简介
Flink起源于2010~2014的柏林工业大学、柏林洪堡大学、哈索·普拉特纳研究所联名发起的Stratosphere项目,该项目于2014年捐赠给了Apache软件基金会。2014年12月成为Apache软件基金会的顶级项目。
在德语中Flink表示快速和灵巧。
Flink Log:

与Spark相比Flink是更加纯粹的流式计算,对于Spark来讲、Spark本质上还是基于批计算、即使是Spark Streaming 也是基于微批次计算。
快速体验
安装好Maven执行下面这条命令我们就可以快速开发Flink了
mvn archetype:generate -DarchetypeGroupId=org.apache.flink -DarchetypeArtifactId=flink-quickstart-scala -DarchetypeVersion=1.7.0 -DarchetypeCatlog=local这样会生成两个Scala类,流作业和批作业。
批作业
scala
package com.hph.flink
import org.apache.flink.api.scala.ExecutionEnvironment
object BatchJob {
def main(args: Array[String]) {
// set up the batch execution environment
val env = ExecutionEnvironment.getExecutionEnvironment
val dataset= env.readTextFile("E:\\Words.txt")
import org.apache.flink.api.scala._
val result = dataset.flatMap(_.split(" ")).map((_,1)).groupBy(0).sum(1).print()
}
}如果运行出现这种情况,
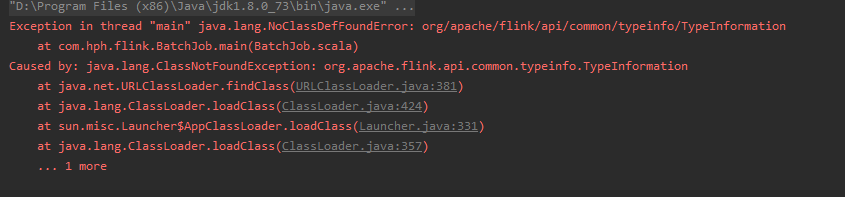
我们需要把IDEA中的
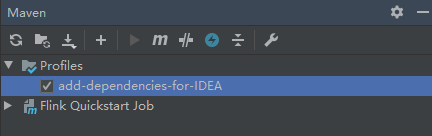
勾选上去。
再次运行结果如图所示:
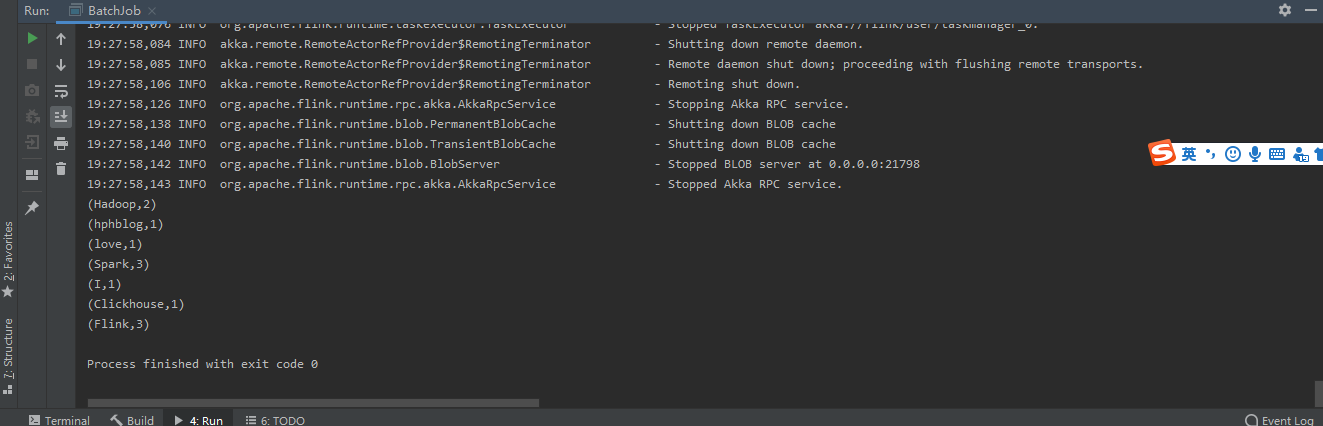
这样我们就轻松的完成了MapReduce中的WordCount。
文件文本如下
Hadoop
Spark
Flink
Flink
Spark
Hadoop
Spark
hphblog
Clickhouse
I love Flink流作业
scala
package com.hph.flink
import org.apache.flink.streaming.api.scala._
object StreamingJob {
def main(args: Array[String]) {
val env = StreamExecutionEnvironment.getExecutionEnvironment
var StreamData = env.socketTextStream("58.87.70.124",9999)
var result = StreamData.flatMap(_.split(" ")).map((_,1)).keyBy(0).sum(1)
result.print()
env.execute("Flink Streaming Scala API Skeleton")
}
}这段代码则是监控hadoop102这台服务器端口为9999的数据信息。
运行一下
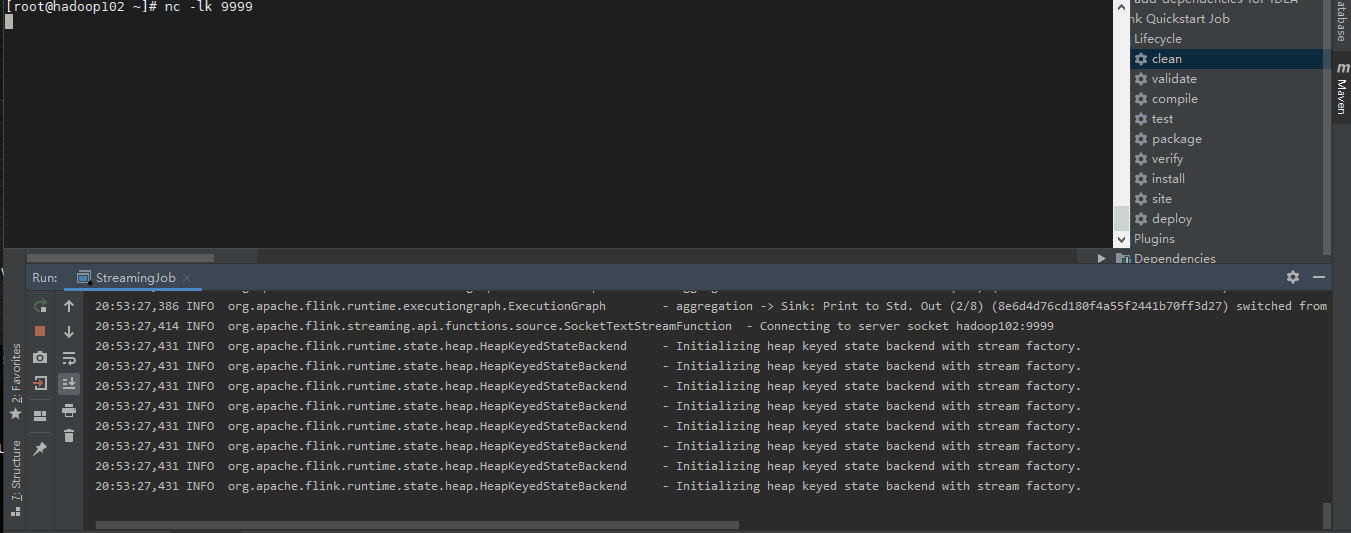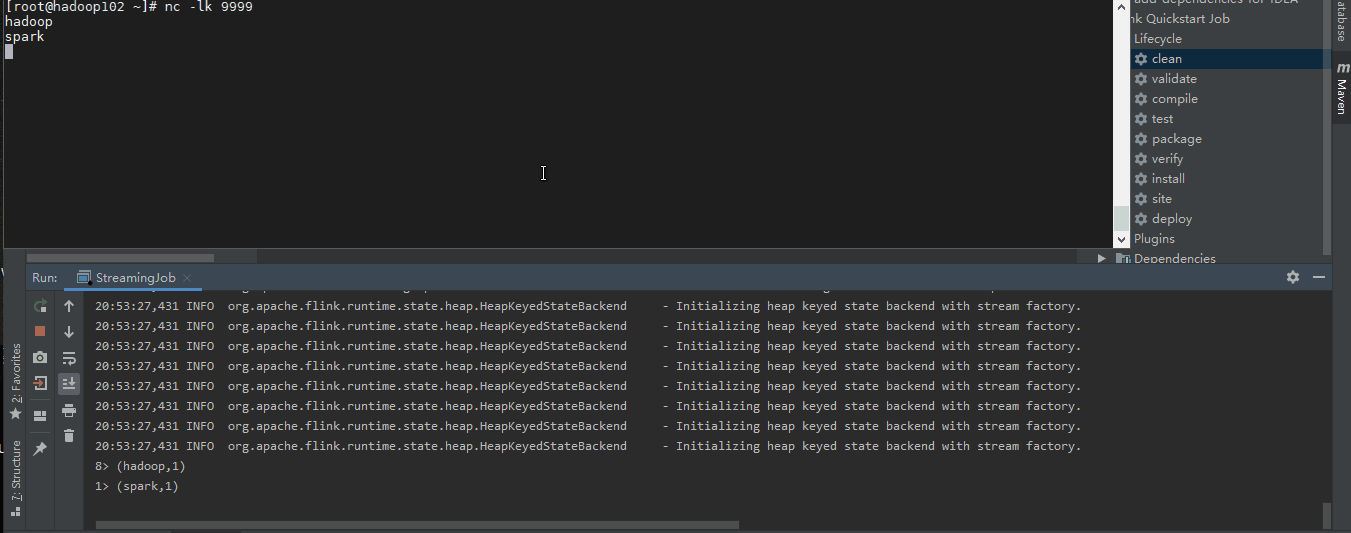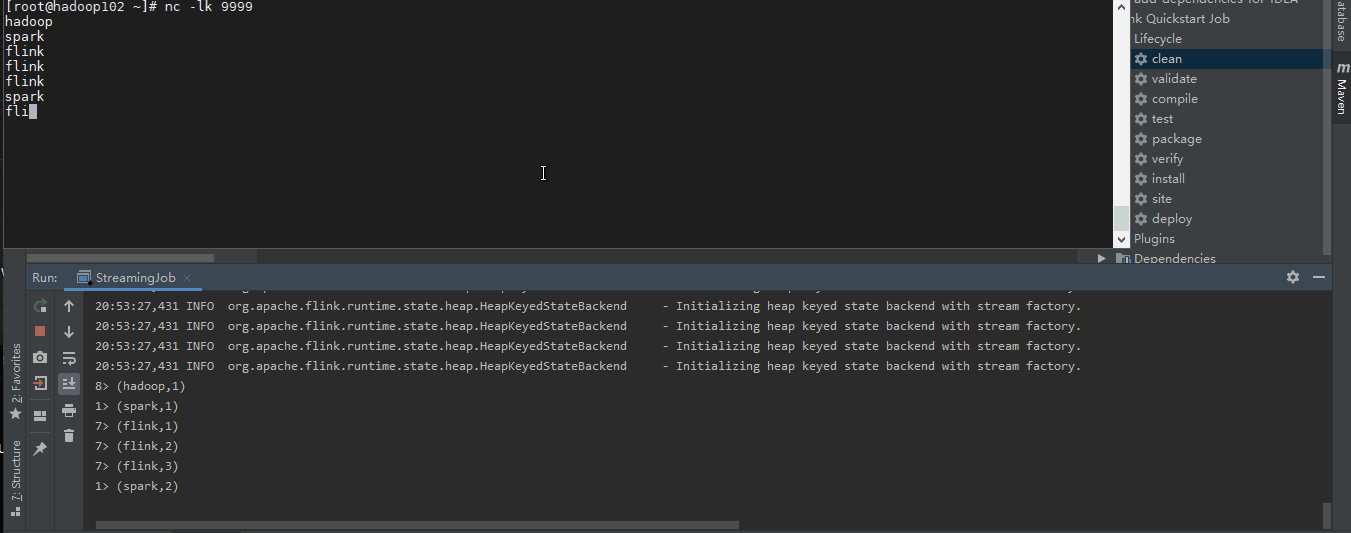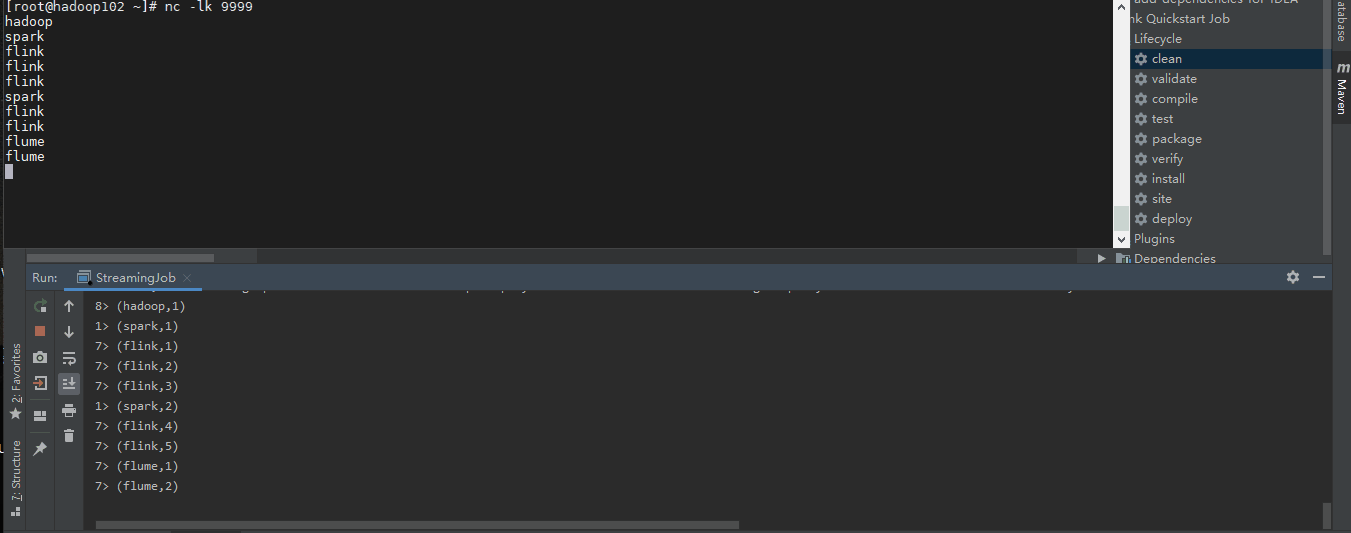
我们轻松的实现了流的有状态统计而且和Spark Streaming 相比Flink 显得更加实时。什么是所谓的状态呢?所谓状态就是计算过程中产生的中间计算结果,每次计算新的数据进入到流式系统中都是基于中间状态结果的基础上进行运算,最终产生正确的统计结果。基于有状态计算的方式最大的优势是不需要将原始数据重新从外部存储中拿出来,从而进行全量计算,因为这种计算方式的代价可能是非常高的。从另一个角度讲,用户无须通过调度和协调各种批量计算工具,从数据仓库中获取数据统计结果,然后再落地存储,这些操作全部都可以基于流式计算完成,可以极大地减轻系统对其他框架的依赖,减少数据计算过程中的时间损耗以及硬件存储。
集群安装
由于虚拟机安装过Haoop Spark 所以我们选择安装的时候可以选择安装与我们Hadoop版本匹配的安装包。
shell
tar -zxvf flink-1.7.2-bin-hadoop27-scala_2.11.tgz -C /opt/module/切换到 /opt/module/flink-1.7.2下,执行
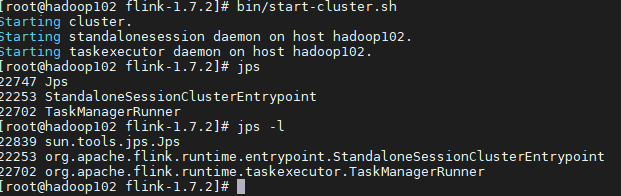
我们可以看到 Flink无需任何配置就可以完成安装,当然这个只是单机版的。访问 hadoop102:8081。
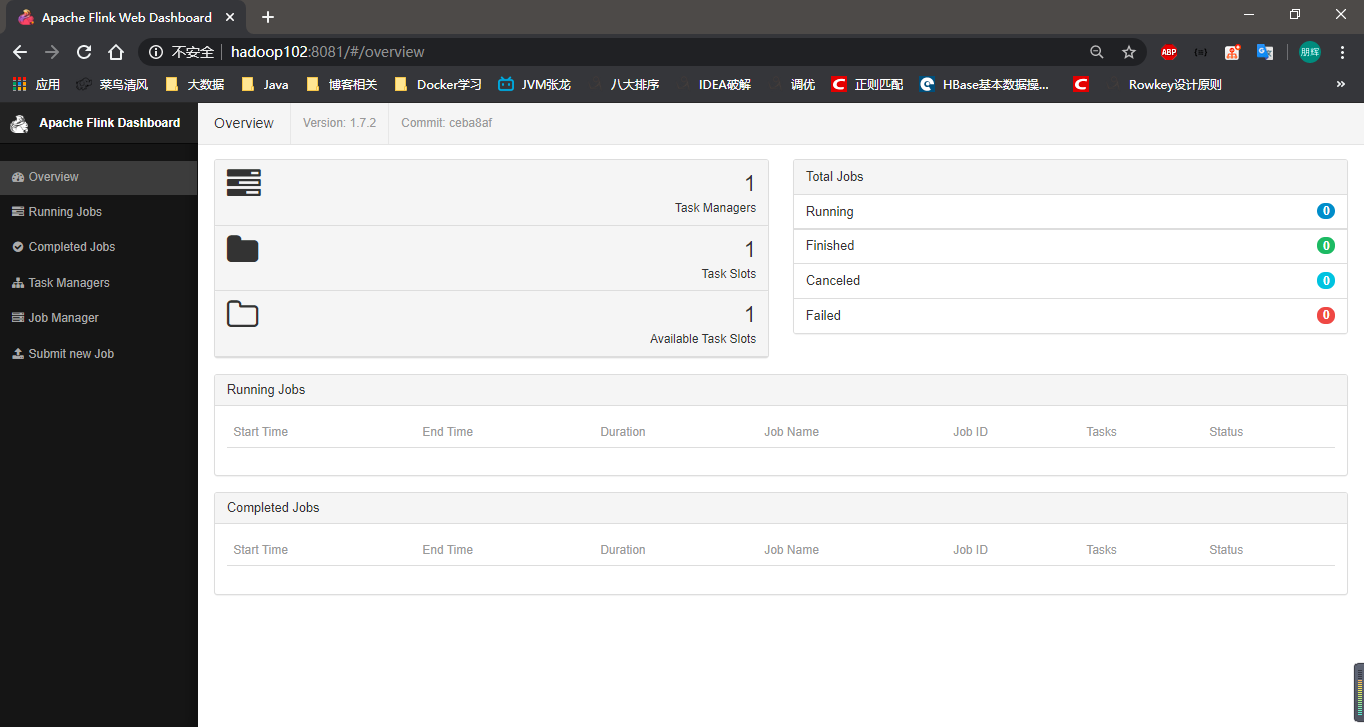
这就是Flink的Web界面。
那么完全集群模式 集成YARN怎么安装呢。
对于Flink来说集群安装十分简单。只需要更改flink-conf.yaml 和slave 文件即可
修改fflink-conf.yaml文件
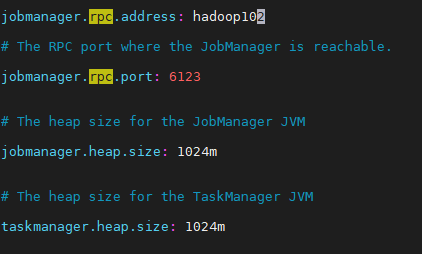
修改salav文件
properties
hadoop102
hadoop103
hadoop104修改masters文件
properties
hadoop102:8081同步脚本如下
shell
#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi
#2 获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname
#3 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4 获取当前用户名称
user=`whoami`
#5 循环
for((host=102; host<105; host++)); do
echo ------------------- hadoop$host --------------
rsync -rvl $pdir/$fname $user@hadoop$host:$pdir
done同步发送flink配置
shell
xsync /opt/module/flink-1.7.2/重新启动Flink
shell
bin/start-cluster.sh打开web界面
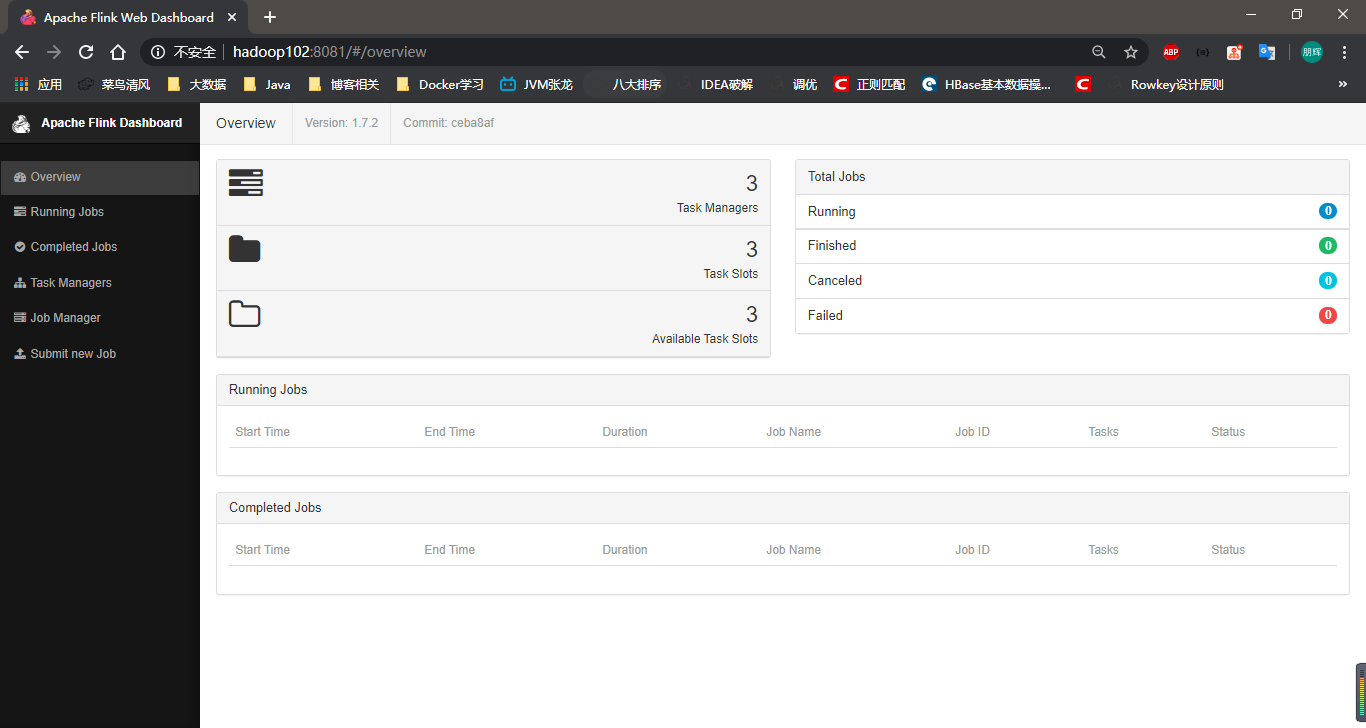
集群安装完成。
作业提交
shell
执行bin/start-scala-shell.sh local 我们就可以进入类似于Spark-shell的界面,这里也出现了可爱的小松鼠
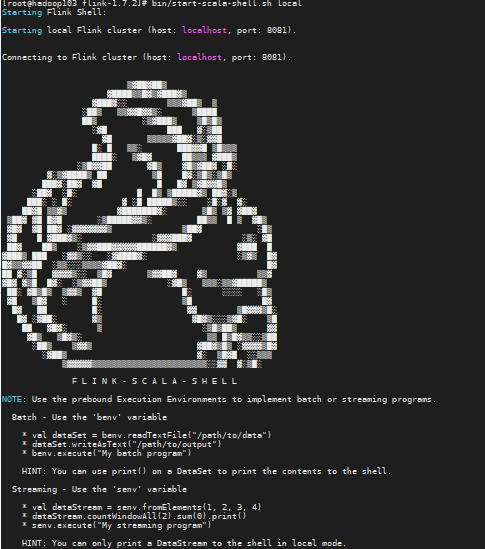
在shell中执行以下命令
scala
//绑定端口数据
var dataStream = senv.socketTextStream("hadoop102",9999)
//处理数据
import org.apache.flink.api.scala._
var result =dataStream.flatMap(_.split(" ")).map((_,1)).keyBy(0).sum(1)
result.print()
senv.execute("Stream Job")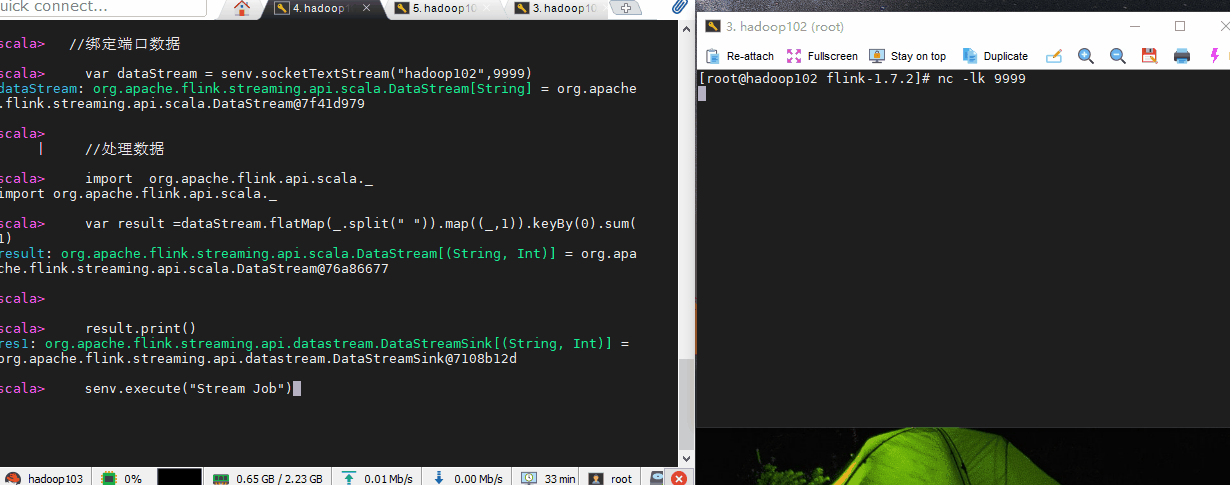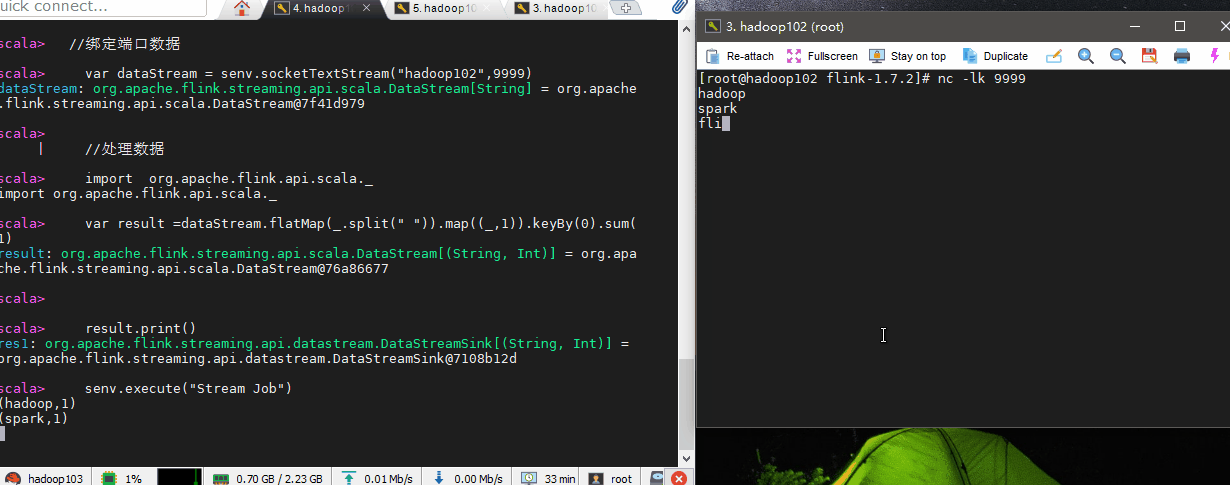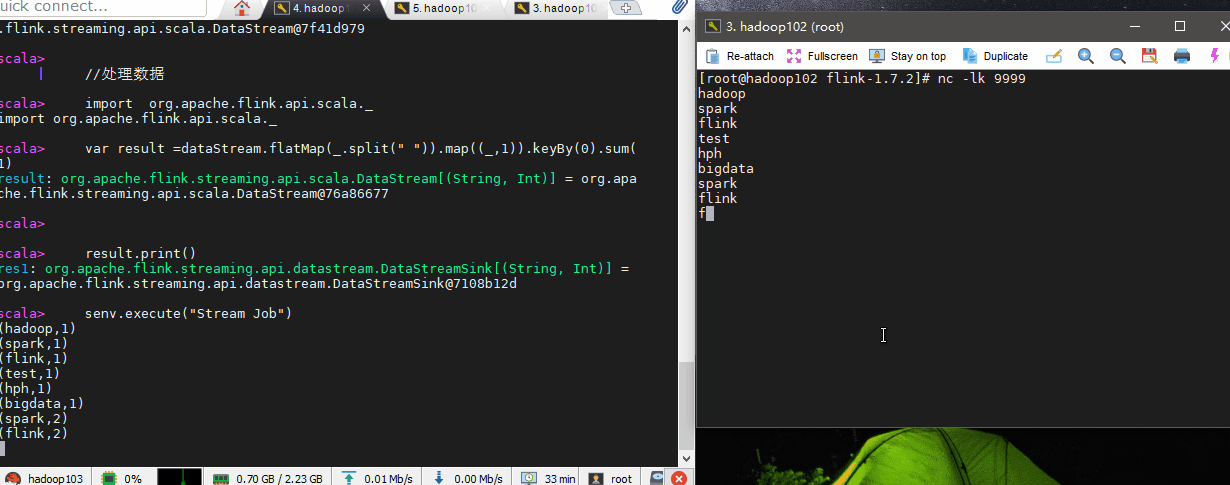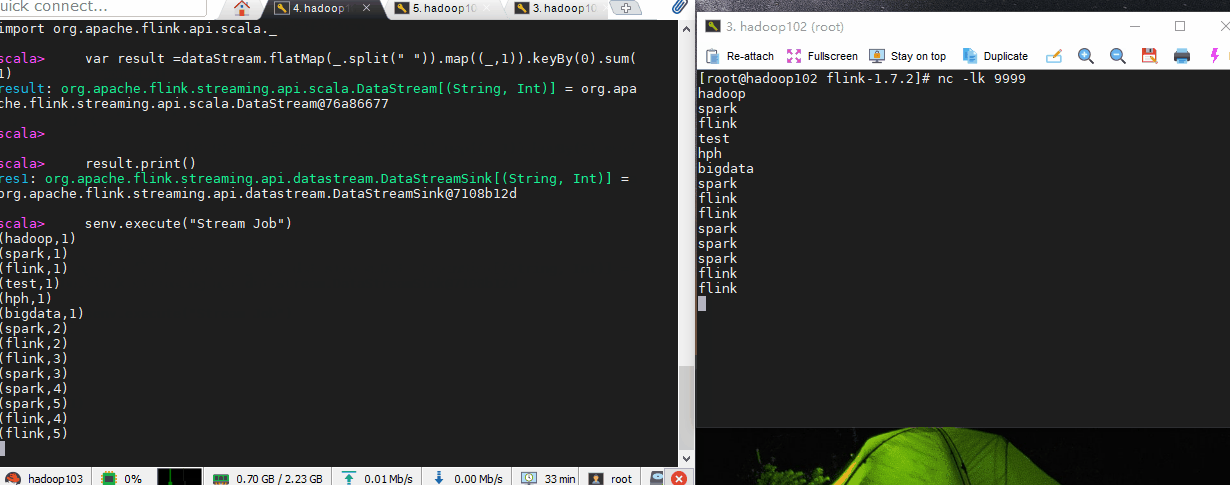
Web界面如下
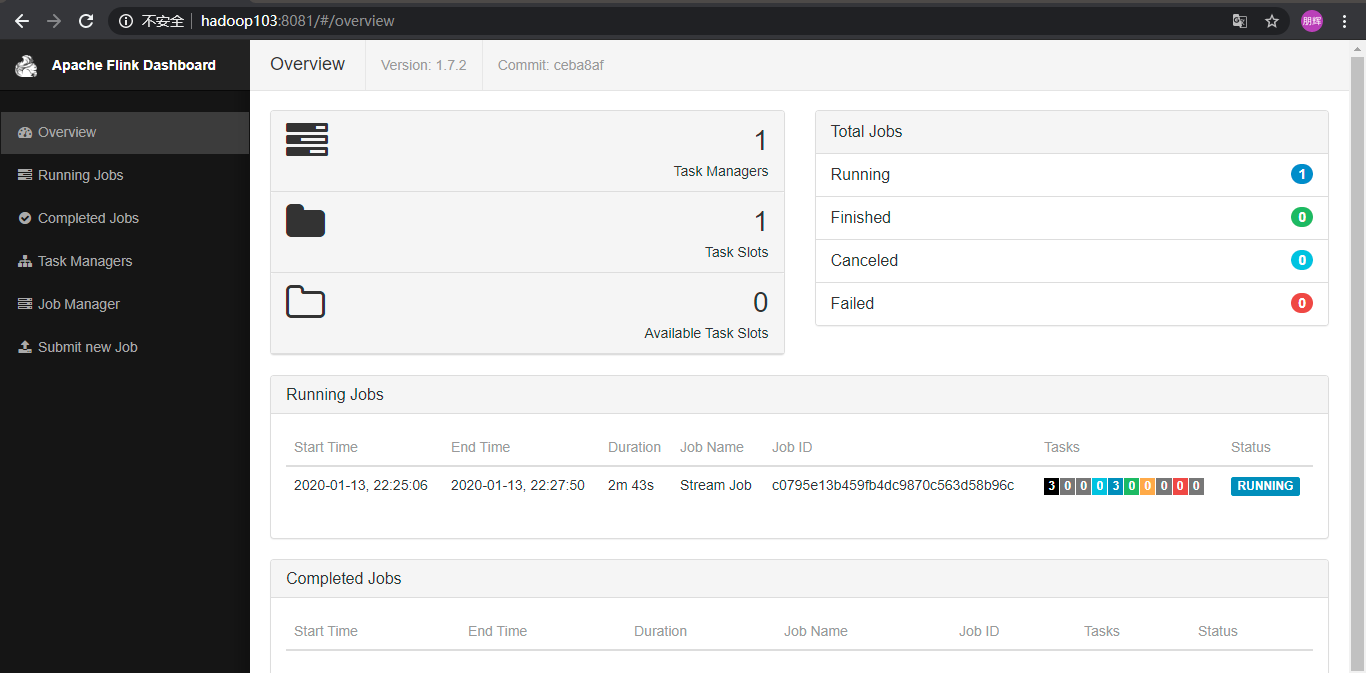
看到了Flink的单机版的Job作业调试如此方便。和Spark-shell一样如此友好,下面我们可以尝试一些常规的生产中的经常使用到的Jar包提交的方式 。
Mavn依赖
创建Maven项目pom包如下
xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.hph.flink.</groupId>
<artifactId>FlinkJob</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>1.7.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-scala -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.2</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- 该插件用于将Scala代码编译成class文件 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.4.6</version>
<executions>
<execution>
<!-- 声明绑定到maven的compile阶段 -->
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>流作业
scala
package com.hph.job
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
object StreamJob {
def main(args: Array[String]): Unit = {
// 从外部命令中获取参数
val params: ParameterTool = ParameterTool.fromArgs(args)
val host: String = params.get("host")
val port: Int = params.getInt("port")
// 创建流处理环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//绑定端口数据
var dataStream = env.socketTextStream("hadoop102",9999)
//处理数据
import org.apache.flink.api.scala._
var result =dataStream.flatMap(_.split(" ")).map((_,1)).keyBy(0).sum(1)
result.print()
env.execute("Stream Job")
}
}WebUI 提交
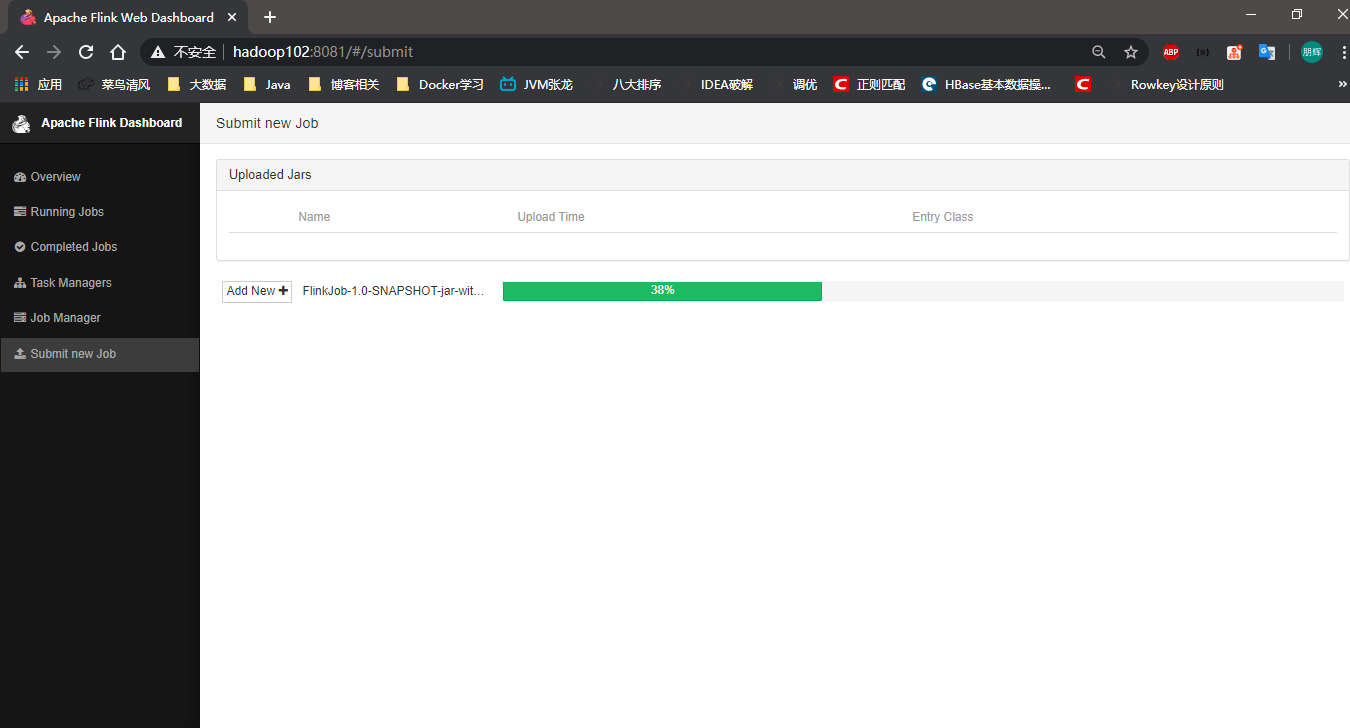
我们把打好的jar包提交到WebUI上看一下
提交jar包
指定一下类名和参数
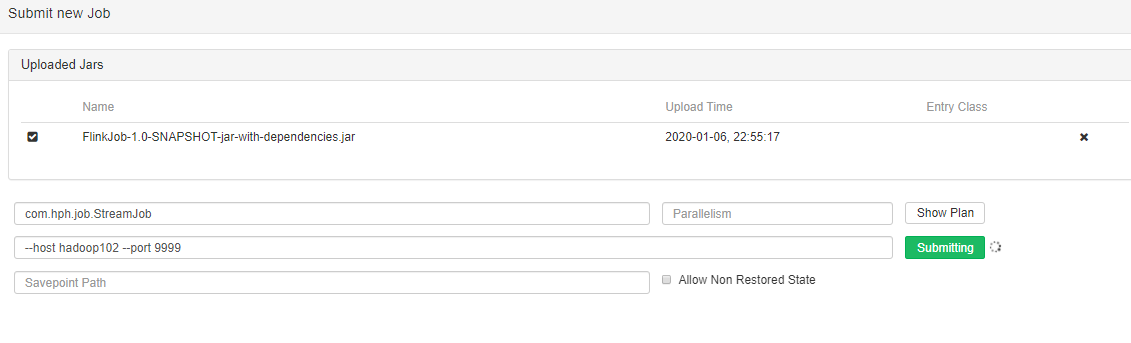
提交作业后则会
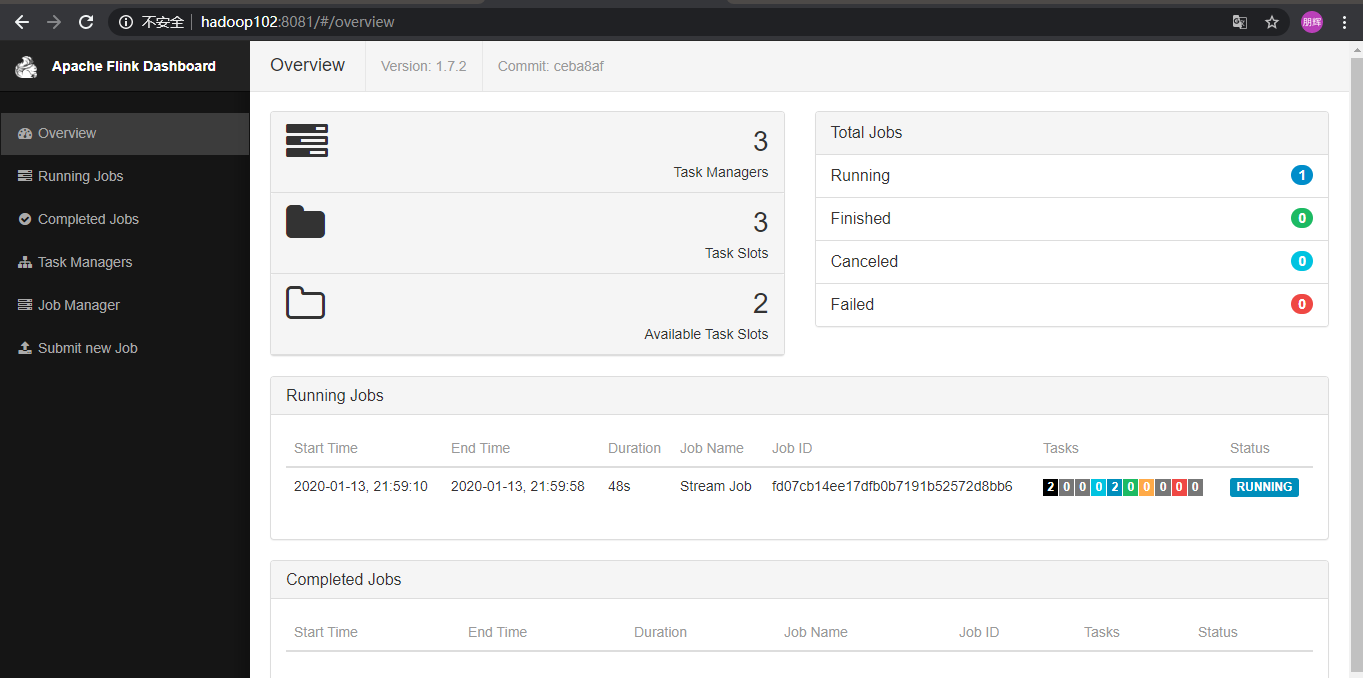
(因为最近电脑出现了问题,这张图今天给大家补上的实在不好意思)
我们在hadoop102服务器上输入几个字符
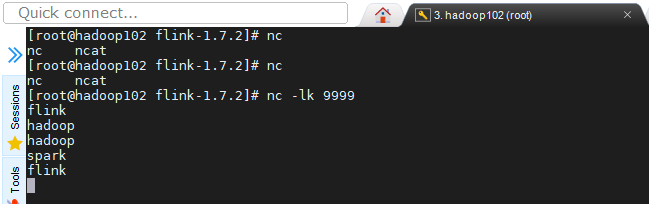
你一定会很好奇结果出现在了哪里,我想你已经猜到了就在Task Manage中这里的TM就相当于干活的人,也就相当于Spark中的Executor。

就这样flink 的流式wordcount就部署起来了。
命令行提交
当然我们也可以使用命令行的方式提交作业这样做起来会更酷。
shell
./flink run -c com.hph.job.StreamJob /opt/module/jars/FlinkJob-1.0-SNAPSHOT-jar-with-dependencies.jar --host hadoop102 --port 9999我们刚才取消掉了那个流式任务现在看一下这个任务
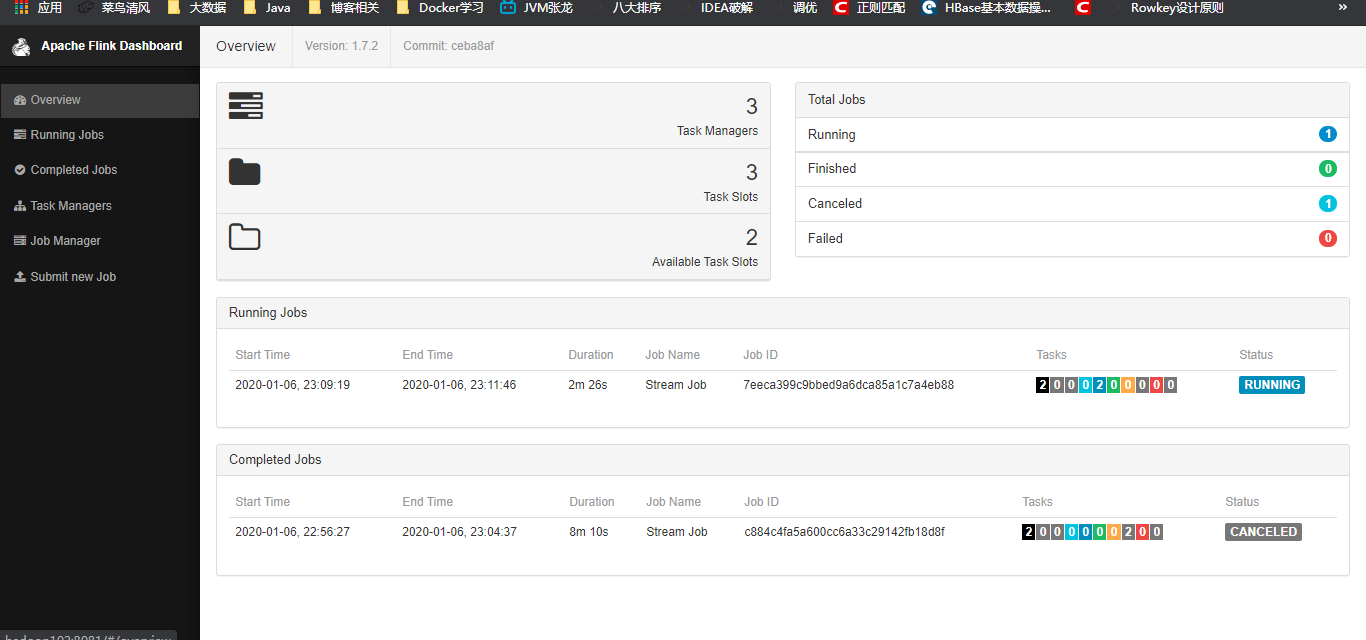
输入几个数据测试一下
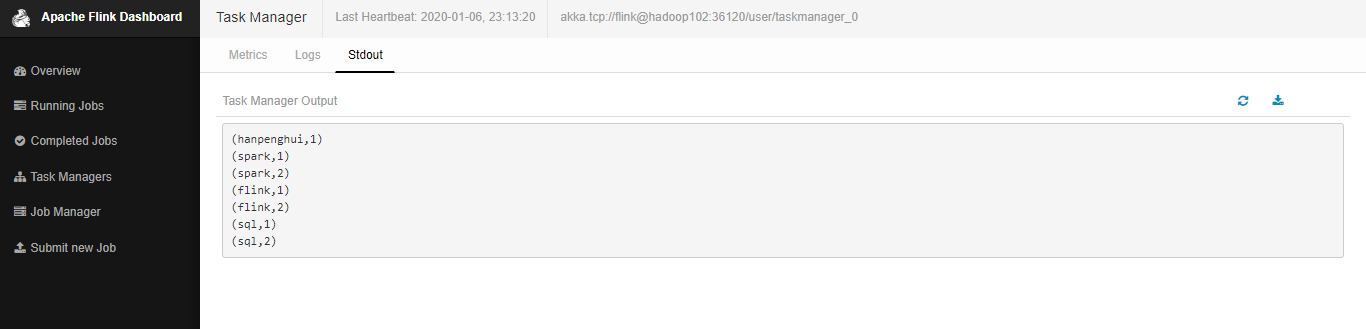
TaskManager下我们发现了刚才的输入的数据计算的结果。
Yarn提交
shell
./flink run -m yarn-cluster -c com.hph.job.StreamJob /ext/flink0503-1.0-SNAPSHOT.jar /opt/module/jars/FlinkJob-1.0-SNAPSHOT-jar-with-dependencies.jar --host hadoop102 --port 9999然而一直再报出
2020-01-06 23:27:44,167 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Deployment took more than 60 seconds. Please check if the requested resources are available in the YARN cluster这是需要我们调整分配的资源因为虚拟机的资源不够所以导致无法申请到相应的资源
shell
./flink run -m yarn-cluster -nm FinkStreamWordCount -c com.hph.job.StreamJob /opt/module/jars/FlinkJob-1.0-SNAPSHOT-jar-with-dependencies.jar -n 1 -s 1 -jm 768 -tm 768 --host hadoop102 --port 9999我们把资源调小,在YARN界面上就可以看到
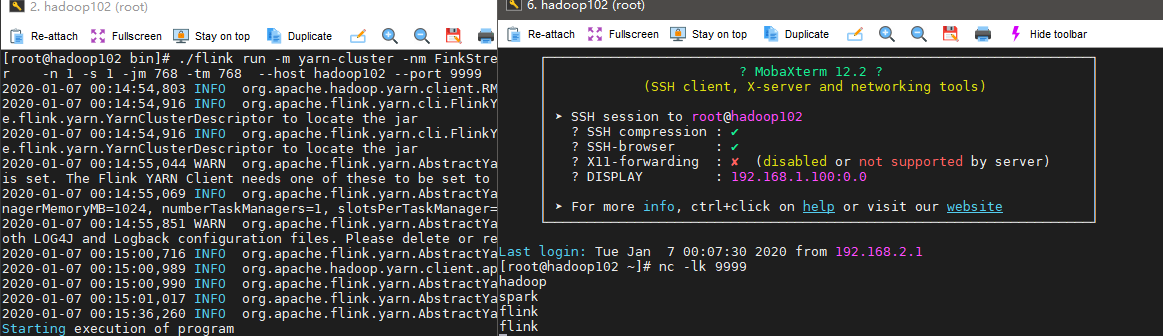
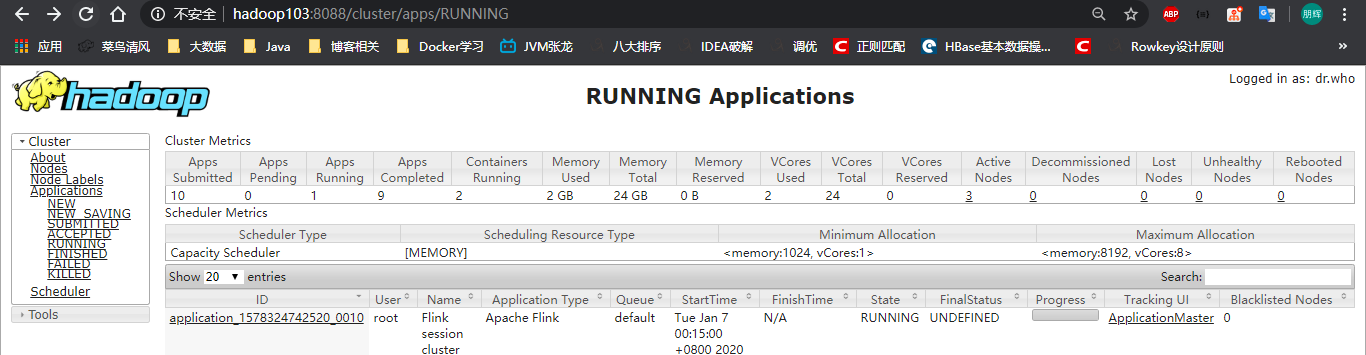
点击ApplicationMaster即可进入Flink Web UI
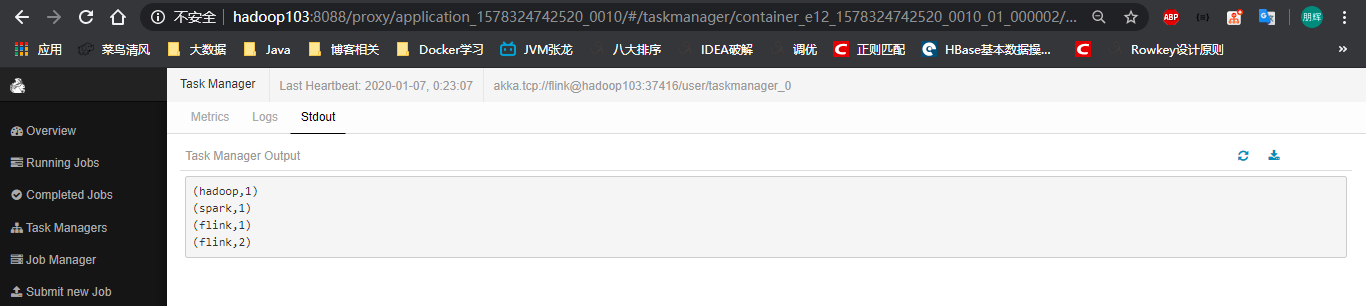
输出结果如上所述。
这样Flink的搭建以及提交作业到Yarn就基本完成了。

