顾名思义,DataSource就是数据源,在Flink中已经预先定义了一些DataSource,这些预定义好的数据源可以从文件,目录、套接字,以及从集合和迭代器中提取数据。预定好的数据源主要有:Socket、Amazon Kinesis Streams、RabbitMQ 、Apache NiFi、Twitter Streaming API 、Google PubSub 。
Maven依赖文件
整个项目的依赖如下:
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.11.0</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.11</scala.binary.version>
<maven.compiler.source>${java.version}</maven.compiler.source>
<maven.compiler.target>${java.version}</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.7</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>com.rabbitmq</groupId>
<artifactId>amqp-client</artifactId>
<version>3.6.5</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.11.0</version>
</dependency>
<!--gson-->
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.8.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-rabbitmq_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!--Kafka依赖-->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.11.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.11</artifactId>
<version>0.11.0.0</version>
</dependency>
<!--redis 以来-->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.3</version>
</dependency>
</dependencies>文件
Flink对于文件系统的Source源预先设定了如下方法:

ReadTextFile
ReadTextFile该方法比较简单可以逐行读取给定文件的数据并创建一个数据流,也支持从HDFS分布式文件上读取数据。
/**
* @Classname FileSource
* @Description TODO
* @Date 2020/7/19 11:46
* @Created by hph
*/
package com.hph.datasource;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class TextFileSource {
public static void main(String[] args) throws Exception {
//获取执行环境
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
//读取路径
DataStreamSource<String> dataStreamSource = environment.readTextFile("D:\\博客\\hphblog\\package-lock.json");
//输出数据
dataStreamSource.print();
//执行任务
environment.execute("FileSource");
}
}ReadHDFSFile
/**
* @Classname HadoopFileSource
* @Description TODO
* @Date 2020/7/19 11:51
* @Created by hph
*/
package com.hph.datasource;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class HadoopFileSource {
public static void main(String[] args) throws Exception {
//获取执行环境
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
//读取HDFS文件目录
DataStreamSource<String> HadoopFileSource = environment.readTextFile("hdfs://hadoop102:9000/input/test","UTF-8");
//打印数据
HadoopFileSource.print();
//执行任务
environment.execute("HadoopFileSource");
}
}ReadFile
同时我们也可使使用ReadFile来读取文件夹下面的数据
/**
* @Classname FileSource
* @Description TODO
* @Date 2020/7/20 22:51
* @Created by hph
*/
package com.hph.datasource;
import org.apache.flink.api.common.typeinfo.BasicTypeInfo;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.core.fs.Path;
import org.apache.flink.api.java.io.TextInputFormat;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.FileProcessingMode;
public class FileSource {
public static void main(String[] args) throws Exception {
//获取执行环境
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
//文件路径
String filePath= "D:\\博客\\hphblog\\package-lock.json";
Path path = new Path(filePath);
TextInputFormat format = new TextInputFormat(path);
format.setCharsetName("UTF-8");
//TypeInformation 类型
BasicTypeInfo typeInfo = BasicTypeInfo.STRING_TYPE_INFO;
DataStreamSource dataStreamSource = environment.readFile(format, filePath, FileProcessingMode.PROCESS_ONCE, 1, (TypeInformation) typeInfo);
//打印数据
dataStreamSource.print();
environment.execute("FileSource");
}
}在本文中实现的方法是:
其中inputFormat - 输入格式用于创建数据流,filePath是文件路径可以是 file:///some/local/file 或者 hdfs://host:port/file/path,watchType
监视路径对新数据做响应,或者处理一次然后退出,interval指的是时间间隔,最后需要指定TypeInformation。
在Flink中ReadFile的具体实现是:
Flink将文件读取过程分为两个子任务,即目录监控和数据读取。这些子任务中的每一个都由单独的实体实现。监视由单个非并行(并行性= 1)任务实现,而读取由并行运行的多个任务执行。后者的并行度等于工作并行度。单个监视任务的作用是扫描目录(定期或仅一次,具体取决于watchType),找到要处理的文件,将它们分割成片,并将这些拆分分配给下游reader。reader负责读取数据。每个分片仅由一个Reader读取,而一个Reader可以逐个读取多个分片。
在FileProcessingMode中有两个属性,分别是WatchType.ONLY_NEW_FILES:处理整个文件,REPROCESS_WITH_APPENDED :当文件内容增加了之后会重新处理整个文件。
如果 watchType 设置为 FileProcessingMode.PROCESS_CONTINUOUSLY,那么当被监控的文件被修改时,其内容会被重新处理。会打破exactly-once语义,在文件修改时内容又被重新读取。
如果 watchType 设置为 FileProcessingMode.PROCESS_ONCE,那么仅扫描路径一次然后退出,而不等待 reader 完成文件内容的读取。当然 reader 会继续,直到读取所有的文件内容。在被扫描的路径下使用FileInputSplits来处理数据。
值得注意的是如果使用文件作为数据源,如果数据不断地生成 ,将会导致节点数据形成挤压,可能需要耗费非常长的时间从最新的checkpoint中回复应用。
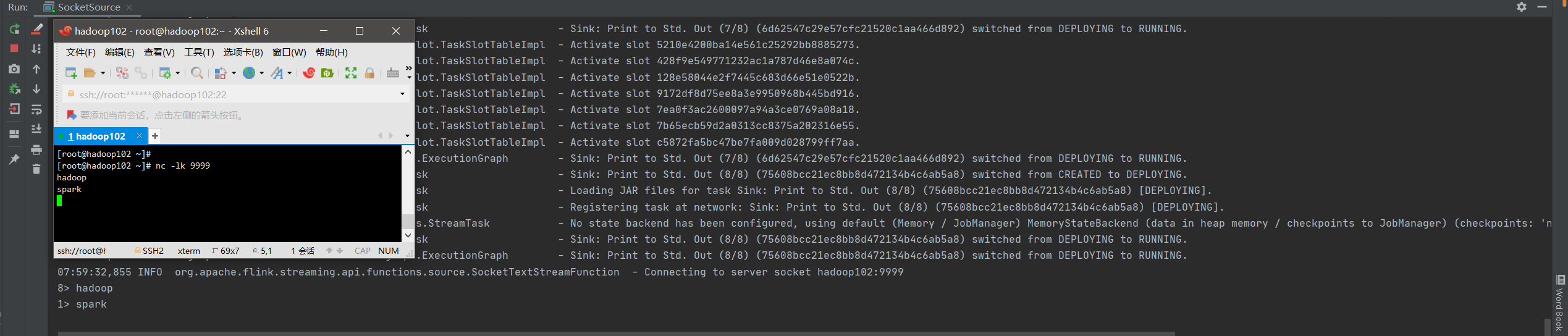
Socket
基于Sockt的数据源比较简单我们只需要传入两个参数,IP和端口号。
/**
* @Classname SocketSource
* @Description TODO
* @Date 2020/7/19 11:07
* @Created by hph
*/
package com.hph.datasource;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class SocketSource {
public static void main(String[] args) throws Exception {
//创建环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> socketStream = env.socketTextStream("hadoop102", 9999);
socketStream.print();
env.execute("socket DataSource");
}
}
集合
基于集合可以生成不同的数据类型,在实际开发中可以生成测试数据,根据测试数据做相应的业务处理。最后更换数据源即可。
/**
* @Classname ElementsSource
* @Description TODO
* @Date 2020/7/19 11:24
* @Created by hph
*/
package com.hph.datasource;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.Arrays;
public class ElementsSource {
public static void main(String[] args) throws Exception {
//执行环境
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
//根据元素可以生成流数据
DataStreamSource<String> elements = environment.fromElements("flink", "bigdata", "spark");
//从1-100 生成数据流
DataStreamSource<Long> generateSequence = environment.generateSequence(1, 100);
//从数组中生成数据
DataStreamSource<String> collectionDataSource = environment.fromCollection(Arrays.asList("Collection_1",
"Collection_2", "Collection_3"));
collectionDataSource.print();
generateSequence.print();
elements.print();
environment.execute("ElementsSource");
}
}RabbitMQ
RMQSource 负责从 RabbitMQ 中消费数据,可以配置三种不同级别的保证:
- 精确一次: 保证精确一次需要以下条件:
- 开启 checkpointing: 开启 checkpointing 之后,消息在 checkpoints 完成之后才会被确认(然后从 RabbitMQ 队列中删除)。
- 使用关联标识(Correlation ids): 关联标识是 RabbitMQ 的一个特性,消息写入 RabbitMQ 时在消息属性中设置。 从 checkpoint 恢复时有些消息可能会被重复处理,source 可以利用关联标识对消息进行去重。
- 非并发 source: 为了保证精确一次的数据投递,source 必须是非并发的(并行度设置为1)。 这主要是由于 RabbitMQ 分发数据时是从单队列向多个消费者投递消息的。
- 至少一次: 在 checkpointing 开启的条件下,如果没有使用关联标识或者 source 是并发的, 那么 source 就只能提供至少一次的保证。
- 无任何保证: 如果没有开启 checkpointing,source 就不能提供任何的数据投递保证。 使用这种设置时,source 一旦接收到并处理消息,消息就会被自动确认。
MQProducer
RabbitMQSource
在以RabitMQ的数据源中我们可以创建一个RabbitMQ类似于Kafka的Producer,来生产数据。
/**
* @Classname RabbitMQProduce
* @Description TODO
* @Date 2020/7/19 14:18
* @Created by hph
*/
package com.hph.datasource.producer;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
import java.io.IOException;
import java.util.concurrent.TimeoutException;
public class RabbitMQPublisher {
public static void main(String[] args) throws IOException, TimeoutException, InterruptedException {
ConnectionFactory factory = new ConnectionFactory();
//设置RabbitMQ相关信息
factory.setHost("hadoop102");
factory.setUsername("test");
factory.setPassword("123456");
factory.setPort(5672);
//创建连接
Connection connection = factory.newConnection();
//创建通道
Channel channel = connection.createChannel();
String message = "MQ FROM Java Client-";
int i=0;
while (true){
channel.basicPublish("", "Test", null, (message + i).getBytes("UTF-8"));
Thread.sleep((int)(Math.random()*1000));
i++;
System.out.println(message + i);
}
}
}
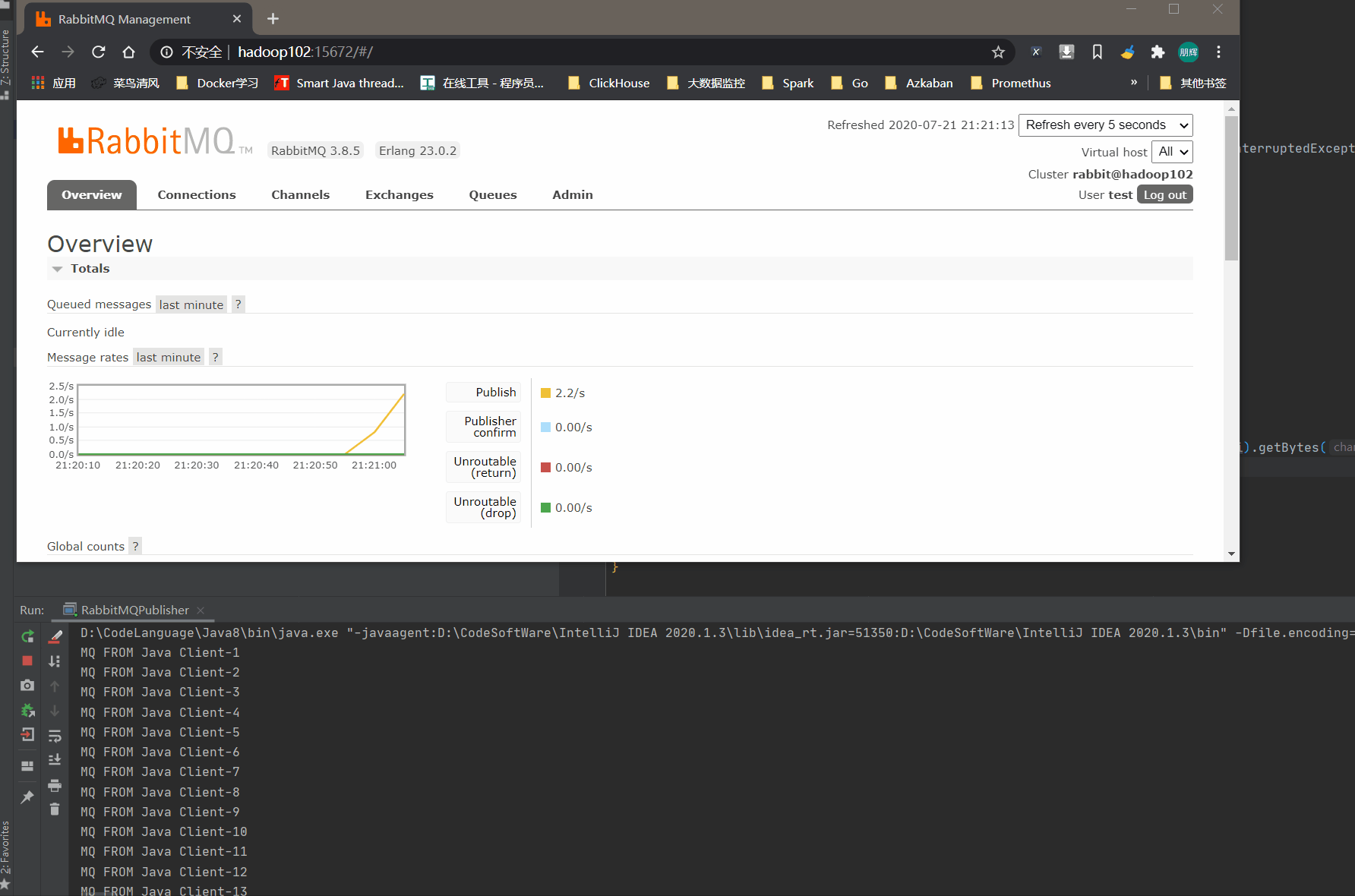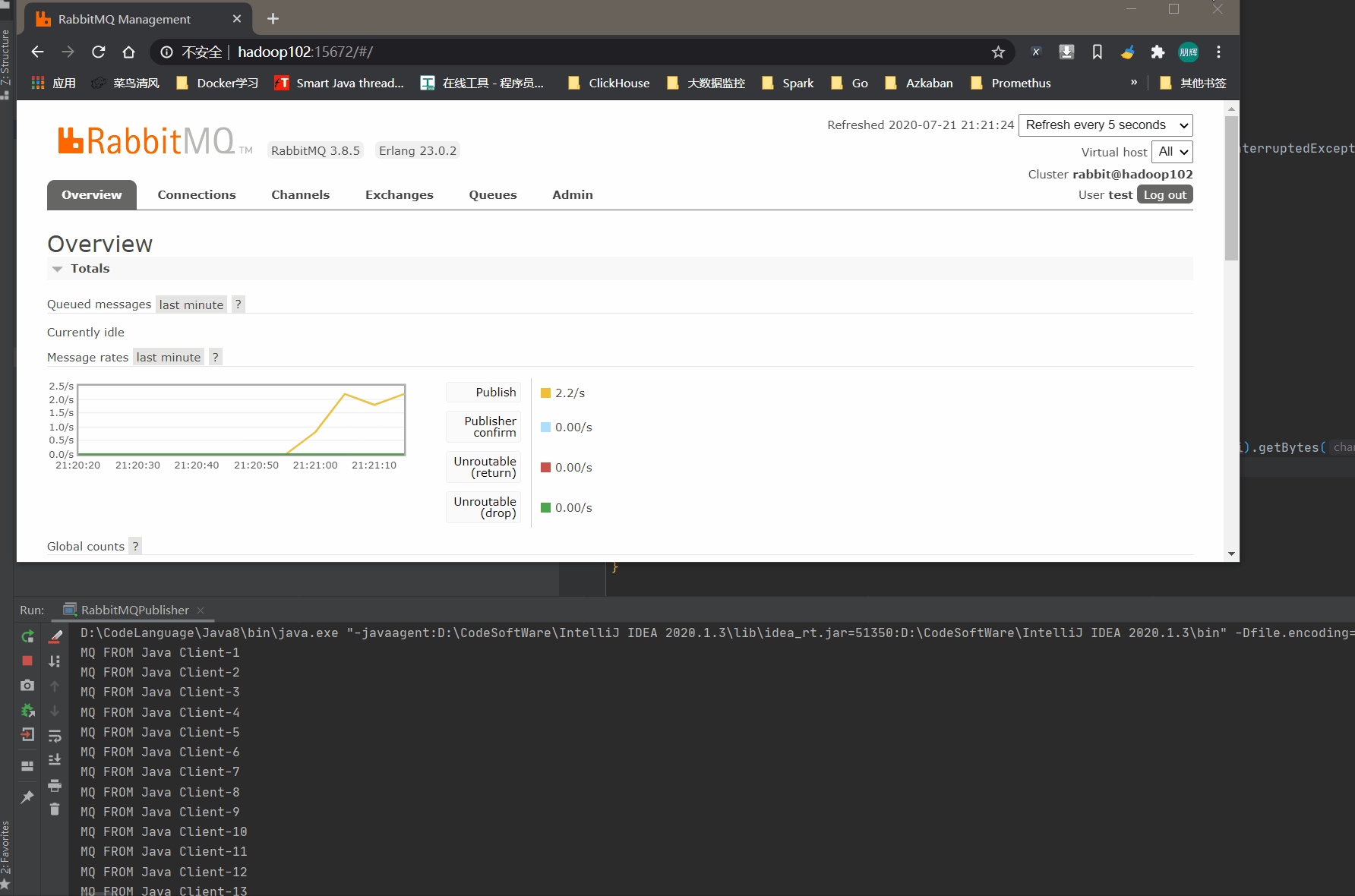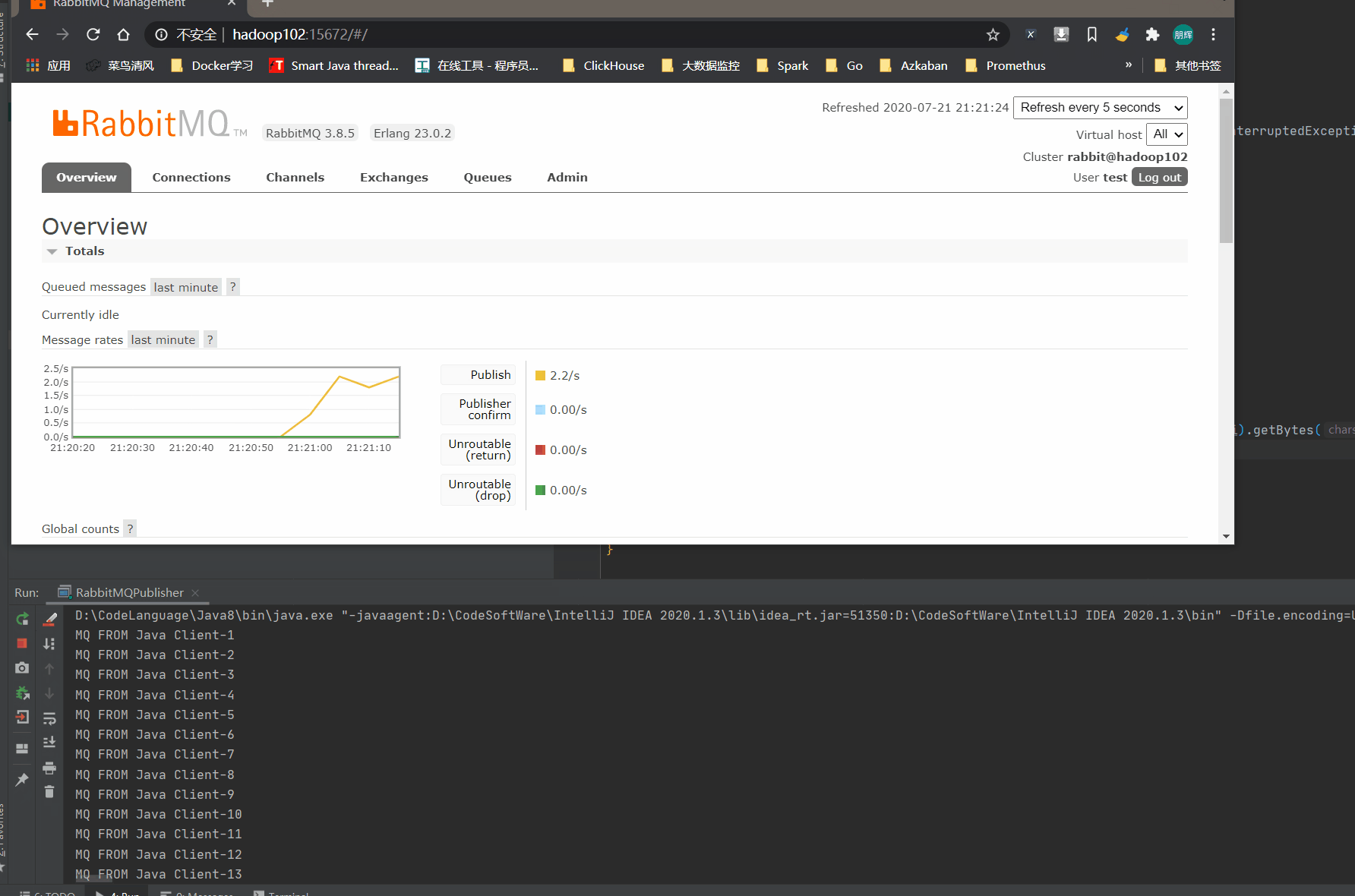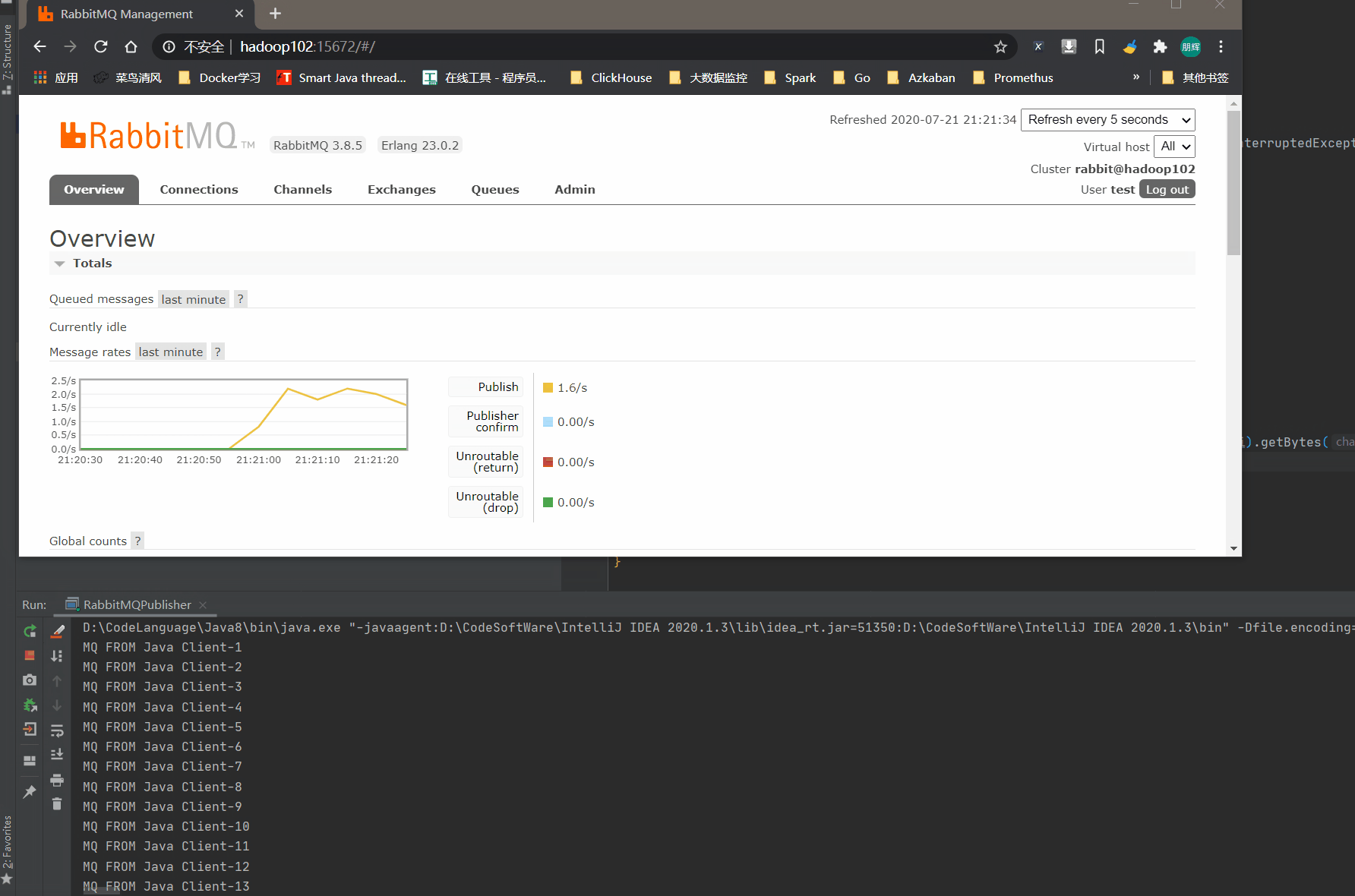
我们可以再页面中看到数据正在不断增加,在Flink中已经自定义好了RabbitMQ。消费RabbitMQ的数据比较简单。
/**
* @Classname RabbitMQSource
* @Description TODO
* @Date 2020/7/19 14:29
* @Created by hph
*/
package com.hph.datasource;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.rabbitmq.RMQSource;
import org.apache.flink.streaming.connectors.rabbitmq.common.RMQConnectionConfig;
public class RabbitMQSource {
public static void main(String[] args) throws Exception {
//设置环境
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
//RabbitMQ配置
RMQConnectionConfig rmqConnectionConfig = new RMQConnectionConfig.Builder()
.setHost("hadoop102")
.setPort(5672)
.setUserName("test")
.setPassword("123456")
.setVirtualHost("/")
.build();
//添加数据源
DataStreamSource<String> rabbitMQSource = environment.addSource(new RMQSource<String>(
rmqConnectionConfig, //链接RabbitMQ配置信息
"Test", //被消费的队列
true,//反序列化
new SimpleStringSchema())) //Schema样例
.setParallelism(1); //非并行
rabbitMQSource.print();
environment.execute("Rabbit MQ Source");
}
}
值得注意的是,Flink提供了RMQSource这个类从RabbitMQ队列中消费数据,RabbitMQ提供了三种不同的语义保证。主要是通过Flink的配置。
Exactly-once:
- 首先要开启checkpointing,检查点开启后,仅当checkpoints才会发出消息确认。
- 使用相关的ID:相关ID是RabbitMQ应用程序的功能,将消息写入RabbitMQ时,必须在消息属性中进行设置。从检查点还原时,源使用相关ID对重复处理的所有消息进行重复数据删除。
- 并行度为1
At-least-once:
- 开启checkpointing,但不使用相关的ID,或者Source是并行的,这样只能保证At-least-once
不保证:checkpointing没有开启,消息将在源接受出处理后得到自动的确认。
KafkaSource
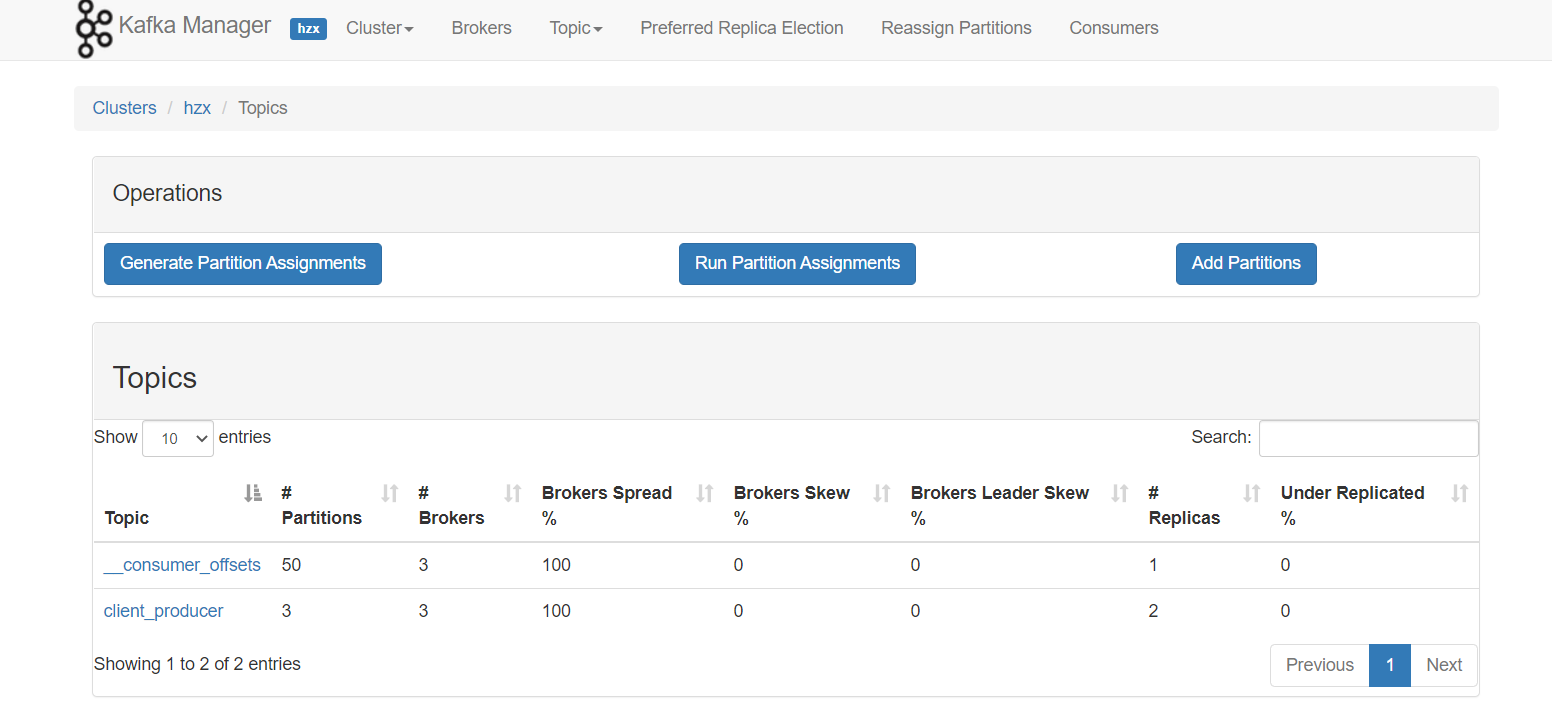
Kafka目前有多个版本,在生产环境中主要使用到的还是0.11。Kafka的安装可以在我的博客中找到具体方法。在KafkaManager中我们创建一个名为client_producer的Topic
在下下面的程序中使用KafkaProducer生成数据项Kafka的Topicclient_producer发送数据
/**
* @Classname KafkaMSProducer
* @Description TODO
* @Date 2020/7/19 16:17
* @Created by hph
*/
package com.hph.datasource.producer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class KafkaMSProducer {
public static void main(String[] args) throws InterruptedException {
Properties props = new Properties();
// Kafka服务端的主机名和端口号
props.put("bootstrap.servers", "hadoop102:9092,hadoop103:9092,hadoop104:9092");
// 等待所有副本节点的应答
props.put("acks", "all");
// 消息发送最大尝试次数
props.put("retries", 0);
// 一批消息处理大小
props.put("batch.size", 16384);
// 请求延时
props.put("linger.ms", 1);
// 发送缓存区内存大小
props.put("buffer.memory", 33554432);
// key序列化
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// value序列化
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
int i=0;
while (true) {
producer.send(new ProducerRecord<String, String>("client_producer", Integer.toString(i), "hello kafka-" + i));
System.out.println("hello kafka-"+i);
Thread.sleep((int)(Math.random()*1000));
i++;
}
}
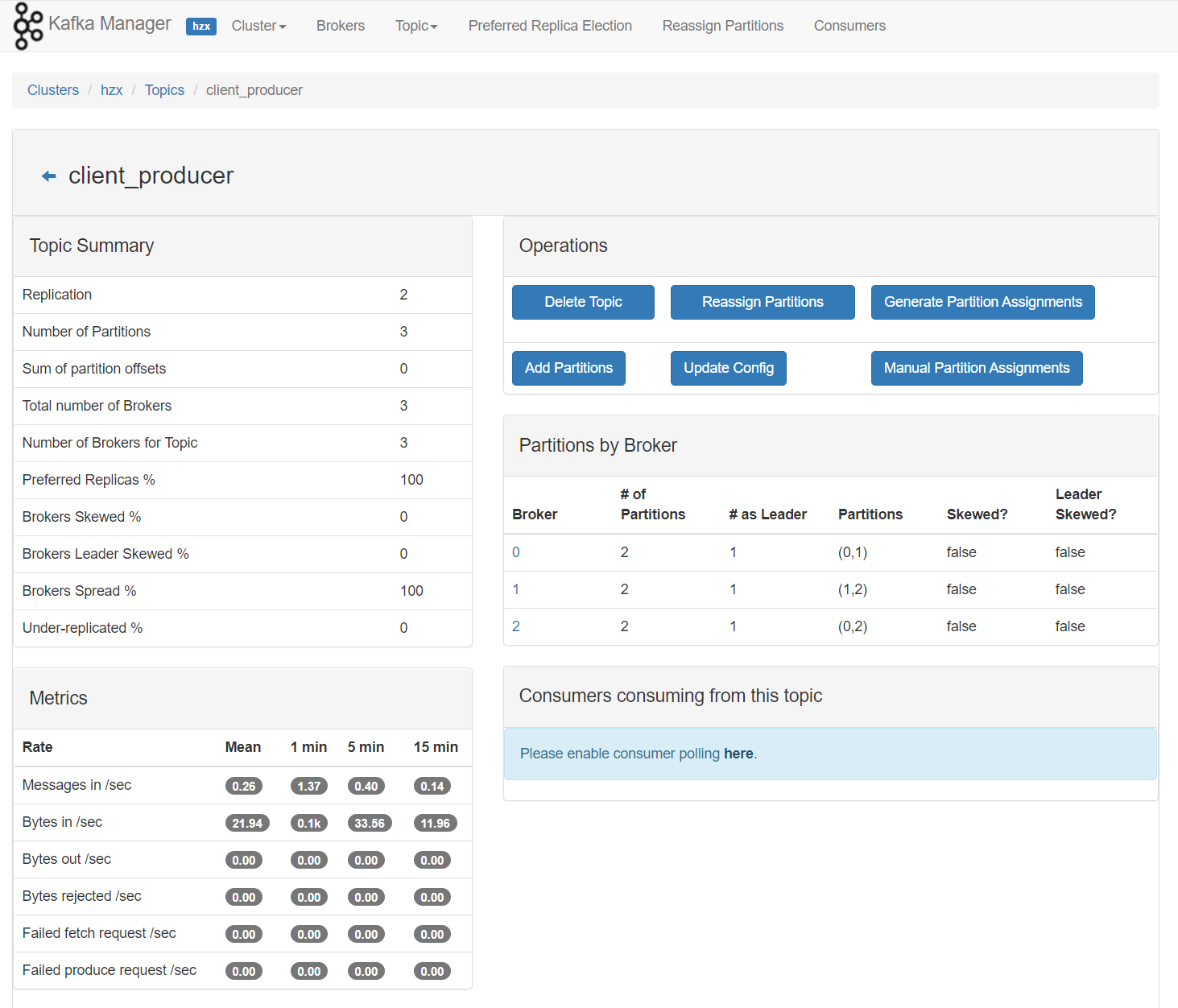
}KafkaProducer程序启动之后我们可以在KafkaManager页面上看到数据的变化,
下面是Flink以Kafka为数据源读取数据,
/**
* @Classname KafkaSource
* @Description TODO
* @Date 2020/7/19 16:21
* @Created by hph
*/
package com.hph.datasource;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.util.Properties;
public class KafkaSource {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
Properties props = new Properties();
//指定kafka的Broker地址
props.setProperty("bootstrap.servers","hadoop102:9092,hadoop103:9092,hadoop104:9092");
//设置组ID
props.setProperty("group.id","flink-comsumer");
props.setProperty("auto.offset.reset","earliest");
//kafka自动提交偏移量,
props.setProperty("enable.auto.commit","false");
FlinkKafkaConsumer<String> kafkaSouce = new FlinkKafkaConsumer<>("client_producer", //指定Topic
new SimpleStringSchema(), //指定Schema,生产中一般使用Avro
props); //Kafka配置
DataStreamSource<String> kafkaSource = environment.addSource(kafkaSouce);
kafkaSource.print();
environment.execute("Kafka Source");
}
}我们刷新一个KafkaManager
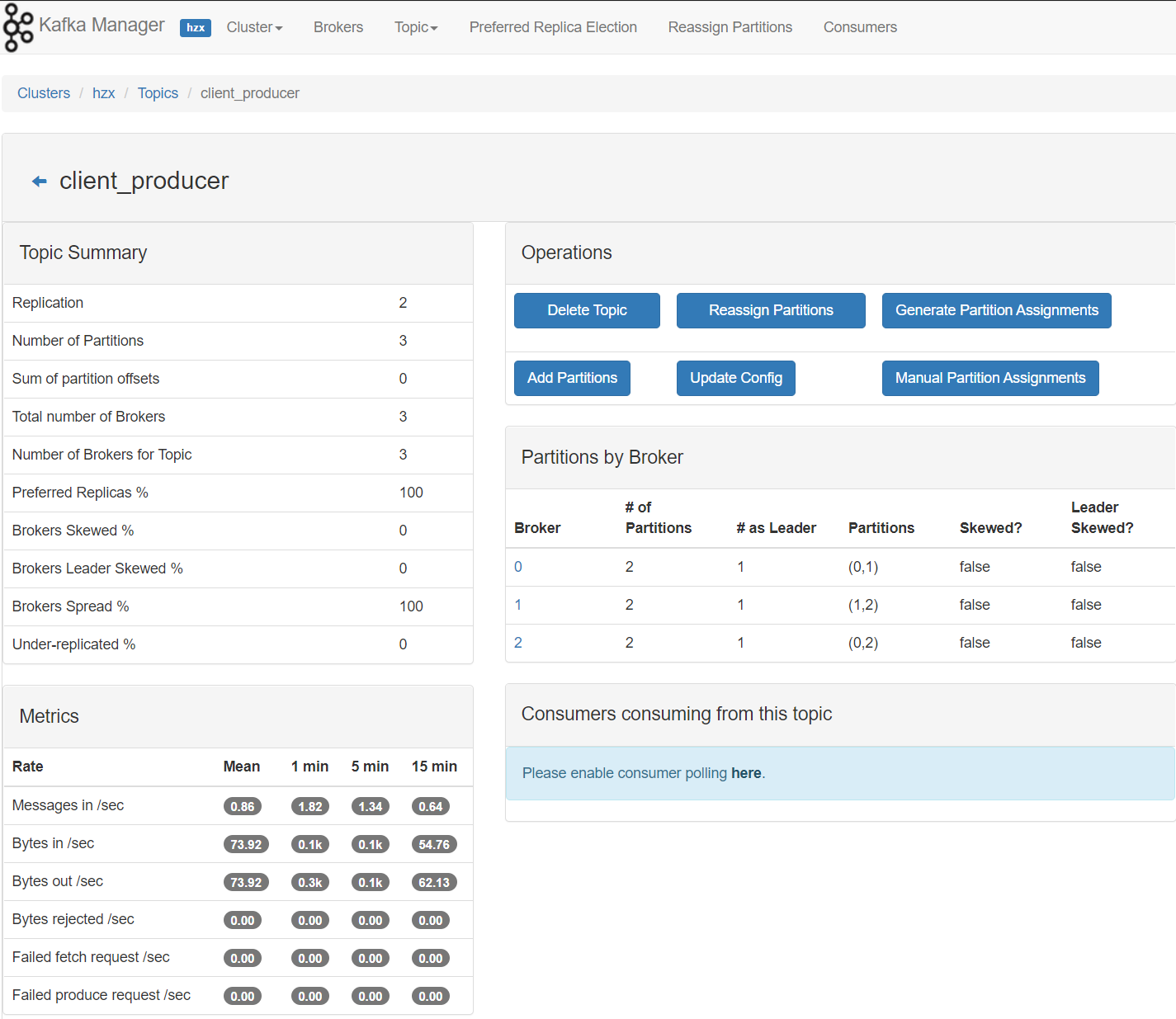
数据已经被消费到了,值得注意的是,Flink Kafka Consumer 集成了 Flink 的 Checkpoint 机制,可提供 exactly-once 的处理语义。为此,Flink并不完全依赖于跟踪 Kafka 消费组的偏移量,而是在内部跟踪和检查偏移量。
自定义DataSource
在实际的生产中可能数据是需要我们自己实现的,要实现自定义的Dataource,我们需要实现SourceFunction,或者更为强大的RichSourceFunction,这里实现的是RichSourceFunction。从下面的依赖图可以看出,RichSourceFunction更为强大,在开发过程中,open()可以部分可以以重新JDBC的链接,减少建立数据库链接。
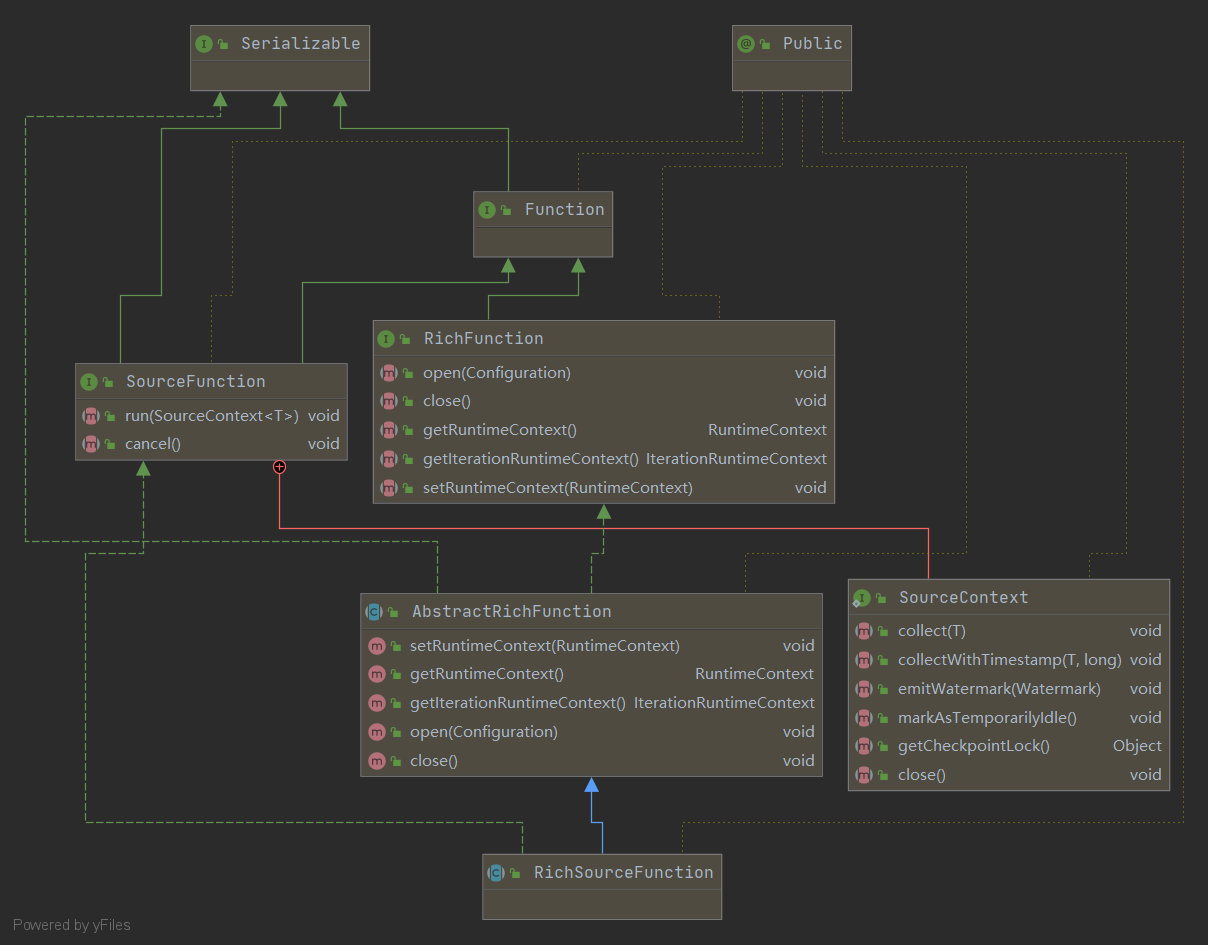
在RichSourceFunction的中有2个抽象类继承了它,
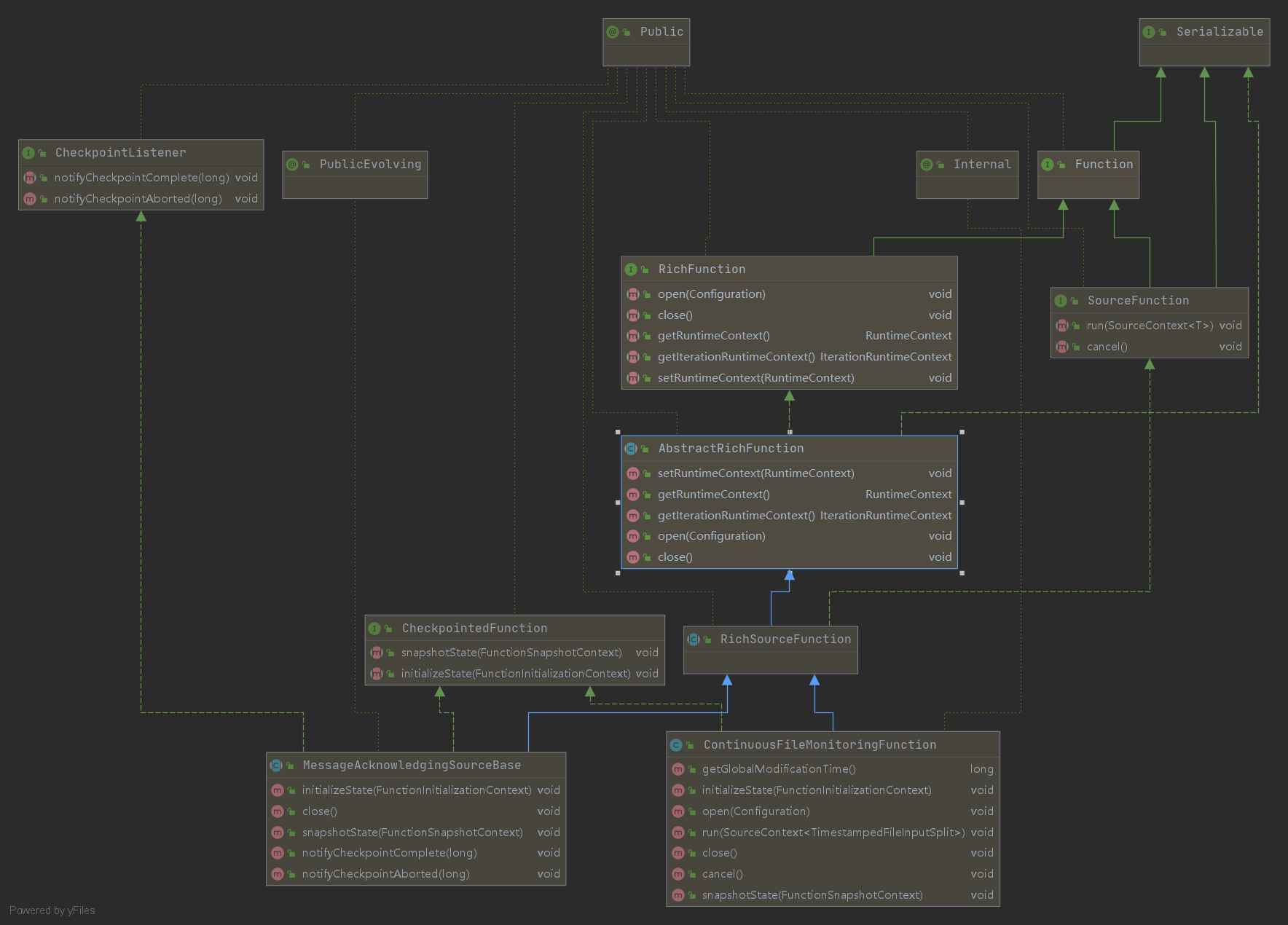
我们首先看一下MessageAcknowledgingSourceBase,这个类从消息队列中接收数据,提供了基于ID应答的应答机制。
ContinuousFileMonitoringFunction这是单一(非平行)监测任务,其需要一个FileInputFormat和,取决于FileProcessingMode和FilePathFilter ,它负责:
- 监控用户提供的路径。
- 决定哪些文件应进一步读取和处理。
- 创建splits对应于这些文件。
- 他们指定作进一步处理下游任务。
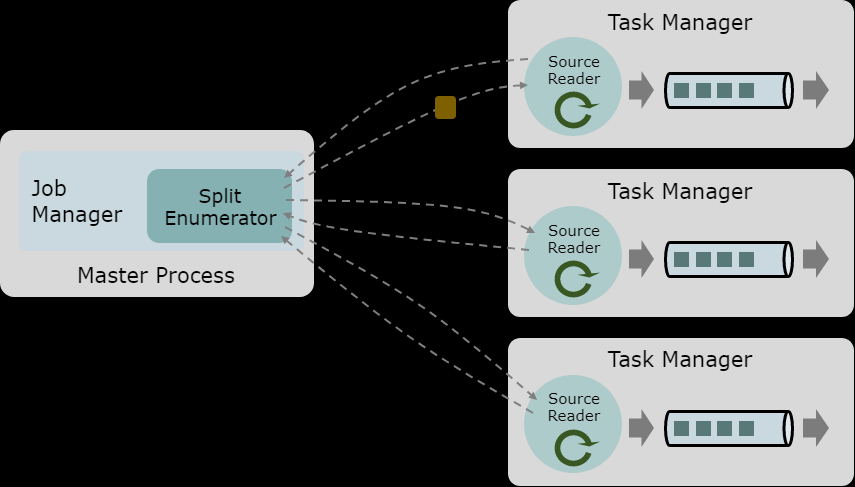
Splits根据其所属文件的修改时间,按修改时间升序转发下游读取。
RedisSource
/**
* @Classname MyRediSource
* @Description TODO
* @Date 2020/7/19 17:27
* @Created by hph
*/
package com.hph.datasource.producer;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.source.RichSourceFunction;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.exceptions.JedisConnectionException;
import java.util.HashMap;
import java.util.Map;
public class MyRedisSource extends RichSourceFunction<HashMap<String, String>> {
private Logger logger = LoggerFactory.getLogger(MyRedisSource.class);
private Jedis jedis = null;
private boolean isRuning =true;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
this.jedis = new Jedis("hadoop102", 6379);
}
@Override
public void run(SourceFunction.SourceContext<HashMap<String, String>> ctx) throws Exception {
HashMap<String, String> KVMap = new HashMap<>();
while (isRuning) {
try {
Map<String, String> mysource = jedis.hgetAll("mysource");
KVMap.clear();
for (Map.Entry<String, String> entry : mysource.entrySet()) {
String key = entry.getKey();
String value = entry.getValue();
String[] splits = value.split(",");
System.out.println("key:" + key + "," + "value:" + value);
for (String split : splits) {
// k v
KVMap.put(key, value);
}
}
if (KVMap.size() > 0) {
ctx.collect(KVMap);
} else {
logger.warn("从redis中获取的数据为空");
}
Thread.sleep(10000);
} catch (JedisConnectionException e) {
logger.warn("redis连接异常,需要重新连接", e.getCause());
jedis = new Jedis("hadoop102", 6379);
} catch (Exception e) {
logger.warn(" source 数据源异常", e.getCause());
}
Thread.sleep(10000);
}
}
@Override
public void cancel() {
try {
isRuning=false;
}catch (Exception e){
logger.warn("redis连接异常,需要重新连接", e.getCause());
jedis.close();
}
}
@Override
public void close() throws Exception {
super.close();
isRuning=false;
while (isRuning) {
jedis.close();
}
}
}Redis数据源
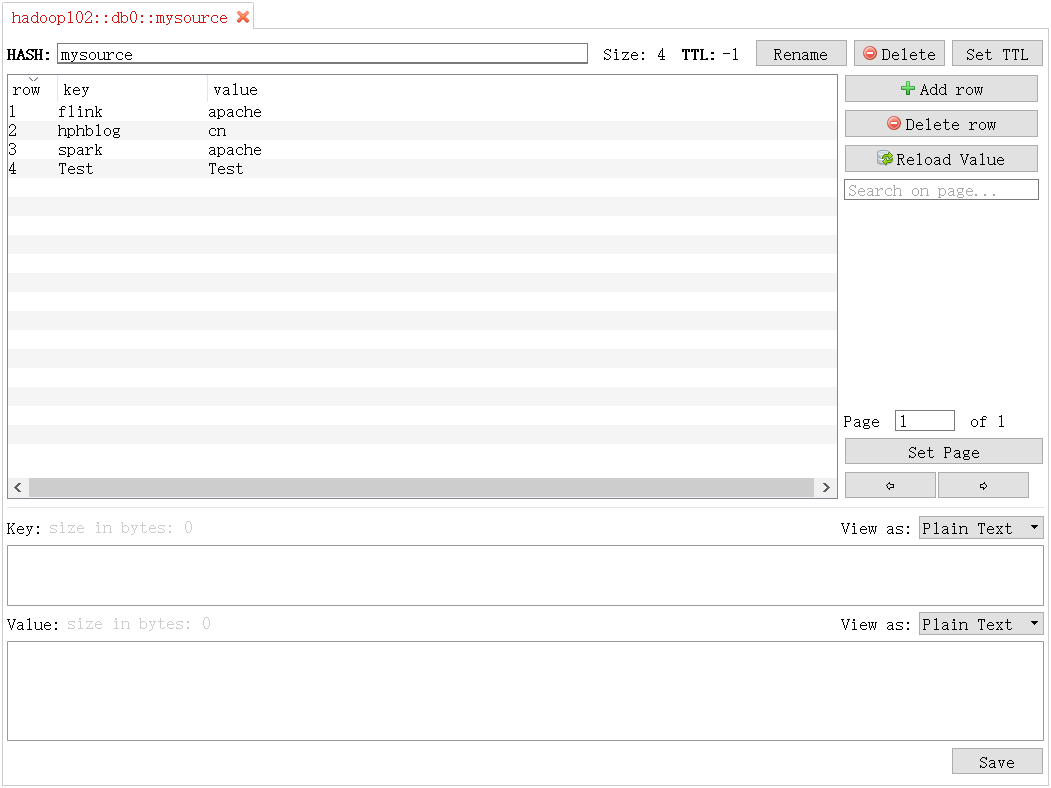
Flink程序
/**
* @Classname MySource
* @Description TODO
* @Date 2020/7/19 17:46
* @Created by hph
*/
package com.hph.datasource;
import com.hph.datasource.producer.MyRedisSource;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.HashMap;
public class MySource {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<HashMap<String, String>> hashMapDataStreamSource = environment.addSource(new MyRedisSource());
hashMapDataStreamSource.print();
environment.execute("MyRedis Source");
}
}
拓展阅读
https://ci.apache.org/projects/flink/flink-docs-master/zh/dev/stream/sources.html

