaming.connectors.redis.RedisSink<Tuple2<Integer, Double>>(conf, new RedisActivityBeanMapper()));
environment.execute("Redis Sink");
}
private static class RedisActivityBeanMapper implements RedisMapper<Tuple2<Integer, Double>> {
//解决科学计数法的问题
DecimalFormat df = new DecimalFormat("#");
//用哪里中操作方法将数据写入
@Override
public RedisCommandDescription getCommandDescription() {
return new RedisCommandDescription(RedisCommand.HSET, "province_order_cnt");
}
@Override
public String getKeyFromData(Tuple2<Integer, Double> data) {
return String.valueOf(data.f0);
}
@Override
public String getValueFromData(Tuple2<Integer, Double> data) {
return (df.format(data.f1));
}
}
}
写入Rdis是出现了这种错误,这是因为处于保护模式,只能本地链接。
Caused by: redis.clients.jedis.exceptions.JedisDataException: DENIED Redis is running in protected mode because protected mode is enabled, no bind address was specified, no authentication password is requested to clients. In this mode connections are only accepted from the loopback interface. If you want to connect from external computers to Redis you may adopt one of the following solutions: 1) Just disable protected mode sending the command 'CONFIG SET protected-mode no' from the loopback interface by connecting to Redis from the same host the server is running, however MAKE SURE Redis is not publicly accessible from internet if you do so. Use CONFIG REWRITE to make this change permanent. 2) Alternatively you can just disable the protected mode by editing the Redis configuration file, and setting the protected mode option to 'no', and then restarting the server. 3) If you started the server manually just for testing, restart it with the '--protected-mode no' option. 4) Setup a bind address or an authentication password. NOTE: You only need to do one of the above things in order for the server to start accepting connections from the outside.
需要修改配置文件将redis.conf修改执行以下三步即可
1)打开配置文件把下面对应的注释掉
# bind 127.0.0.1
2)Redis默认不是以守护进程的方式运行,可以通过该配置项修改,使用yes启用守护进程,设置为no
daemonize no
3)保护模式
protected-mode no

从kafkaManager观测数据为7500条和Clickhouse里面数据一致。和Clickhouse统计结果一致。
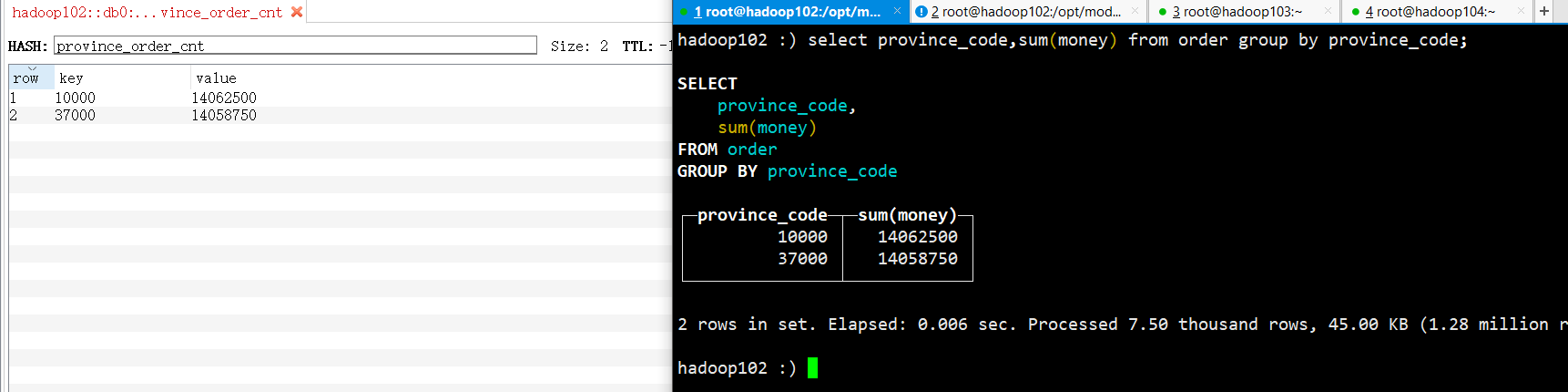
HBase
HBase的分布式安装在我的博客中可以找到,或者使用Docker镜像安装,写入HBase实际上和写入Mysql基本相同,都是实现RichSinkFunction的方法。在HBase我们首先创建一个“表”执行create 'flink-hbase','province'

Flink将数据写入HBase代码如下,相对来说也比较简单。
package com.hph.sink;
import com.google.gson.Gson;
import com.hph.bean.OrderBean;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.kafka.clients.admin.AdminClient;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Properties;
public class HBaseSink {
//创建配置
public static org.apache.hadoop.conf.Configuration conf;
//hbase链接
private static Connection connection;
//hbase表
private static Table table;
private static final Logger logger = LoggerFactory.getLogger(HBaseSink.class);
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
Properties props = new Properties();
//指定kafka的Broker地址
props.setProperty("bootstrap.servers", "hadoop102:9092,hadoop103:9092,hadoop104:9092");
//设置组ID
props.setProperty("group.id", "flink");
props.setProperty("auto.offset.reset", "earliest");
//kafka自动提交偏移量,
props.setProperty("enable.auto.commit", "false");
// key序列化
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// value序列化
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//添加kafka数据源
DataStreamSource<String> order = environment.addSource(new FlinkKafkaConsumer<>(
"Order_Reduce",
new SimpleStringSchema(),
props
));
order.addSink(new RichSinkFunction<String>() {
@Override
public void open(Configuration parameters) throws Exception {
//获取到链接
conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "hadoop102,hadoop103,hadoop104");
conf.set("hbase.zookeeper.property.clientPort", "2181");
connection = ConnectionFactory.createConnection(conf);
table = connection.getTable(TableName.valueOf("flink-hbase"));
super.open(parameters);
}
@Override
public void close() throws Exception {
super.close();
table.close();
}
@Override
public void invoke(String value, Context context) throws Exception {
Gson gson = new Gson();
OrderBean orderBean = gson.fromJson(value, OrderBean.class);
Put put = new Put(Bytes.toBytes(orderBean.getUserId()));
put.addColumn(Bytes.toBytes("province"), Bytes.toBytes(String.valueOf(orderBean.getProvinceCode())), Bytes.toBytes(String.valueOf(orderBean.getMoney())));
table.put(put);
}
});
environment.execute("Flink HBase Sink");
}
}
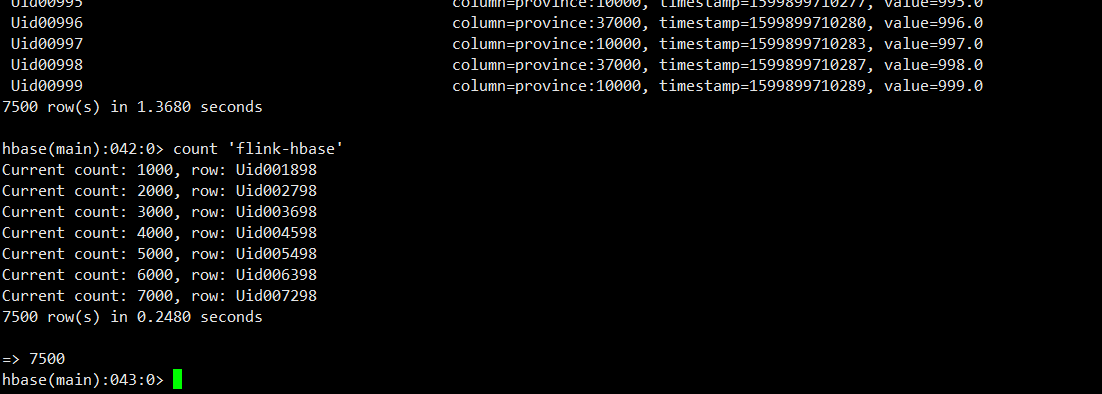
数据已经成功写入HBase。

