Flink的转换算子,就是将一个或者多个DataStream生成新的DataStream的过程被称为Transformation操作,这些操作转换可以分为单Single-DataStream、Multi-DaataStream、物理分区三类类型。在开发的过程中可以使用这些算子将数据转换为你想要的数据。
Single-DataStream操作
Map
Map主要的作用是对数据集内的数据进行清洗和转换,比如对一个订单的价格进乘以2:
Orderbean
package com.hph.bean;
import java.beans.Transient;
/**
* @Classname OrderBean
* @Description TODO
* @Date 2020/7/30 15:26
* @Created by hph
*/
public class OrderBean {
private int provinceCode;
private int cityCode;
private String userId;
private Double money;
public OrderBean(int provinceCode, int cityCode, int i, Double money) {
}
public int getProvinceCode() {
return provinceCode;
}
public void setProvinceCode(int provinceCode) {
this.provinceCode = provinceCode;
}
public int getCityCode() {
return cityCode;
}
public void setCityCode(int cityCode) {
this.cityCode = cityCode;
}
public String getUserId() {
return userId;
}
public void setUserId(String userId) {
this.userId = userId;
}
public Double getMoney() {
return money;
}
public void setMoney(Double money) {
this.money = money;
}
public OrderBean() {
}
public OrderBean(int provinceCode, int cityCode, String userId, Double money) {
this.provinceCode = provinceCode;
this.cityCode = cityCode;
this.userId = userId;
this.money = money;
}
@Override
public String toString() {
return "OrderBean{" +
"provinceCode=" + provinceCode +
", cityCode=" + cityCode +
", userId='" + userId + '\'' +
", money=" + money +
'}';
}
}KafkaProducer
/**
* @Classname KafkaOrderProducer
* @Description TODO
* @Date 2020/7/30 15:59
* @Created by hph
*/
package com.hph.datasource.producer;
import com.google.gson.Gson;
import com.google.gson.GsonBuilder;
import com.hph.bean.OrderBean;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class KafkaOrderProducer {
public static void main(String[] args) throws InterruptedException {
Properties props = new Properties();
// Kafka服务端的主机名和端口号
props.put("bootstrap.servers", "hadoop102:9092,hadoop103:9092,hadoop104:9092");
// 等待所有副本节点的应答
props.put("acks", "all");
// 消息发送最大尝试次数
props.put("retries", 0);
// 一批消息处理大小
props.put("batch.size", 16384);
// 请求延时
props.put("linger.ms", 1);
// 发送缓存区内存大小
props.put("buffer.memory", 33554432);
// key序列化
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// value序列化
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
int i = 0;
while (true) {
OrderBean orderBean = new OrderBean();
orderBean.setProvinceCode(37000);
orderBean.setCityCode(37001);
orderBean.setUserId("Uid00" + i);
orderBean.setMoney((double) i);
Gson gson = new GsonBuilder().create();
String orderBeanJson = gson.toJson(orderBean);
producer.send(new ProducerRecord<String, String>("Order", orderBeanJson));
System.out.println(orderBeanJson);
i++;
Thread.sleep(1000);
}
}
}MapDemo
/**
* @Classname MapDemo
* @Description TODO
* @Date 2020/7/30 15:26
* @author by hph
*/
package com.hph.transformation;
import com.google.gson.Gson;
import com.hph.bean.OrderBean;
import com.sun.org.apache.xpath.internal.operations.Or;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer011;
import javax.xml.crypto.Data;
import java.util.Properties;
public class MapDemo {
Gson gson;
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
Properties props = new Properties();
//指定kafka的Broker地址
props.setProperty("bootstrap.servers", "hadoop102:9092,hadoop103:9092,hadoop104:9092");
//设置组ID
props.setProperty("group.id", "flink-comsumer");
props.setProperty("auto.offset.reset", "earliest");
//kafka自动提交偏移量,
props.setProperty("enable.auto.commit", "false");
// key序列化
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// value序列化
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
DataStreamSource<String> order = environment.addSource(new FlinkKafkaConsumer<>(
"Order",
new SimpleStringSchema(),
props
));
SingleOutputStreamOperator<OrderBean> orderBeanDS = order.map(new MapFunction<String, OrderBean>() {
@Override
public OrderBean map(String value) throws Exception {
return new Gson().fromJson(value, OrderBean.class);
}
});
SingleOutputStreamOperator<OrderBean> map = orderBeanDS.map(new MapFunction<OrderBean, OrderBean>() {
@Override
public OrderBean map(OrderBean value) throws Exception {
value.setMoney(value.getMoney() * 2);
return value;
}
});
map.print();
environment.execute("Map Demo");
}
}
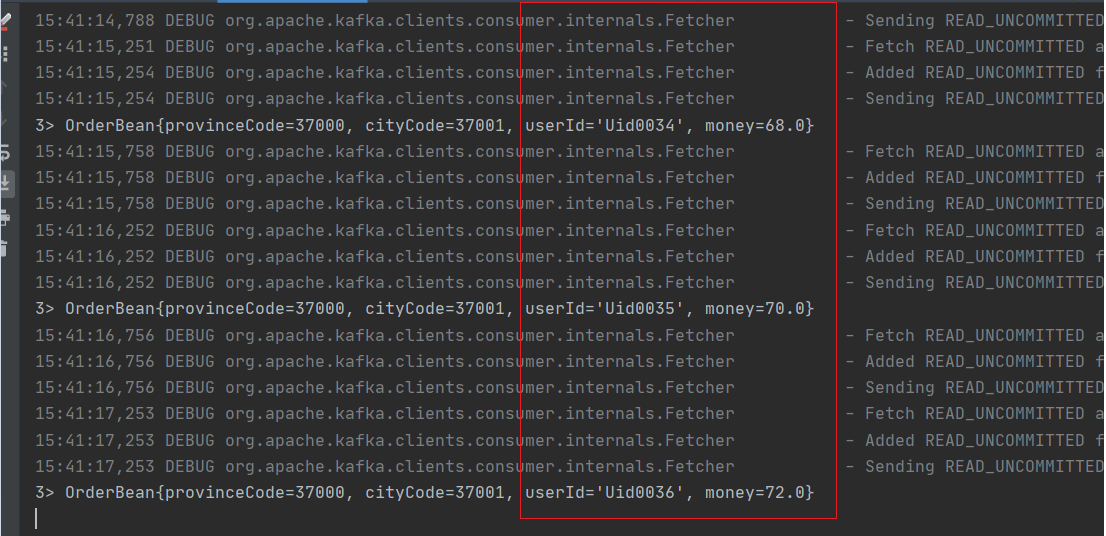
FlatMap
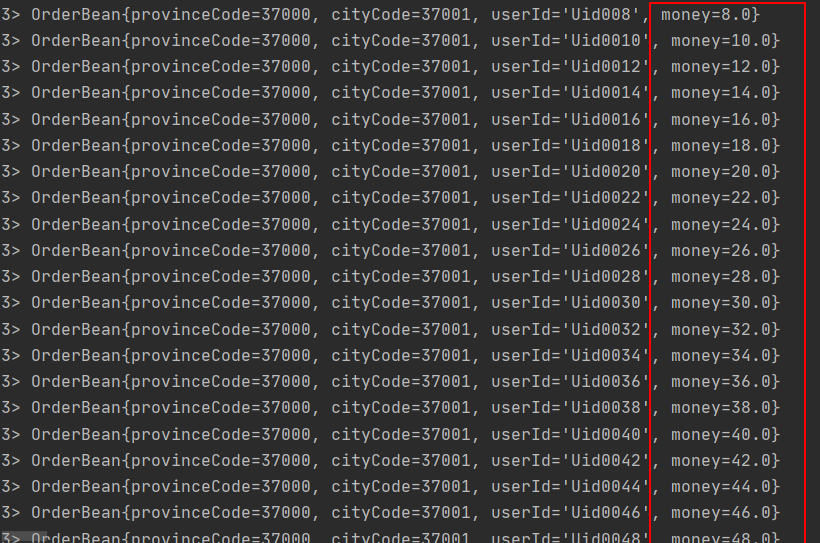
这个算子主要是处理输入一个元素,输出一个或者多个元素,比较常见的是在WordCount中对每一行文本进行切割生成新的数据。也可以在开发过程中对数据进行过滤。
FlatMapDemo
SingleOutputStreamOperator<OrderBean> flatMapDS = orderBeanDS.flatMap(new FlatMapFunction<OrderBean,
OrderBean>() {
@Override
public void flatMap(OrderBean value, Collector<OrderBean> out) throws Exception {
if (value.getMoney() % 2 == 0) {
out.collect(value);
}
}
});
Filter
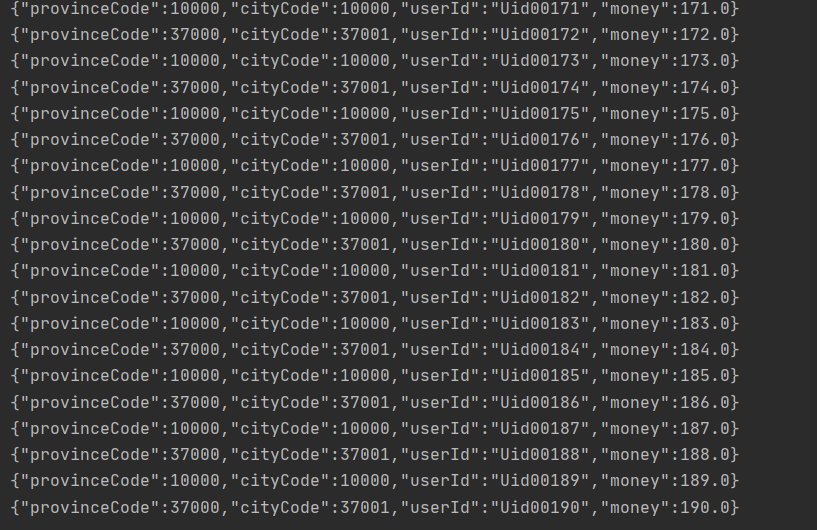
这个算子主要是对符合条件的数据集进行输出,对于不符合条件的数据过滤掉。我这里对Kafka生产者进行稍微改动一下。主要是为了增加区分
while (true) {
OrderBean orderBean = new OrderBean();
if (i % 2 == 0) {
orderBean.setProvinceCode(37000);
orderBean.setCityCode(37001);
} else {
orderBean.setProvinceCode(10000);
orderBean.setCityCode(10000);
}
orderBean.setUserId("Uid00" + i);
orderBean.setMoney((double) i);
Gson gson = new GsonBuilder().create();
String orderBeanJson = gson.toJson(orderBean);
producer.send(new ProducerRecord<String, String>("Order", orderBeanJson));
System.out.println(orderBeanJson);
i++;
Thread.sleep(1000);
}改动Kafka的Producer之后产生的数据如下:
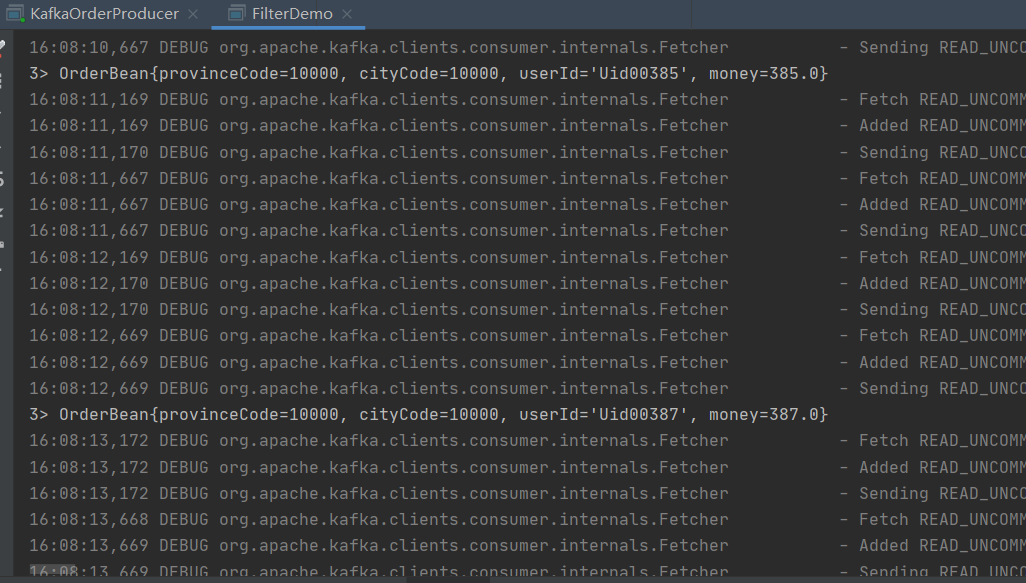
FilterDemo
这里我们过滤条件选择cityCode为10000;为true我们就输出。
SingleOutputStreamOperator<OrderBean> filterDS = orderBeanDS.filter(new FilterFunction<OrderBean>() {
@Override
public boolean filter(OrderBean value) throws Exception {
if (value.getCityCode() == 10000) {
return true;
}
return false;
}
});
KeyBy
KeyBy是按照Key对数据进行分区,使用的是hash函数对key进行处理,如果用户使用的是POJOs类型的数据,但是没有复写hashCode()方法,则使用的是Object.hashCode()
KeyByDemo
KeyedStream<OrderBean, Integer> keyedStream = orderBeanDS.keyBy(new KeySelector<OrderBean, Integer>() {
@Override
public Integer getKey(OrderBean value) throws Exception {
return value.getProvinceCode();
}
});Reduce
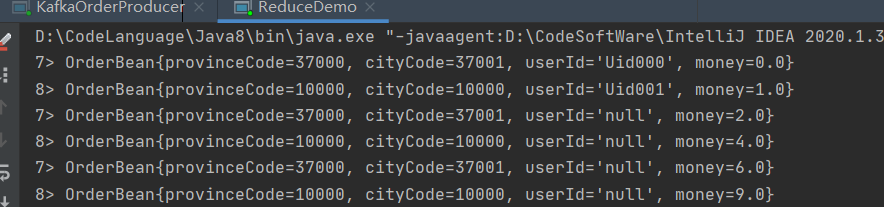
对输入的KeyedStream进行操作,对传入的数据按照用户定义的ReduceFunction滚动地进行数据聚合处理,average, sum, min, max, count,都可以使用 reduce 方法都可实现。
ReuceDemo
KeyedStream<OrderBean, Integer> keyedStream = orderBeanDS.keyBy(new KeySelector<OrderBean, Integer>() {
@Override
public Integer getKey(OrderBean value) throws Exception {
return value.getProvinceCode();
}
});
SingleOutputStreamOperator<OrderBean> reduceDS = keyedStream.reduce(new ReduceFunction<OrderBean>() {
@Override
public OrderBean reduce(OrderBean value1, OrderBean value2) throws Exception {
OrderBean orderBean = new OrderBean();
if (value1.getProvinceCode() == value2.getProvinceCode()) {
orderBean.setProvinceCode(value1.getProvinceCode());
orderBean.setCityCode(value1.getCityCode());
orderBean.setMoney(value1.getMoney() + value2.getMoney());
}
return orderBean;
}
});Producer数据

Reduce计算求和数据
Aggregations
根据指定的字段进行聚合操作,可以使用到min,max,sum 。
AgrregationsDemo
KeyedStream<OrderBean, Integer> keyedStream = orderBeanDS.keyBy(new KeySelector<OrderBean, Integer>() {
@Override
public Integer getKey(OrderBean value) throws Exception {
return value.getCityCode();
}
});
keyedStream.sum("money").print();
聚合结果和Reduce计算相同。
Multi-DataStream操作
Union
Union主要是两个或者多个输入数据集合合并为一个数据集。需要注意的是需要保证两个数据集的格式保持一致,才能合并。
UnionDemo
这里我们对KafkaProducer稍微改造一下
while (true) {
OrderBean orderBean = new OrderBean();
orderBean.setProvinceCode(10000);
orderBean.setCityCode(10000);
orderBean.setUserId("OneUid-" + i);
orderBean.setMoney((double) i);
Gson gson = new GsonBuilder().create();
String orderBeanJson = gson.toJson(orderBean);
producer.send(new ProducerRecord<String, String>("Union_topic_1", orderBeanJson));
System.out.println(orderBeanJson);
i++;
Thread.sleep(5000);
}while (true) {
OrderBean orderBean = new OrderBean();
orderBean.setProvinceCode(20000);
orderBean.setCityCode(20000);
orderBean.setUserId("TowUid-" + i);
orderBean.setMoney((double) i);
Gson gson = new GsonBuilder().create();
String orderBeanJson = gson.toJson(orderBean);
producer.send(new ProducerRecord<String, String>("Union_topic_2", orderBeanJson));
System.out.println(orderBeanJson);
i++;
Thread.sleep(5000);
}DataStreamSource<String> topicOne = environment.addSource(new FlinkKafkaConsumer<>(
"Union_topic_1",
new SimpleStringSchema(),
props
));
DataStreamSource<String> topicTwo = environment.addSource(new FlinkKafkaConsumer<>(
"Union_topic_2",
new SimpleStringSchema(),
props
));
DataStream<String> unionStream = topicOne.union(topicTwo);
unionStream.print();
Connect
Connect主要是为了合并两种或者多种不同数据类型的数据集合,合并之后保留原来数据集的数据类型,可以共享状态数据。两个数据流Connect之后需要进行map操作才能使用。
ConnectDemo
DataStreamSource<String> topicTwo = environment.addSource(new FlinkKafkaConsumer<>(
"Union_topic_2",
new SimpleStringSchema(),
props
));
ConnectedStreams<String, String> connect = topicOne.connect(topicTwo);
SingleOutputStreamOperator<OrderBean> map = connect.map(new CoMapFunction<String, String, OrderBean>() {
@Override
public OrderBean map1(String value) throws Exception {
OrderBean orderBean = new Gson().fromJson(value, OrderBean.class);
return orderBean;
}
@Override
public OrderBean map2(String value) throws Exception {
OrderBean orderBean = new Gson().fromJson(value, OrderBean.class);
return orderBean;
}
});
map.print();
environment.execute("ConnectionDemo");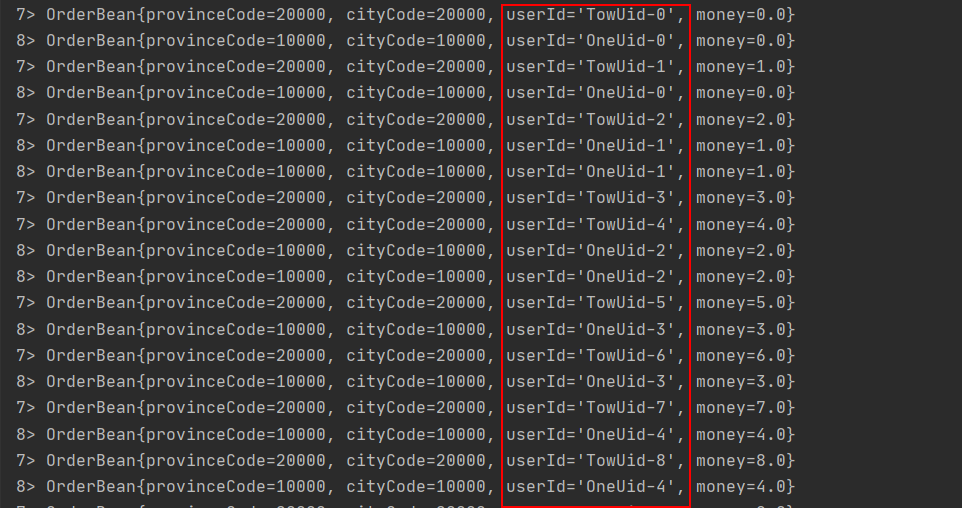
当并行度>1是无法保证数据的顺序和结果。
Split
Split是将数据集按照条件拆分形成两个数据集。目前该方法已经已经弃用了
SplitDemo
SplitStream<String> split = order.split(new OutputSelector<String>() {
@Override
public Iterable<String> select(String value) {
OrderBean orderBean = new Gson().fromJson(value, OrderBean.class);
if (orderBean.getCityCode() == 10000) {
return Arrays.asList("10000");
} else {
return Arrays.asList("37001");
}
}
});
split.print();
environment.execute("SplitDemo");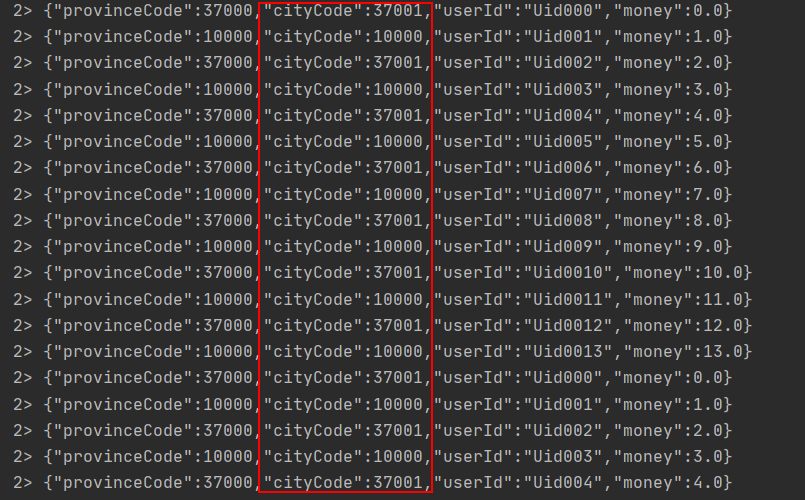
但是split并没有生效这是由于Split函数本身只是对输入数据进行了标记,并未实现切分,需要借助Select来切分数据并将数据筛选出来。这里我们选择一个10000标签的数据
select
DataStreamSource<String> order = environment.addSource(new FlinkKafkaConsumer<>(
"Order_Reduce",
new SimpleStringSchema(),
props
));
SplitStream<String> split = order.split(new OutputSelector<String>() {
@Override
public Iterable<String> select(String value) {
OrderBean orderBean = new Gson().fromJson(value, OrderBean.class);
if (orderBean.getCityCode() == 10000) {
return Arrays.asList("10000");
} else {
return Arrays.asList("37001");
}
}
});
split.select("10000").print();
environment.execute("SelectDemo");
}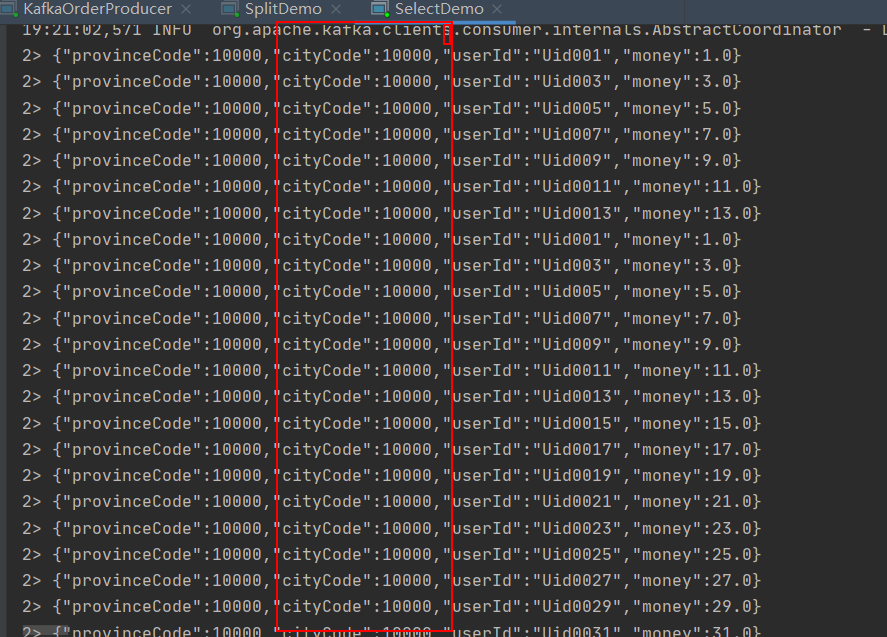
这样子就完成了对数据分割和选择。
Project
Project 函数允许我们从流数据集中选择属性子集,不过数据的类型目前必须是Tuple类型,并仅将所选元素发送到下一个处理流。
DataStreamSource<String> order = environment.addSource(new FlinkKafkaConsumer<>(
"Order_Reduce",
new SimpleStringSchema(),
props
));
SingleOutputStreamOperator<Tuple4<Integer, Integer, String, Double>> map = order.map(new MapFunction<String, Tuple4<Integer, Integer, String, Double>>() {
@Override
public Tuple4<Integer, Integer, String, Double> map(String value) throws Exception {
OrderBean orderBean = new Gson().fromJson(value, OrderBean.class);
int provinceCode = orderBean.getProvinceCode();
int cityCode = orderBean.getCityCode();
String userId = orderBean.getUserId();
Double money = orderBean.getMoney();
return Tuple4.of(provinceCode, cityCode, userId, money);
}
});
map.project(2,3).print();
environment.execute("Project");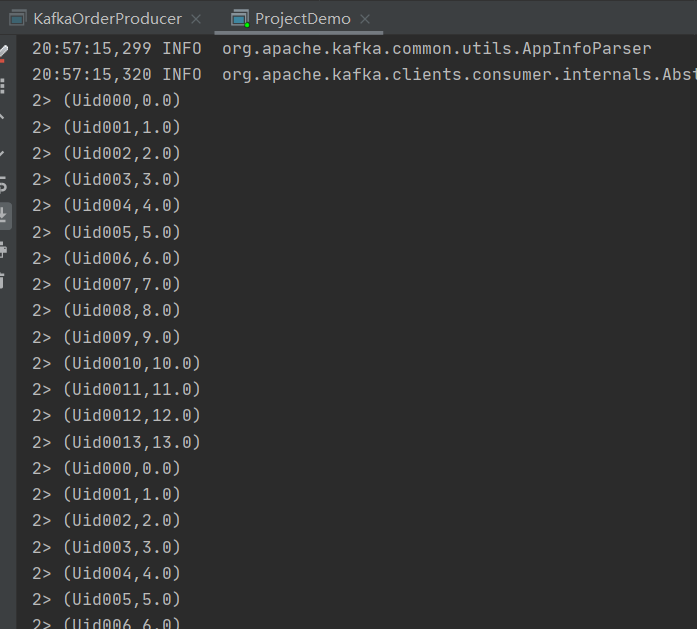
这里我们获取到了相关的Tuple属性。
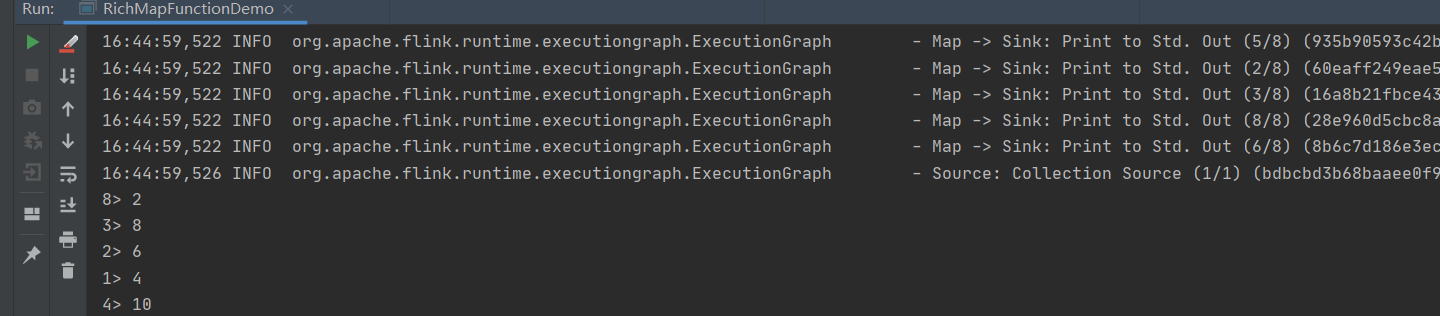
RichFunction
相对于普通的Function,RichFunction提供了更加丰富的功能和操作,比如open, close, getRuntimeContext 和setRuntimeContext方法,这些方法可以参数化函数(传递参数),创建和完成本地状态,访问广播变量以及访问运行时信息以及有关迭代中的信息。
/**
* @Classname RichMapFunctionDemo
* @Description TODO
* @Date 2020/8/9 16:43
* @Created by hph
*/
package com.hph.transformation;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class RichMapFunctionDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Integer> nums = env.fromElements(1, 2, 3, 4, 5);
//传入功能更加强大的RichMapFunction
SingleOutputStreamOperator<Integer> map = nums.map(new RichMapFunction<Integer, Integer>() {
//open,在构造方法之后,map 方法之前,执行一次,并且可以拿到全局的配置
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
}
@Override
public Integer map(Integer value) throws Exception {
return value * 2;
}
@Override
public void close() throws Exception {
super.close();
}
});
//sink
map.print();
env.execute("RichMapFunction Job");
}
}
物理分区操作
物理分区可以将数据按照分区策略进行重新分配到不同Task上。
随机分区
随机分区可以将数据以随机的方式发送到下游算子的每一个分区中,分区相对均衡,但是比较容易破坏原有的分区结构。
DataStreamSource<String> order = environment.addSource(new FlinkKafkaConsumer<>(
"Order_Reduce",
new SimpleStringSchema(),
props
));
//调用随机分区
DataStream<String> shuffle = order.shuffle(); 轮询分区
通过循环的方式对数据集种的数据进行重新分区,能够保证每个分区的数据平衡,在数据倾斜的时候用轮询分区去比较有效。
DataStreamSource<String> order = environment.addSource(new FlinkKafkaConsumer<>(
"Order_Reduce",
new SimpleStringSchema(),
props
));
DataStream<String> rebalance = order.rebalance();ReScaling
Rescaling Partitioning 也是一种通过循环的方式进行数据重新恒的分区策略。在使用rebalance()时,数据会全局性地通过网络传输到其他节点。使用rescale()
则会根据上下游的并行度比例将数据按比例发送到下游。
DataStreamSource<String> order = environment.addSource(new FlinkKafkaConsumer<>(
"Order_Reduce",
new SimpleStringSchema(),
props
));
DataStream<String> shuffle = order.rescale();
order.print();
environment.execute("rescaleDemo");广播操作
广播主要时将输入的数据集复制到下游算子的Task实例中,下游的Tasks可以直接从本地内存获取到广播数据集,不在依赖网络传输,和Spark的广播变量基本原理类似。比较适合大数据集关联小数据集时。
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Long> longDataStreamSource = executionEnvironment.generateSequence(0, 100);
longDataStreamSource.broadcast();总结

Flink目前的编程模型如图所致,Source主要获取输入的流式数据集合,常见的有基于消息队列、基于网络套接字、基于本地集合、基于文件和自定义的Source。
Transformation:时数据的转换操作有 Map / FlatMap / Filter / KeyBy / Reduce / Fold / Aggregations / Union / Split / Select / Projec等。
Sink:计算结果的落地地点,常见的Sink有文件写入、写入Socket,消息队列、自定义Sink等。

