步骤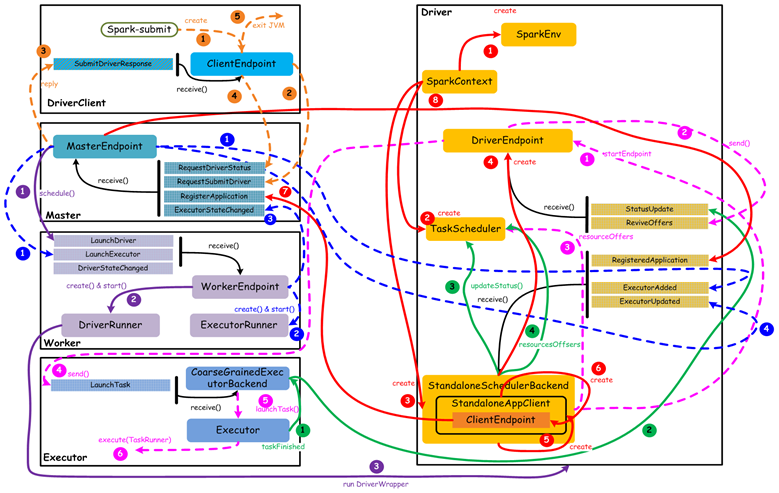
橙色:提交用户Spark程序
- 用户提交一个Spark程序,主要的流程如下所示:
- 用户spark-submit脚本提交一个Spark程序,会创建一个ClientEndpoint对象,该对象负责与Master通信交互
- ClientEndpoint向Master发送一个RequestSubmitDriver消息,表示提交用户程序
- Master收到RequestSubmitDriver消息,向ClientEndpoint回复SubmitDriverResponse,表示用户程序已经完成注册
ClientEndpoint向Master发送RequestDriverStatus消息,请求Driver状态 - 如果当前用户程序对应的Driver已经启动,则ClientEndpoint直接退出,完成提交用户程序
紫色:启动Driver进程
当用户提交用户Spark程序后,需要启动Driver来处理用户程序的计算逻辑,完成计算任务,这时Master协调需要启动一个Driver,具体流程如下所示: - Maser内存中维护着用户提交计算的任务Application,每次内存结构变更都会触发调度,向Worker发送LaunchDriver请求
- Worker收到LaunchDriver消息,会启动一个DriverRunner线程去执行LaunchDriver的任务
- DriverRunner线程在Worker上启动一个新的JVM实例,该JVM实例内运行一个Driver进程,该Driver会创建SparkContext对象
红色:注册Application
Dirver启动以后,它会创建SparkContext对象,初始化计算过程中必需的基本组件,并向Master注册Application,流程描述如下: - 创建SparkEnv对象,创建并管理一些基本组件
- 创建TaskScheduler,负责Task调度
- 创建StandaloneSchedulerBackend,负责与ClusterManager进行资源协商
- 创建DriverEndpoint,其它组件可以与Driver进行通信
- 在StandaloneSchedulerBackend内部创建一个StandaloneAppClient,负责处理与Master的通信交互
- StandaloneAppClient创建一个ClientEndpoint,实际负责与Master通信
- ClientEndpoint向Master发送RegisterApplication消息,注册Application
- Master收到RegisterApplication请求后,回复ClientEndpoint一个RegisteredApplication消息,表示已经注册成功
蓝色:启动Executor进程
1)Master向Worker发送LaunchExecutor消息,请求启动Executor;同时Master会向Driver发送ExecutorAdded消息,表示Master已经新增了一个Executor(此时还未启动) - Worker收到LaunchExecutor消息,会启动一个ExecutorRunner线程去执行LaunchExecutor的任务
- Worker向Master发送ExecutorStageChanged消息,通知Executor状态已发生变化
- Master向Driver发送ExecutorUpdated消息,此时Executor已经启动
粉色:启动Task执行 - StandaloneSchedulerBackend启动一个DriverEndpoint
- DriverEndpoint启动后,会周期性地检查Driver维护的Executor的状态,如果有空闲的Executor便会调度任务执行
- DriverEndpoint向TaskScheduler发送Resource Offer请求
- 如果有可用资源启动Task,则DriverEndpoint向Executor发送LaunchTask请求
- Executor进程内部的CoarseGrainedExecutorBackend调用内部的Executor线程的launchTask方法启动Task
- Executor线程内部维护一个线程池,创建一个TaskRunner线程并提交到线程池执行
绿色:Task运行完成 - Executor进程内部的Executor线程通知CoarseGrainedExecutorBackend,Task运行完成
- CoarseGrainedExecutorBackend向DriverEndpoint发送StatusUpdated消息,通知Driver运行的Task状态发生变更
- StandaloneSchedulerBackend调用TaskScheduler的updateStatus方法更新Task状态
- StandaloneSchedulerBackend继续调用TaskScheduler的resourceOffers方法,调度其他任务运行
应用提交
SparkSubumit
提交任务需要用到SparkSubumit这个类我们先看一下main方法
def main(args: Array[String]): Unit = {
val appArgs = new SparkSubmitArguments(args) //解析参数
if (appArgs.verbose) {
// scalastyle:off println
printStream.println(appArgs)
// scalastyle:on println
}
appArgs.action match {
case SparkSubmitAction.SUBMIT => submit(appArgs) //提交
case SparkSubmitAction.KILL => kill(appArgs) //杀死
case SparkSubmitAction.REQUEST_STATUS => requestStatus(appArgs) //查看状态
}
}我们可以看一下SparkSubmitArguments里面的参数是什么
var master: String = null
var deployMode: String = null
var executorMemory: String = null
var executorCores: String = null
var totalExecutorCores: String = null
var propertiesFile: String = null
var driverMemory: String = null
var driverExtraClassPath: String = null
var driverExtraLibraryPath: String = null
var driverExtraJavaOptions: String = null
var queue: String = null
var numExecutors: String = null
var files: String = null
var archives: String = null
var mainClass: String = null
var primaryResource: String = null
var name: String = null
var childArgs: ArrayBuffer[String] = new ArrayBuffer[String]()
var jars: String = null
var packages: String = null
var repositories: String = null
var ivyRepoPath: String = null
var packagesExclusions: String = null
var verbose: Boolean = false
var isPython: Boolean = false
var pyFiles: String = null
var isR: Boolean = false
var action: SparkSubmitAction = null
val sparkProperties: HashMap[String, String] = new HashMap[String, String]()
var proxyUser: String = null
var principal: String = null
var keytab: String = null
// Standalone cluster mode only
var supervise: Boolean = false
var driverCores: String = null
var submissionToKill: String = null
var submissionToRequestStatusFor: String = null
var useRest: Boolean = true // used internally这些参数在运行的时候我们都可以指定比如
./bin/spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--driver-memory 1g \
--executor-memory 1g \
--executor-cores 1 \
--queue thequeue \
examples/target/scala-2.11/jars/spark-examples*.jar 10| 参数名 | 参数说明 |
|---|---|
| –master | master 的地址,提交任务到哪里执行,例如 spark://host:port, yarn, local |
| –deploy-mode | 在本地 (client) 启动 driver 或在 cluster 上启动,默认是 client |
| –class | 应用程序的主类,仅针对 java 或 scala 应用 |
| –name | 应用程序的名称 |
| –jars | 用逗号分隔的本地 jar 包,设置后,这些 jar 将包含在 driver 和 executor 的 classpath 下 |
| –packages | 包含在driver 和executor 的 classpath 中的 jar 的 maven 坐标 |
| –exclude-packages | 为了避免冲突 而指定不包含的 package |
| –repositories | 远程 repository |
| –conf PROP=VALUE | 指定 spark 配置属性的值, 例如 -conf spark.executor.extraJavaOptions=”-XX:MaxPermSize=256m” |
| –properties-file | 加载的配置文件,默认为 conf/spark-defaults.conf |
| –driver-memory | Driver内存,默认 1G |
| –driver-java-options | 传给 driver 的额外的 Java 选项 |
| –driver-library-path | 传给 driver 的额外的库路径 |
| –driver-class-path | 传给 driver 的额外的类路径 |
| –driver-cores | Driver 的核数,默认是1。在 yarn 或者 standalone 下使用 |
| –executor-memory | 每个 executor 的内存,默认是1G |
| –total-executor-cores | 所有 executor 总共的核数。仅仅在 mesos 或者 standalone 下使用 |
| –num-executors | 启动的 executor 数量。默认为2。在 yarn 下使用 |
| –executor-core | 每个 executor 的核数。在yarn或者standalone下使用 |
submit
@tailrec
private def submit(args: SparkSubmitArguments): Unit = {
//根据参数准备提交应用时所需的环境
val (childArgs, childClasspath, sysProps, childMainClass) = prepareSubmitEnvironment(args)
def doRunMain(): Unit = {
if (args.proxyUser != null) {
val proxyUser = UserGroupInformation.createProxyUser(args.proxyUser,
UserGroupInformation.getCurrentUser())
try {
proxyUser.doAs(new PrivilegedExceptionAction[Unit]() {
override def run(): Unit = {
runMain(childArgsm, childClasspath, sysProps, childMainClass, args.verbose)
}
})
} catch {
case e: Exception =>
// Hadoop's AuthorizationException suppresses the exception's stack trace, which
// makes the message printed to the output by the JVM not very helpful. Instead,
// detect exceptions with empty stack traces here, and treat them differently.
if (e.getStackTrace().length == 0) {
// scalastyle:off println
printStream.println(s"ERROR: ${e.getClass().getName()}: ${e.getMessage()}")
// scalastyle:on println
exitFn(1)
} else {
throw e
}
}
} else {
runMain(childArgs, childClasspath, sysProps, childMainClass, args.verbose)
}
}
// In standalone cluster mode, there are two submission gateways:
// (1) The traditional RPC gateway using o.a.s.deploy.Client as a wrapper
// (2) The new REST-based gateway introduced in Spark 1.3
// The latter is the default behavior as of Spark 1.3, but Spark submit will fail over
// to use the legacy gateway if the master endpoint turns out to be not a REST server.
if (args.isStandaloneCluster && args.useRest) {
try {
// scalastyle:off println
printStream.println("Running Spark using the REST application submission protocol.")
// scalastyle:on println
doRunMain() //调用doRunMain
} catch {
// Fail over to use the legacy submission gateway
case e: SubmitRestConnectionException =>
printWarning(s"Master endpoint ${args.master} was not a REST server. " +
"Falling back to legacy submission gateway instead.")
args.useRest = false
submit(args)
}
// In all other modes, just run the main class as prepared
} else {
doRunMain() //doRunMain
}
}runMain
private def runMain(
childArgs: Seq[String],
childClasspath: Seq[String],
sysProps: Map[String, String],
childMainClass: String,
verbose: Boolean): Unit = {
// scalastyle:off println
if (verbose) { //如果打开调试 则会输出
printStream.println(s"Main class:\n$childMainClass")
printStream.println(s"Arguments:\n${childArgs.mkString("\n")}")
printStream.println(s"System properties:\n${sysProps.mkString("\n")}")
printStream.println(s"Classpath elements:\n${childClasspath.mkString("\n")}")
printStream.println("\n")
}
// scalastyle:on println
val loader =
if (sysProps.getOrElse("spark.driver.userClassPathFirst", "false").toBoolean) {
new ChildFirstURLClassLoader(new Array[URL](0),
Thread.currentThread.getContextClassLoader)
} else {
new MutableURLClassLoader(new Array[URL](0),
Thread.currentThread.getContextClassLoader)
}
Thread.currentThread.setContextClassLoader(loader)
for (jar <- childClasspath) {
addJarToClasspath(jar, loader) //添加jar包到类路径下
}
for ((key, value) <- sysProps) {
System.setProperty(key, value) //sysProps 添加到 System
}
var mainClass: Class[_] = null
try {
mainClass = Utils.classForName(childMainClass) //利用了反射childMainClass得到mainClass
} catch {
case e: ClassNotFoundException => //异常ClassNotFoundException
e.printStackTrace(printStream)
if (childMainClass.contains("thriftserver")) {
// scalastyle:off println
printStream.println(s"Failed to load main class $childMainClass.")
printStream.println("You need to build Spark with -Phive and -Phive-thriftserver.")
// scalastyle:on println
}
System.exit(CLASS_NOT_FOUND_EXIT_STATUS)
case e: NoClassDefFoundError =>
e.printStackTrace(printStream)
if (e.getMessage.contains("org/apache/hadoop/hive")) {
// scalastyle:off println
printStream.println(s"Failed to load hive class.")
printStream.println("You need to build Spark with -Phive and -Phive-thriftserver.")
// scalastyle:on println
}
System.exit(CLASS_NOT_FOUND_EXIT_STATUS)
}
// SPARK-4170 BUG 尚未解决的 缺陷跟踪
if (classOf[scala.App].isAssignableFrom(mainClass)) {
printWarning("Subclasses of scala.App may not work correctly. Use a main() method instead.")
}
//get 一个 main 方法
val mainMethod = mainClass.getMethod("main", new Array[String](0).getClass)
if (!Modifier.isStatic(mainMethod.getModifiers)) {
throw new IllegalStateException("The main method in the given main class must be static")
}
@tailrec
def findCause(t: Throwable): Throwable = t match {
case e: UndeclaredThrowableException =>
if (e.getCause() != null) findCause(e.getCause()) else e
case e: InvocationTargetException =>
if (e.getCause() != null) findCause(e.getCause()) else e
case e: Throwable =>
e
}
try {
//反射执行通过childArgs
mainMethod.invoke(null, childArgs.toArray)
} catch {
case t: Throwable =>
findCause(t) match {
case SparkUserAppException(exitCode) =>
System.exit(exitCode)
case t: Throwable =>
throw t
}
}
}由于mainClass利用了反射我们需要寻找一下childMainClass 注意观察 submit方法中 val (childArgs, childClasspath, sysProps, childMainClass) = prepareSubmitEnvironment(args)我们查看一下prepareSubmitEnvironment
prepareSubmitEnvironment
private[deploy] def prepareSubmitEnvironment(args: SparkSubmitArguments)
: (Seq[String], Seq[String], Map[String, String], String) = {
// Return values
val childArgs = new ArrayBuffer[String]()
val childClasspath = new ArrayBuffer[String]()
val sysProps = new HashMap[String, String]()
var childMainClass = "" //目标出现
// Set the cluster manager
val clusterManager: Int = args.master match {
case "yarn" => YARN
case "yarn-client" | "yarn-cluster" =>
printWarning(s"Master ${args.master} is deprecated since 2.0." +
" Please use master \"yarn\" with specified deploy mode instead.")
YARN
case m if m.startsWith("spark") => STANDALONE
case m if m.startsWith("mesos") => MESOS
case m if m.startsWith("local") => LOCAL
case _ =>
printErrorAndExit("Master must either be yarn or start with spark, mesos, local")
-1
}
// Set the deploy mode; default is client mode 设置 deploy 模式
var deployMode: Int = args.deployMode match {
case "client" | null => CLIENT // 如果是NULL 或者 "client" 默认为CLIENT
case "cluster" => CLUSTER
case _ => printErrorAndExit("Deploy mode must be either client or cluster"); -1
}
// Because the deprecated way of specifying "yarn-cluster" and "yarn-client" encapsulate both
// the master and deploy mode, we have some logic to infer the master and deploy mode
// from each other if only one is specified, or exit early if they are at odds.
if (clusterManager == YARN) { //如果是YARN模式
(args.master, args.deployMode) match {
case ("yarn-cluster", null) =>
deployMode = CLUSTER
args.master = "yarn"
case ("yarn-cluster", "client") =>
printErrorAndExit("Client deploy mode is not compatible with master \"yarn-cluster\"")
case ("yarn-client", "cluster") =>
printErrorAndExit("Cluster deploy mode is not compatible with master \"yarn-client\"")
case (_, mode) =>
args.master = "yarn"
}
// Make sure YARN is included in our build if we're trying to use it
if (!Utils.classIsLoadable("org.apache.spark.deploy.yarn.Client") && !Utils.isTesting) {
printErrorAndExit(
"Could not load YARN classes. " +
"This copy of Spark may not have been compiled with YARN support.")
}
}
// Update args.deployMode if it is null. It will be passed down as a Spark property later.
(args.deployMode, deployMode) match {
case (null, CLIENT) => args.deployMode = "client"
case (null, CLUSTER) => args.deployMode = "cluster"
case _ =>
}
val isYarnCluster = clusterManager == YARN && deployMode == CLUSTER
val isMesosCluster = clusterManager == MESOS && deployMode == CLUSTER
.....
// A list of rules to map each argument to system properties or command-line options in
// each deploy mode; we iterate through these below
val options = List[OptionAssigner]( // 整理一下 options 把参数聚集到了一块
// All cluster managers
OptionAssigner(args.master, ALL_CLUSTER_MGRS, ALL_DEPLOY_MODES, sysProp = "spark.master"),
OptionAssigner(args.deployMode, ALL_CLUSTER_MGRS, ALL_DEPLOY_MODES,
sysProp = "spark.submit.deployMode"),
OptionAssigner(args.name, ALL_CLUSTER_MGRS, ALL_DEPLOY_MODES, sysProp = "spark.app.name"),
OptionAssigner(args.ivyRepoPath, ALL_CLUSTER_MGRS, CLIENT, sysProp = "spark.jars.ivy"),
OptionAssigner(args.driverMemory, ALL_CLUSTER_MGRS, CLIENT,
sysProp = "spark.driver.memory"),
OptionAssigner(args.driverExtraClassPath, ALL_CLUSTER_MGRS, ALL_DEPLOY_MODES,
sysProp = "spark.driver.extraClassPath"),
OptionAssigner(args.driverExtraJavaOptions, ALL_CLUSTER_MGRS, ALL_DEPLOY_MODES,
sysProp = "spark.driver.extraJavaOptions"),
OptionAssigner(args.driverExtraLibraryPath, ALL_CLUSTER_MGRS, ALL_DEPLOY_MODES,
sysProp = "spark.driver.extraLibraryPath"),
// Yarn only
OptionAssigner(args.queue, YARN, ALL_DEPLOY_MODES, sysProp = "spark.yarn.queue"),
OptionAssigner(args.numExecutors, YARN, ALL_DEPLOY_MODES,
sysProp = "spark.executor.instances"),
OptionAssigner(args.jars, YARN, ALL_DEPLOY_MODES, sysProp = "spark.yarn.dist.jars"),
OptionAssigner(args.files, YARN, ALL_DEPLOY_MODES, sysProp = "spark.yarn.dist.files"),
OptionAssigner(args.archives, YARN, ALL_DEPLOY_MODES, sysProp = "spark.yarn.dist.archives"),
OptionAssigner(args.principal, YARN, ALL_DEPLOY_MODES, sysProp = "spark.yarn.principal"),
OptionAssigner(args.keytab, YARN, ALL_DEPLOY_MODES, sysProp = "spark.yarn.keytab"),
// Other options
OptionAssigner(args.executorCores, STANDALONE | YARN, ALL_DEPLOY_MODES,
sysProp = "spark.executor.cores"),
OptionAssigner(args.executorMemory, STANDALONE | MESOS | YARN, ALL_DEPLOY_MODES,
sysProp = "spark.executor.memory"),
OptionAssigner(args.totalExecutorCores, STANDALONE | MESOS, ALL_DEPLOY_MODES,
sysProp = "spark.cores.max"),
OptionAssigner(args.files, LOCAL | STANDALONE | MESOS, ALL_DEPLOY_MODES,
sysProp = "spark.files"),
OptionAssigner(args.jars, LOCAL, CLIENT, sysProp = "spark.jars"),
OptionAssigner(args.jars, STANDALONE | MESOS, ALL_DEPLOY_MODES, sysProp = "spark.jars"),
OptionAssigner(args.driverMemory, STANDALONE | MESOS | YARN, CLUSTER,
sysProp = "spark.driver.memory"),
OptionAssigner(args.driverCores, STANDALONE | MESOS | YARN, CLUSTER,
sysProp = "spark.driver.cores"),
OptionAssigner(args.supervise.toString, STANDALONE | MESOS, CLUSTER,
sysProp = "spark.driver.supervise"),
OptionAssigner(args.ivyRepoPath, STANDALONE, CLUSTER, sysProp = "spark.jars.ivy")
)
// In client mode, launch the application main class directly
// In addition, add the main application jar and any added jars (if any) to the classpath
// Also add the main application jar and any added jars to classpath in case YARN client
// requires these jars.
if (deployMode == CLIENT || isYarnCluster) {
childMainClass = args.mainClass
if (isUserJar(args.primaryResource)) {
childClasspath += args.primaryResource
}
if (args.jars != null) { childClasspath ++= args.jars.split(",") }
}
if (deployMode == CLIENT) {
if (args.childArgs != null) { childArgs ++= args.childArgs }
}
// Map all arguments to command-line options or system properties for our chosen mode
for (opt <- options) {
if (opt.value != null &&
(deployMode & opt.deployMode) != 0 &&
(clusterManager & opt.clusterManager) != 0) {
if (opt.clOption != null) { childArgs += (opt.clOption, opt.value) }
if (opt.sysProp != null) { sysProps.put(opt.sysProp, opt.value) }
}
}
// Add the application jar automatically so the user doesn't have to call sc.addJar
// For YARN cluster mode, the jar is already distributed on each node as "app.jar"
// For python and R files, the primary resource is already distributed as a regular file
if (!isYarnCluster && !args.isPython && !args.isR) {
var jars = sysProps.get("spark.jars").map(x => x.split(",").toSeq).getOrElse(Seq.empty)
if (isUserJar(args.primaryResource)) {
jars = jars ++ Seq(args.primaryResource)
}
sysProps.put("spark.jars", jars.mkString(","))
}
// In standalone cluster mode, use the REST client to submit the application (Spark 1.3+).
// All Spark parameters are expected to be passed to the client through system properties.
if (args.isStandaloneCluster) { //如果使用的是Standalone集群模式
if (args.useRest) { //如果用了useRest
childMainClass = "org.apache.spark.deploy.rest.RestSubmissionClient"
childArgs += (args.primaryResource, args.mainClass)
} else { //如果没有用如useRest
// In legacy standalone cluster mode, use Client as a wrapper around the user class
childMainClass = "org.apache.spark.deploy.Client" //这个类使用到了Client 类
if (args.supervise) { childArgs += "--supervise" }
Option(args.driverMemory).foreach { m => childArgs += ("--memory", m) }
Option(args.driverCores).foreach { c => childArgs += ("--cores", c) }
childArgs += "launch"
childArgs += (args.master, args.primaryResource, args.mainClass)
}
if (args.childArgs != null) {
childArgs ++= args.childArgs
}
}
// Let YARN know it's a pyspark app, so it distributes needed libraries.
if (clusterManager == YARN) {
if (args.isPython) {
sysProps.put("spark.yarn.isPython", "true")
}
if (args.pyFiles != null) {
sysProps("spark.submit.pyFiles") = args.pyFiles
}
}
// assure a keytab is available from any place in a JVM
if (clusterManager == YARN || clusterManager == LOCAL) {
if (args.principal != null) {
require(args.keytab != null, "Keytab must be specified when principal is specified")
if (!new File(args.keytab).exists()) {
throw new SparkException(s"Keytab file: ${args.keytab} does not exist")
} else {
// Add keytab and principal configurations in sysProps to make them available
// for later use; e.g. in spark sql, the isolated class loader used to talk
// to HiveMetastore will use these settings. They will be set as Java system
// properties and then loaded by SparkConf
sysProps.put("spark.yarn.keytab", args.keytab)
sysProps.put("spark.yarn.principal", args.principal)
UserGroupInformation.loginUserFromKeytab(args.principal, args.keytab)
}
}
}
// In yarn-cluster mode, use yarn.Client as a wrapper around the user class
if (isYarnCluster) {
childMainClass = "org.apache.spark.deploy.yarn.Client" //我们重点关注一下
if (args.isPython) {
childArgs += ("--primary-py-file", args.primaryResource)
childArgs += ("--class", "org.apache.spark.deploy.PythonRunner")
} else if (args.isR) {
val mainFile = new Path(args.primaryResource).getName
childArgs += ("--primary-r-file", mainFile)
childArgs += ("--class", "org.apache.spark.deploy.RRunner")
} else {
if (args.primaryResource != SparkLauncher.NO_RESOURCE) {
childArgs += ("--jar", args.primaryResource)
}
childArgs += ("--class", args.mainClass)
}
if (args.childArgs != null) {
args.childArgs.foreach { arg => childArgs += ("--arg", arg) }
}
}
if (isMesosCluster) {
.....
}
// Load any properties specified through --conf and the default properties file
for ((k, v) <- args.sparkProperties) {
sysProps.getOrElseUpdate(k, v)
}
// Ignore invalid spark.driver.host in cluster modes.
if (deployMode == CLUSTER) {
sysProps -= "spark.driver.host"
}
// Resolve paths in certain spark properties
val pathConfigs = Seq(
"spark.jars",
"spark.files",
"spark.yarn.dist.files",
"spark.yarn.dist.archives",
"spark.yarn.dist.jars")
pathConfigs.foreach { config =>
// Replace old URIs with resolved URIs, if they exist
sysProps.get(config).foreach { oldValue =>
sysProps(config) = Utils.resolveURIs(oldValue)
}
}
// Resolve and format python file paths properly before adding them to the PYTHONPATH.
// The resolving part is redundant in the case of --py-files, but necessary if the user
// explicitly sets `spark.submit.pyFiles` in his/her default properties file.
sysProps.get("spark.submit.pyFiles").foreach { pyFiles =>
val resolvedPyFiles = Utils.resolveURIs(pyFiles)
val formattedPyFiles = if (!isYarnCluster && !isMesosCluster) {
PythonRunner.formatPaths(resolvedPyFiles).mkString(",")
} else {
// Ignoring formatting python path in yarn and mesos cluster mode, these two modes
// support dealing with remote python files, they could distribute and add python files
// locally.
resolvedPyFiles
}
sysProps("spark.submit.pyFiles") = formattedPyFiles
}
(childArgs, childClasspath, sysProps, childMainClass)
}Client
反射执行的main方法应该是Client的main方法
object Client {
def main(args: Array[String]) {
// scalastyle:off println
if (!sys.props.contains("SPARK_SUBMIT")) {
println("WARNING: This client is deprecated and will be removed in a future version of Spark") //未来client 可能会被弃用
println("Use ./bin/spark-submit with \"--master spark://host:port\"")
}
// scalastyle:on println
val conf = new SparkConf()
val driverArgs = new ClientArguments(args)
if (!conf.contains("spark.rpc.askTimeout")) {
conf.set("spark.rpc.askTimeout", "10s") //设置rpc的超时时间
}
Logger.getRootLogger.setLevel(driverArgs.logLevel)
val rpcEnv = //创建 rpcEnv 需要主动和Master 发消息
RpcEnv.create("driverClient", Utils.localHostName(), 0, conf, new SecurityManager(conf))
val masterEndpoints = driverArgs.masters.map(RpcAddress.fromSparkURL). //创建masterEndpoints
map(rpcEnv.setupEndpointRef(_, Master.ENDPOINT_NAME)) //获取master的Ref
//给自己启动一个ClientEndpoint
rpcEnv.setupEndpoint("client", new ClientEndpoint(rpcEnv, driverArgs, masterEndpoints, conf))
rpcEnv.awaitTermination()
}
}ClientEndpoint
我们需要查看一下ClientEndpoint
private class ClientEndpoint(
override val rpcEnv: RpcEnv,
driverArgs: ClientArguments,
masterEndpoints: Seq[RpcEndpointRef],
conf: SparkConf)
extends ThreadSafeRpcEndpoint with Logging { //继承了ThreadSafeRpcEndpoint 我们关注一下具体方法
....
override def onStart(): Unit = {
driverArgs.cmd match {
case "launch" => //是launch
// TODO: We could add an env variable here and intercept it in `sc.addJar` that would
// truncate filesystem paths similar to what YARN does. For now, we just require
// people call `addJar` assuming the jar is in the same directory.
val mainClass = "org.apache.spark.deploy.worker.DriverWrapper" //图中紫色的DriverWorker
val classPathConf = "spark.driver.extraClassPath"
val classPathEntries = sys.props.get(classPathConf).toSeq.flatMap { cp =>
cp.split(java.io.File.pathSeparator)
}
val libraryPathConf = "spark.driver.extraLibraryPath"
val libraryPathEntries = sys.props.get(libraryPathConf).toSeq.flatMap { cp =>
cp.split(java.io.File.pathSeparator)
}
val extraJavaOptsConf = "spark.driver.extraJavaOptions"
val extraJavaOpts = sys.props.get(extraJavaOptsConf)
.map(Utils.splitCommandString).getOrElse(Seq.empty)
val sparkJavaOpts = Utils.sparkJavaOpts(conf)
val javaOpts = sparkJavaOpts ++ extraJavaOpts
val command = new Command(mainClass, //command是一个case Class 这段代码相当于组装进去了配置
Seq("{{WORKER_URL}}", "{{USER_JAR}}", driverArgs.mainClass) ++ driverArgs.driverOptions,
sys.env, classPathEntries, libraryPathEntries, javaOpts)
val driverDescription = new DriverDescription( //创建了DriverDescription的描述
driverArgs.jarUrl,
driverArgs.memory, //Driver内存小慎用Collect会把Executor所有的数据load进Driver的JVM中
driverArgs.cores,
driverArgs.supervise,
command)
ayncSendToMasterAndForwardReply[SubmitDriverResponse]( //异步地发送给Master Reply
RequestSubmitDriver(driverDescription)) //发送driverDescription信息
case "kill" =>
val driverId = driverArgs.driverId
ayncSendToMasterAndForwardReply[KillDriverResponse](RequestKillDriver(driverId))
}
}
....
override def receive: PartialFunction[Any, Unit] = {
case SubmitDriverResponse(master, success, driverId, message) =>
logInfo(message)
if (success) {
activeMasterEndpoint = master
pollAndReportStatus(driverId.get)
} else if (!Utils.responseFromBackup(message)) {
System.exit(-1)
}
case KillDriverResponse(master, driverId, success, message) =>
logInfo(message)
if (success) {
activeMasterEndpoint = master
pollAndReportStatus(driverId)
} else if (!Utils.responseFromBackup(message)) {
System.exit(-1)
}
}回到Master
override def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = {
...
case RequestSubmitDriver(description) =>
if (state != RecoveryState.ALIVE) { //如果没有存活
val msg = s"${Utils.BACKUP_STANDALONE_MASTER_PREFIX}: $state. " +
"Can only accept driver submissions in ALIVE state."
context.reply(SubmitDriverResponse(self, false, None, msg)) //设置为fasle
} else {
logInfo("Driver submitted " + description.command.mainClass)
val driver = createDriver(description) //创建一个driver
persistenceEngine.addDriver(driver)
waitingDrivers += driver //将driver添加到waitingDrivers:集群不止一个jar在提交还有其它地,
drivers.add(driver)
schedule()
// TODO: It might be good to instead have the submission client poll the master to determine
// the current status of the driver. For now it's simply "fire and forget".
context.reply(SubmitDriverResponse(self, true, Some(driver.id), //返回给Client
s"Driver successfully submitted as ${driver.id}"))
}private def createDriver(desc: DriverDescription): DriverInfo = {
val now = System.currentTimeMillis()
val date = new Date(now)
new DriverInfo(now, newDriverId(date), desc, date) //创建了一个DriverInfo
}回到Clinet
override def receive: PartialFunction[Any, Unit] = {
case SubmitDriverResponse(master, success, driverId, message) =>
logInfo(message)
if (success) { //如果成功了
activeMasterEndpoint = master
pollAndReportStatus(driverId.get) //调用此方法
} else if (!Utils.responseFromBackup(message)) {
System.exit(-1)
}pollAndReportStatus
def pollAndReportStatus(driverId: String): Unit = {
// Since ClientEndpoint is the only RpcEndpoint in the process, blocking the event loop thread
// is fine.
logInfo("... waiting before polling master for driver state")
Thread.sleep(5000)
logInfo("... polling master for driver state")
val statusResponse = //如果没有发送成功 重试
activeMasterEndpoint.askWithRetry[DriverStatusResponse](RequestDriverStatus(driverId))
if (statusResponse.found) { //如果 没有问题
logInfo(s"State of $driverId is ${statusResponse.state.get}")
// Worker node, if present
(statusResponse.workerId, statusResponse.workerHostPort, statusResponse.state) match {
case (Some(id), Some(hostPort), Some(DriverState.RUNNING)) =>
logInfo(s"Driver running on $hostPort ($id)")
case _ =>
}
// Exception, if present
statusResponse.exception match {
case Some(e) =>
logError(s"Exception from cluster was: $e")
e.printStackTrace()
System.exit(-1)
case _ =>
System.exit(0) //退出
}
} else { //如果错误
logError(s"ERROR: Cluster master did not recognize $driverId")
System.exit(-1) //错误退出
}
}回到Master
override def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = {
case RegisterWorker(
id, workerHost, workerPort, workerRef, cores, memory, workerWebUiUrl) =>
logInfo("Registering worker %s:%d with %d cores, %s RAM".format(
workerHost, workerPort, cores, Utils.megabytesToString(memory)))
if (state == RecoveryState.STANDBY) {
context.reply(MasterInStandby)
} else if (idToWorker.contains(id)) {
context.reply(RegisterWorkerFailed("Duplicate worker ID"))
} else {
val worker = new WorkerInfo(id, workerHost, workerPort, cores, memory,
workerRef, workerWebUiUrl)
if (registerWorker(worker)) {
persistenceEngine.addWorker(worker)
context.reply(RegisteredWorker(self, masterWebUiUrl))
schedule() // 调用了schedule()方法
} else {
val workerAddress = worker.endpoint.address
logWarning("Worker registration failed. Attempted to re-register worker at same " +
"address: " + workerAddress)
context.reply(RegisterWorkerFailed("Attempted to re-register worker at same address: "
+ workerAddress))
}
}schedule
/**
* Schedule the currently available resources among waiting apps. This method will be called
* every time a new app joins or resource availability changes.
*/
private def schedule(): Unit = {
if (state != RecoveryState.ALIVE) { //如果当前地状态不是ALIVE
return
}
// Drivers take strict precedence over executors
val shuffledAliveWorkers = Random.shuffle(workers.toSeq.filter(_.state == WorkerState.ALIVE))
val numWorkersAlive = shuffledAliveWorkers.size
var curPos = 0
for (driver <- waitingDrivers.toList) { // iterate over a copy of waitingDrivers
// We assign workers to each waiting driver in a round-robin fashion. For each driver, we
// start from the last worker that was assigned a driver, and continue onwards until we have
// explored all alive workers.
var launched = false //launched为false
var numWorkersVisited = 0
while (numWorkersVisited < numWorkersAlive && !launched) {
val worker = shuffledAliveWorkers(curPos)
numWorkersVisited += 1 //如果worker中的内存.CPU,
if (worker.memoryFree >= driver.desc.mem && worker.coresFree >= driver.desc.cores) {
launchDriver(worker, driver) //调用launchDriver
waitingDrivers -= driver //将这个driver从 waitingDrivers 中去掉
launched = true //设置 launched 为true
} //现在控制权应该走到了launchDriver
curPos = (curPos + 1) % numWorkersAlive
}
}
startExecutorsOnWorkers()
}launchDriver
private def launchDriver(worker: WorkerInfo, driver: DriverInfo) {
logInfo("Launching driver " + driver.id + " on worker " + worker.id)
worker.addDriver(driver) //这个worker在WorkerInfo中把当前的driver加上 Master可以知道那个Application运行在你的节点上
driver.worker = Some(worker)
worker.endpoint.send(LaunchDriver(driver.id, driver.desc)) // 这个时候控制权应该在在Worker
driver.state = DriverState.RUNNING
}回到Worker
LaunchDriver
DriverRunner包装了一下信息
case LaunchDriver(driverId, driverDesc) => // Client中的
logInfo(s"Asked to launch driver $driverId") DriverRunner
val driver = new DriverRunner( // new 了一个
conf,
driverId,
workDir,
sparkHome,
driverDesc.copy(command = Worker.maybeUpdateSSLSettings(driverDesc.command, conf)), //copy一下
self,
workerUri,
securityMgr)
drivers(driverId) = driver //这里的drivers是一个HashMap:drivers保存每一个application的ID和DricerRunneer
driver.start() //调用一下方法
coresUsed += driverDesc.cores //粗粒度 统计 core 的使用情况
memoryUsed += driverDesc.me调转DriverRunner
driver.star
/** Starts a thread to run and manage the driver. */
private[worker] def start() = {
new Thread("DriverRunner for " + driverId) { //创建一个线程
override def run() {
var shutdownHook: AnyRef = null
try {
shutdownHook = ShutdownHookManager.addShutdownHook { () =>
logInfo(s"Worker shutting down, killing driver $driverId")
kill()
}
// prepare driver jars and run driver
val exitCode = prepareAndRunDriver()
// set final state depending on if forcibly killed and process exit code
finalState = if (exitCode == 0) {
Some(DriverState.FINISHED)
} else if (killed) {
Some(DriverState.KILLED)
} else {
Some(DriverState.FAILED)
}
} catch {
case e: Exception =>
kill()
finalState = Some(DriverState.ERROR)
finalException = Some(e)
} finally {
if (shutdownHook != null) {
ShutdownHookManager.removeShutdownHook(shutdownHook)
}
}
//没有出异常就Worker发送信息
// notify worker of final driver state, possible exception
worker.send(DriverStateChanged(driverId, finalState.get, finalException))
}
}.start()
}prepareAndRunDriver
private[worker] def prepareAndRunDriver(): Int = {
val driverDir = createWorkingDirectory() //创建一个工作目录
val localJarFilename = downloadUserJar(driverDir) //在DriverClinet有个小的http服务器,就是为了提供jar包的下载 这时候把jar包下载到我们的Worker里面了
def substituteVariables(argument: String): String = argument match {
case "{{WORKER_URL}}" => workerUrl
case "{{USER_JAR}}" => localJarFilename
case other => other
}
// TODO: If we add ability to submit multiple jars they should also be added here
//启动一个进程
val builder = CommandUtils.buildProcessBuilder(driverDesc.command, securityManager,
driverDesc.mem, sparkHome.getAbsolutePath, substituteVariables)
//这是
runDriver(builder, driverDir, driverDesc.supervise)
}我们查看一下buildProcessBuilder
def buildProcessBuilder(
command: Command,
securityMgr: SecurityManager,
memory: Int,
sparkHome: String,
substituteArguments: String => String,
classPaths: Seq[String] = Seq[String](),
env: Map[String, String] = sys.env): ProcessBuilder = {
val localCommand = buildLocalCommand(
command, securityMgr, substituteArguments, classPaths, env)
val commandSeq = buildCommandSeq(localCommand, memory, sparkHome)
val builder = new ProcessBuilder(commandSeq: _*) //Java中与运行本地命令的
val environment = builder.environment()
for ((key, value) <- localCommand.environment) {
environment.put(key, value)
}
builder
}runDriver
private def runDriver(builder: ProcessBuilder, baseDir: File, supervise: Boolean): Int = {
builder.directory(baseDir)
def initialize(process: Process): Unit = {
// Redirect stdout and stderr to files
val stdout = new File(baseDir, "stdout") //获取正确输出
CommandUtils.redirectStream(process.getInputStream, stdout)
//获取异常
val stderr = new File(baseDir, "stderr")
val formattedCommand = builder.command.asScala.mkString("\"", "\" \"", "\"")
val header = "Launch Command: %s\n%s\n\n".format(formattedCommand, "=" * 40)
Files.append(header, stderr, StandardCharsets.UTF_8) //把日志输出到文件
CommandUtils.redirectStream(process.getErrorStream, stderr)
}
//重试
runCommandWithRetry(ProcessBuilderLike(builder), initialize, supervise)
}runCommandWithRetry
private[worker] def runCommandWithRetry(
command: ProcessBuilderLike, initialize: Process => Unit, supervise: Boolean): Int = {
var exitCode = -1 //退出代码
// Time to wait between submission retries.
var waitSeconds = 1
// A run of this many seconds resets the exponential back-off.
val successfulRunDuration = 5
var keepTrying = !killed
//重试
while (keepTrying) {
logInfo("Launch Command: " + command.command.mkString("\"", "\" \"", "\""))
synchronized {
if (killed) { return exitCode }
process = Some(command.start()) //这个process可能就是你的DriverWrapper
initialize(process.get)
}
val processStart = clock.getTimeMillis()
exitCode = process.get.waitFor()
// check if attempting another run
keepTrying = supervise && exitCode != 0 && !killed
if (keepTrying) {
if (clock.getTimeMillis() - processStart > successfulRunDuration * 1000) {
waitSeconds = 1
}
logInfo(s"Command exited with status $exitCode, re-launching after $waitSeconds s.")
sleeper.sleep(waitSeconds)
waitSeconds = waitSeconds * 2 // exponential back-off
}
}
exitCode
}进入DriverWrapper
object DriverWrapper {
def main(args: Array[String]) {
args.toList match {
/*
* IMPORTANT: Spark 1.3 provides a stable application submission gateway that is both
* backward and forward compatible across future Spark versions. Because this gateway
* uses this class to launch the driver, the ordering and semantics of the arguments
* here must also remain consistent across versions.
*/
case workerUrl :: userJar :: mainClass :: extraArgs =>
val rpcEnv = RpcEnv.create("Driver", //创建rpcEnv
Utils.localHostName(), 0, conf, new SecurityManager(conf))
rpcEnv.setupEndpoint("workerWatcher", new WorkerWatcher(rpcEnv, workerUrl))
val currentLoader = Thread.currentThread.getContextClassLoader
val userJarUrl = new File(userJar).toURI().toURL() //userJarUrl 是我们的Jar包
val loader = //获得线程
if (sys.props.getOrElse("spark.driver.userClassPathFirst", "false").toBoolean) {
new ChildFirstURLClassLoader(Array(userJarUrl), currentLoader)
} else {
new MutableURLClassLoader(Array(userJarUrl), currentLoader)
}
Thread.currentThread.setContextClassLoader(loader)
// Delegate to supplied main class
//把main线程加载进来
val clazz = Utils.classForName(mainClass)
//反射jar包中的main方法
val mainMethod = clazz.getMethod("main", classOf[Array[String]])
//执行jar包中的main方法
mainMethod.invoke(null, extraArgs.toArray[String])
rpcEnv.shutdown() //最后Drive shutdown 因此我们可以有理由断定 Driver程序就是Jar包
case _ =>
// scalastyle:off println
System.err.println("Usage: DriverWrapper <workerUrl> <userJar> <driverMainClass> [options]")
// scalastyle:on println
System.exit(-1)
}
}
}我们回到driver.start看worker.send(DriverStateChanged(driverId, finalState.get, finalException)) 给worker发送
DriverStateChanged
/** Starts a thread to run and manage the driver. */
private[worker] def start() = {
new Thread("DriverRunner for " + driverId) {
override def run() {
var shutdownHook: AnyRef = null
try {
shutdownHook = ShutdownHookManager.addShutdownHook { () =>
logInfo(s"Worker shutting down, killing driver $driverId")
kill()
}回到Driver
case driverStateChanged @ DriverStateChanged(driverId, state, exception) =>
handleDriverStateChanged(driverStateChanged)我们进入handleDriverStateChanged
handleDriverStateChanged
private[worker] def handleDriverStateChanged(driverStateChanged: DriverStateChanged): Unit = {
val driverId = driverStateChanged.driverId
val exception = driverStateChanged.exception
val state = driverStateChanged.state
state match {
case DriverState.ERROR => //打印一些消息
logWarning(s"Driver $driverId failed with unrecoverable exception: ${exception.get}")
case DriverState.FAILED =>
logWarning(s"Driver $driverId exited with failure")
case DriverState.FINISHED =>
logInfo(s"Driver $driverId exited successfully")
case DriverState.KILLED =>
logInfo(s"Driver $driverId was killed by user")
case _ =>
logDebug(s"Driver $driverId changed state to $state")
}
sendToMaster(driverStateChanged) //发送给Master driverStateChanged
val driver = drivers.remove(driverId).get
finishedDrivers(driverId) = driver
trimFinishedDriversIfNecessary()
memoryUsed -= driver.driverDesc.mem
coresUsed -= driver.driverDesc.cores
}sendToMaster
private def sendToMaster(message: Any): Unit = {
master match {
case Some(masterRef) => masterRef.send(message)
case None =>
logWarning(
s"Dropping $message because the connection to master has not yet been established")
}
}回到Master(Driver启动完毕)
case DriverStateChanged(driverId, state, exception) =>
state match {
case DriverState.ERROR | DriverState.FINISHED | DriverState.KILLED | DriverState.FAILED =>
removeDriver(driverId, state, exception)
case _ =>
throw new Exception(s"Received unexpected state update for driver $driverId: $state")
}到这一步Driver已经基本启动
注册Application
我们需要看SparkContext的代码代码有3000多行我们跳着看吧
class SparkContext(config: SparkConf) extends Logging { //SparkConf 一个配置类
....
//这里是Spark内部的一些变量
private var _conf: SparkConf = _
private var _eventLogDir: Option[URI] = None
private var _eventLogCodec: Option[String] = None
private var _env: SparkEnv = _
private var _jobProgressListener: JobProgressListener = _
private var _statusTracker: SparkStatusTracker = _
private var _progressBar: Option[ConsoleProgressBar] = None
private var _ui: Option[SparkUI] = None
private var _hadoopConfiguration: Configuration = _
private var _executorMemory: Int = _
private var _schedulerBackend: SchedulerBackend = _
private var _taskScheduler: TaskScheduler = _
private var _heartbeatReceiver: RpcEndpointRef = _
@volatile private var _dagScheduler: DAGScheduler = _ //DAG任务分解其
private var _applicationId: String = _
private var _applicationAttemptId: Option[String] = None
private var _eventLogger: Option[EventLoggingListener] = None
private var _executorAllocationManager: Option[ExecutorAllocationManager] = None
private var _cleaner: Option[ContextCleaner] = None
private var _listenerBusStarted: Boolean = false
private var _jars: Seq[String] = _
private var _files: Seq[String] = _
private var _shutdownHookRef: AnyRef = _我们首先看一下SparkEnv吧
SparkEnv
@DeveloperApi
class SparkEnv (
val executorId: String,
private[spark] val rpcEnv: RpcEnv,
val serializer: Serializer,
val closureSerializer: Serializer,
val serializerManager: SerializerManager,
val mapOutputTracker: MapOutputTracker,
val shuffleManager: ShuffleManager,
val broadcastManager: BroadcastManager,
val blockManager: BlockManager,
val securityManager: SecurityManager,
val metricsSystem: MetricsSystem,
val memoryManager: MemoryManager,
val outputCommitCoordinator: OutputCommitCoordinator,
val conf: SparkConf) extends Logging {
主要初始化方法
//主要初始化方法
try {
_conf = config.clone()
_conf.validateSettings()
if (!_conf.contains("spark.master")) {
throw new SparkException("A master URL must be set in your configuration")
}
if (!_conf.contains("spark.app.name")) {
throw new SparkException("An application name must be set in your configuration")
}
// System property spark.yarn.app.id must be set if user code ran by AM on a YARN cluster
if (master == "yarn" && deployMode == "cluster" && !_conf.contains("spark.yarn.app.id")) {
throw new SparkException("Detected yarn cluster mode, but isn't running on a cluster. " +
"Deployment to YARN is not supported directly by SparkContext. Please use spark-submit.")
}
if (_conf.getBoolean("spark.logConf", false)) {
logInfo("Spark configuration:\n" + _conf.toDebugString)
}
// Set Spark driver host and port system properties. This explicitly sets the configuration
// instead of relying on the default value of the config constant.
_conf.set(DRIVER_HOST_ADDRESS, _conf.get(DRIVER_HOST_ADDRESS))
_conf.setIfMissing("spark.driver.port", "0")
_conf.set("spark.executor.id", SparkContext.DRIVER_IDENTIFIER)
_jars = Utils.getUserJars(_conf)
_files = _conf.getOption("spark.files").map(_.split(",")).map(_.filter(_.nonEmpty))
.toSeq.flatten
_eventLogDir =
if (isEventLogEnabled) {
val unresolvedDir = conf.get("spark.eventLog.dir", EventLoggingListener.DEFAULT_LOG_DIR)
.stripSuffix("/")
Some(Utils.resolveURI(unresolvedDir))
} else {
None
}
_eventLogCodec = {
val compress = _conf.getBoolean("spark.eventLog.compress", false)
if (compress && isEventLogEnabled) {
Some(CompressionCodec.getCodecName(_conf)).map(CompressionCodec.getShortName)
} else {
None
}
}
if (master == "yarn" && deployMode == "client") System.setProperty("SPARK_YARN_MODE", "true")
// "_jobProgressListener" should be set up before creating SparkEnv because when creating
// "SparkEnv", some messages will be posted to "listenerBus" and we should not miss them.
_jobProgressListener = new JobProgressListener(_conf)
listenerBus.addListener(jobProgressListener)
// Create the Spark execution environment (cache, map output tracker, etc)
_env = createSparkEnv(_conf, isLocal, listenerBus)
SparkEnv.set(_env)
// If running the REPL, register the repl's output dir with the file server.
_conf.getOption("spark.repl.class.outputDir").foreach { path =>
val replUri = _env.rpcEnv.fileServer.addDirectory("/classes", new File(path))
_conf.set("spark.repl.class.uri", replUri)
}
_statusTracker = new SparkStatusTracker(this)
_progressBar =
if (_conf.getBoolean("spark.ui.showConsoleProgress", true) && !log.isInfoEnabled) {
Some(new ConsoleProgressBar(this))
} else {
None
}
_ui =
if (conf.getBoolean("spark.ui.enabled", true)) {
Some(SparkUI.createLiveUI(this, _conf, listenerBus, _jobProgressListener,
_env.securityManager, appName, startTime = startTime))
} else {
// For tests, do not enable the UI
None
}
// Bind the UI before starting the task scheduler to communicate
// the bound port to the cluster manager properly
_ui.foreach(_.bind())
_hadoopConfiguration = SparkHadoopUtil.get.newConfiguration(_conf)
// Add each JAR given through the constructor
if (jars != null) {
jars.foreach(addJar)
}
if (files != null) {
files.foreach(addFile)
}
//获取配置
_executorMemory = _conf.getOption("spark.executor.memory")
.orElse(Option(System.getenv("SPARK_EXECUTOR_MEMORY")))
.orElse(Option(System.getenv("SPARK_MEM"))
.map(warnSparkMem))
.map(Utils.memoryStringToMb)
.getOrElse(1024)
// Convert java options to env vars as a work around
// since we can't set env vars directly in sbt.
for { (envKey, propKey) <- Seq(("SPARK_TESTING", "spark.testing"))
value <- Option(System.getenv(envKey)).orElse(Option(System.getProperty(propKey)))} {
executorEnvs(envKey) = value
}
Option(System.getenv("SPARK_PREPEND_CLASSES")).foreach { v =>
executorEnvs("SPARK_PREPEND_CLASSES") = v
}
// The Mesos scheduler backend relies on this environment variable to set executor memory.
// TODO: Set this only in the Mesos scheduler.
executorEnvs("SPARK_EXECUTOR_MEMORY") = executorMemory + "m"
executorEnvs ++= _conf.getExecutorEnv
executorEnvs("SPARK_USER") = sparkUser
// We need to register "HeartbeatReceiver" before "createTaskScheduler" because Executor will
// retrieve "HeartbeatReceiver" in the constructor. (SPARK-6640)
_heartbeatReceiver = env.rpcEnv.setupEndpoint( //心跳
HeartbeatReceiver.ENDPOINT_NAME, new HeartbeatReceiver(this))
// Create and start the scheduler
val (sched, ts) = SparkContext.createTaskScheduler(this, master, deployMode)
_schedulerBackend = sched //创建 _schedulerBackend
_taskScheduler = ts //创建 _taskScheduler
_dagScheduler = new DAGScheduler(this) //创建 DAGScheduler
_heartbeatReceiver.ask[Boolean](TaskSchedulerIsSet)
// start TaskScheduler after taskScheduler sets DAGScheduler reference in DAGScheduler's
// constructor
_taskScheduler.start()
_applicationId = _taskScheduler.applicationId()
_applicationAttemptId = taskScheduler.applicationAttemptId()
_conf.set("spark.app.id", _applicationId)
if (_conf.getBoolean("spark.ui.reverseProxy", false)) {
System.setProperty("spark.ui.proxyBase", "/proxy/" + _applicationId)
}
_ui.foreach(_.setAppId(_applicationId))
_env.blockManager.initialize(_applicationId)
// The metrics system for Driver need to be set spark.app.id to app ID.
// So it should start after we get app ID from the task scheduler and set spark.app.id.
_env.metricsSystem.start()
// Attach the driver metrics servlet handler to the web ui after the metrics system is started.
_env.metricsSystem.getServletHandlers.foreach(handler => ui.foreach(_.attachHandler(handler)))
_eventLogger =
if (isEventLogEnabled) {
val logger =
new EventLoggingListener(_applicationId, _applicationAttemptId, _eventLogDir.get,
_conf, _hadoopConfiguration)
logger.start()
listenerBus.addListener(logger)
Some(logger)
} else {
None
}
// Optionally scale number of executors dynamically based on workload. Exposed for testing.
val dynamicAllocationEnabled = Utils.isDynamicAllocationEnabled(_conf)
_executorAllocationManager =
if (dynamicAllocationEnabled) {
schedulerBackend match {
case b: ExecutorAllocationClient =>
Some(new ExecutorAllocationManager(
schedulerBackend.asInstanceOf[ExecutorAllocationClient], listenerBus, _conf))
case _ =>
None
}
} else {
None
}
_executorAllocationManager.foreach(_.start())
_cleaner =
if (_conf.getBoolean("spark.cleaner.referenceTracking", true)) {
Some(new ContextCleaner(this))
} else {
None
}
_cleaner.foreach(_.start())
setupAndStartListenerBus()
postEnvironmentUpdate()
postApplicationStart()
// Post init
_taskScheduler.postStartHook()
_env.metricsSystem.registerSource(_dagScheduler.metricsSource)
_env.metricsSystem.registerSource(new BlockManagerSource(_env.blockManager))
_executorAllocationManager.foreach { e =>
_env.metricsSystem.registerSource(e.executorAllocationManagerSource)
}
// Make sure the context is stopped if the user forgets about it. This avoids leaving
// unfinished event logs around after the JVM exits cleanly. It doesn't help if the JVM
// is killed, though.
logDebug("Adding shutdown hook") // force eager creation of logger
_shutdownHookRef = ShutdownHookManager.addShutdownHook(
ShutdownHookManager.SPARK_CONTEXT_SHUTDOWN_PRIORITY) { () =>
logInfo("Invoking stop() from shutdown hook")
stop()
}
} catch {
case NonFatal(e) =>
logError("Error initializing SparkContext.", e)
try {
stop()
} catch {
case NonFatal(inner) =>
logError("Error stopping SparkContext after init error.", inner)
} finally {
throw e
}
}createTaskScheduler
private def createTaskScheduler(
sc: SparkContext,
master: String,
deployMode: String): (SchedulerBackend, TaskScheduler) = {
import SparkMasterRegex._
// When running locally, don't try to re-execute tasks on failure.
val MAX_LOCAL_TASK_FAILURES = 1
master match {
case "local" => //如果是local模式
val scheduler = new TaskSchedulerImpl(sc, MAX_LOCAL_TASK_FAILURES, isLocal = true)
val backend = new LocalSchedulerBackend(sc.getConf, scheduler, 1)
scheduler.initialize(backend)
(backend, scheduler)
case LOCAL_N_REGEX(threads) => //或者是多线程的local模式
def localCpuCount: Int = Runtime.getRuntime.availableProcessors()
// local[*] estimates the number of cores on the machine; local[N] uses exactly N threads.
val threadCount = if (threads == "*") localCpuCount else threads.toInt
if (threadCount <= 0) {
throw new SparkException(s"Asked to run locally with $threadCount threads")
}
val scheduler = new TaskSchedulerImpl(sc, MAX_LOCAL_TASK_FAILURES, isLocal = true)
val backend = new LocalSchedulerBackend(sc.getConf, scheduler, threadCount)
scheduler.initialize(backend)
(backend, scheduler)
case LOCAL_N_FAILURES_REGEX(threads, maxFailures) =>
def localCpuCount: Int = Runtime.getRuntime.availableProcessors()
// local[*, M] means the number of cores on the computer with M failures
// local[N, M] means exactly N threads with M failures
val threadCount = if (threads == "*") localCpuCount else threads.toInt
val scheduler = new TaskSchedulerImpl(sc, maxFailures.toInt, isLocal = true)
val backend = new LocalSchedulerBackend(sc.getConf, scheduler, threadCount)
scheduler.initialize(backend)
(backend, scheduler)
case SPARK_REGEX(sparkUrl) => //StandaloneSchedulerBackend 模式
val scheduler = new TaskSchedulerImpl(sc)
val masterUrls = sparkUrl.split(",").map("spark://" + _)
val backend = new StandaloneSchedulerBackend(scheduler, sc, masterUrls)
scheduler.initialize(backend)
(backend, scheduler)
case LOCAL_CLUSTER_REGEX(numSlaves, coresPerSlave, memoryPerSlave) =>
// Check to make sure memory requested <= memoryPerSlave. Otherwise Spark will just hang.
val memoryPerSlaveInt = memoryPerSlave.toInt
if (sc.executorMemory > memoryPerSlaveInt) {
throw new SparkException(
"Asked to launch cluster with %d MB RAM / worker but requested %d MB/worker".format(
memoryPerSlaveInt, sc.executorMemory))
}
val scheduler = new TaskSchedulerImpl(sc)
val localCluster = new LocalSparkCluster(
numSlaves.toInt, coresPerSlave.toInt, memoryPerSlaveInt, sc.conf)
val masterUrls = localCluster.start()
val backend = new StandaloneSchedulerBackend(scheduler, sc, masterUrls)
scheduler.initialize(backend)
backend.shutdownCallback = (backend: StandaloneSchedulerBackend) => {
localCluster.stop()
}
(backend, scheduler)
case masterUrl => //根据你的提交模式 会创建不同的 scheduler backend
val cm = getClusterManager(masterUrl) match {
case Some(clusterMgr) => clusterMgr
case None => throw new SparkException("Could not parse Master URL: '" + master + "'")
}
try {
val scheduler = cm.createTaskScheduler(sc, masterUrl)
val backend = cm.createSchedulerBackend(sc, masterUrl, scheduler)
cm.initialize(scheduler, backend)
(backend, scheduler)
} catch {
case se: SparkException => throw se
case NonFatal(e) =>
throw new SparkException("External scheduler cannot be instantiated", e)
}
} 启动
// Create and start the scheduler
val (sched, ts) = SparkContext.createTaskScheduler(this, master, deployMode)
_schedulerBackend = sched
_taskScheduler = ts
_dagScheduler = new DAGScheduler(this)
_heartbeatReceiver.ask[Boolean](TaskSchedulerIsSet)
// start TaskScheduler after taskScheduler sets DAGScheduler reference in DAGScheduler's
// constructor
_taskScheduler.start() //启动任务
_applicationId = _taskScheduler.applicationId()
_applicationAttemptId = taskScheduler.applicationAttemptId()
_conf.set("spark.app.id", _applicationId)
if (_conf.getBoolean("spark.ui.reverseProxy", false)) {
System.setProperty("spark.ui.proxyBase", "/proxy/" + _applicationId)
}
_ui.foreach(_.setAppId(_applicationId))
_env.blockManager.initialize(_applicationId)
// The metrics system for Driver need to be set spark.app.id to app ID.
// So it should start after we get app ID from the task scheduler and set spark.app.id.
_env.metricsSystem.start()
// Attach the driver metrics servlet handler to the web ui after the metrics system is started.
_env.metricsSystem.getServletHandlers.foreach(handler => ui.foreach(_.attachHandler(handler)))
_eventLogger =
if (isEventLogEnabled) {
val logger =
new EventLoggingListener(_applicationId, _applicationAttemptId, _eventLogDir.get,
_conf, _hadoopConfiguration)
logger.start()
listenerBus.addListener(logger)
Some(logger)
} else {
None
}
// Optionally scale number of executors dynamically based on workload. Exposed for testing.
val dynamicAllocationEnabled = Utils.isDynamicAllocationEnabled(_conf)
_executorAllocationManager =
if (dynamicAllocationEnabled) {
schedulerBackend match {
case b: ExecutorAllocationClient =>
Some(new ExecutorAllocationManager(
schedulerBackend.asInstanceOf[ExecutorAllocationClient], listenerBus, _conf))
case _ =>
None
}
} else {
None
}
_executorAllocationManager.foreach(_.start())
_cleaner =
if (_conf.getBoolean("spark.cleaner.referenceTracking", true)) {
Some(new ContextCleaner(this))
} else {
None
}
_cleaner.foreach(_.start())
setupAndStartListenerBus()
postEnvironmentUpdate()
postApplicationStart()
// Post init
_taskScheduler.postStartHook()
_env.metricsSystem.registerSource(_dagScheduler.metricsSource)
_env.metricsSystem.registerSource(new BlockManagerSource(_env.blockManager))
_executorAllocationManager.foreach { e =>
_env.metricsSystem.registerSource(e.executorAllocationManagerSource)
}
// Make sure the context is stopped if the user forgets about it. This avoids leaving
// unfinished event logs around after the JVM exits cleanly. It doesn't help if the JVM
// is killed, though.
logDebug("Adding shutdown hook") // force eager creation of logger
_shutdownHookRef = ShutdownHookManager.addShutdownHook( //注册一个ShutdownHook (钩子函数)
ShutdownHookManager.SPARK_CONTEXT_SHUTDOWN_PRIORITY) { () =>
logInfo("Invoking stop() from shutdown hook")
stop()
}
} catch {
case NonFatal(e) =>
logError("Error initializing SparkContext.", e)
try {
stop()
} catch {
case NonFatal(inner) =>
logError("Error stopping SparkContext after init error.", inner)
} finally {
throw e
}
}Excutor分配
StandaloneSchedulerBackend
/**
* A [[SchedulerBackend]] implementation for Spark's standalone cluster manager.
*/
private[spark] class StandaloneSchedulerBackend(
scheduler: TaskSchedulerImpl,
sc: SparkContext,
masters: Array[String])
extends CoarseGrainedSchedulerBackend(scheduler, sc.env.rpcEnv)//继承了一个粗粒度schedulerBackend 在应用运行之间就把资源计算好,在应用运行期间资源是不动的固定的. Messon有粗细粒度之分再YARN 集群和Stanlone中 都为粗粒度的
with StandaloneAppClientListener
with Logging {
private var client: StandaloneAppClient = null
private val stopping = new AtomicBoolean(false)
private val launcherBackend = new LauncherBackend() {
override protected def onStopRequest(): Unit = stop(SparkAppHandle.State.KILLED)
}
@volatile var shutdownCallback: StandaloneSchedulerBackend => Unit = _
@volatile private var appId: String = _
private val registrationBarrier = new Semaphore(0)
private val maxCores = conf.getOption("spark.cores.max").map(_.toInt)
private val totalExpectedCores = maxCores.getOrElse(0)
override def start() { //我们关注一下start的方法
super.start()
launcherBackend.connect()
// The endpoint for executors to talk to us
val driverUrl = RpcEndpointAddress(
sc.conf.get("spark.driver.host"),
sc.conf.get("spark.driver.port").toInt,
CoarseGrainedSchedulerBackend.ENDPOINT_NAME).toString
val args = Seq(
"--driver-url", driverUrl,
"--executor-id", "{{EXECUTOR_ID}}",
"--hostname", "{{HOSTNAME}}",
"--cores", "{{CORES}}",
"--app-id", "{{APP_ID}}",
"--worker-url", "{{WORKER_URL}}")
val extraJavaOpts = sc.conf.getOption("spark.executor.extraJavaOptions")
.map(Utils.splitCommandString).getOrElse(Seq.empty)
val classPathEntries = sc.conf.getOption("spark.executor.extraClassPath")
.map(_.split(java.io.File.pathSeparator).toSeq).getOrElse(Nil)
val libraryPathEntries = sc.conf.getOption("spark.executor.extraLibraryPath")
.map(_.split(java.io.File.pathSeparator).toSeq).getOrElse(Nil)
// When testing, expose the parent class path to the child. This is processed by
// compute-classpath.{cmd,sh} and makes all needed jars available to child processes
// when the assembly is built with the "*-provided" profiles enabled.
val testingClassPath =
if (sys.props.contains("spark.testing")) {
sys.props("java.class.path").split(java.io.File.pathSeparator).toSeq
} else {
Nil
}
// Start executors with a few necessary configs for registering with the scheduler
val sparkJavaOpts = Utils.sparkJavaOpts(conf, SparkConf.isExecutorStartupConf)
val javaOpts = sparkJavaOpts ++ extraJavaOpts
val command = Command("org.apache.spark.executor.CoarseGrainedExecutorBackend",
args, sc.executorEnvs, classPathEntries ++ testingClassPath, libraryPathEntries, javaOpts)
val appUIAddress = sc.ui.map(_.appUIAddress).getOrElse("")
val coresPerExecutor = conf.getOption("spark.executor.cores").map(_.toInt)
// If we're using dynamic allocation, set our initial executor limit to 0 for now.
// ExecutorAllocationManager will send the real initial limit to the Master later.
val initialExecutorLimit =
if (Utils.isDynamicAllocationEnabled(conf)) {
Some(0)
} else {
None
}
val appDesc = new ApplicationDescription(sc.appName, maxCores, sc.executorMemory, command,
appUIAddress, sc.eventLogDir, sc.eventLogCodec, coresPerExecutor, initialExecutorLimit)
client = new StandaloneAppClient(sc.env.rpcEnv, masters, appDesc, this, conf)
client.start()
launcherBackend.setState(SparkAppHandle.State.SUBMITTED)
waitForRegistration()
launcherBackend.setState(SparkAppHandle.State.RUNNING)
}
override def stop(): Unit = {
stop(SparkAppHandle.State.FINISHED)
}
override def connected(appId: String) {
logInfo("Connected to Spark cluster with app ID " + appId)
this.appId = appId
notifyContext()
launcherBackend.setAppId(appId)
}
override def disconnected() {
notifyContext()
if (!stopping.get) {
logWarning("Disconnected from Spark cluster! Waiting for reconnection...")
}
}
override def dead(reason: String) {
notifyContext()
if (!stopping.get) {
launcherBackend.setState(SparkAppHandle.State.KILLED)
logError("Application has been killed. Reason: " + reason)
try {
scheduler.error(reason)
} finally {
// Ensure the application terminates, as we can no longer run jobs.
sc.stopInNewThread()
}
}
}CoarseGrainedSchedulerBackend
override def start() {
val properties = new ArrayBuffer[(String, String)]
for ((key, value) <- scheduler.sc.conf.getAll) {
if (key.startsWith("spark.")) {
properties += ((key, value))
}
}
// TODO (prashant) send conf instead of properties
driverEndpoint = createDriverEndpointRef(properties) //创建了一个driverEndpoint
}回到StandaloneSchedulerBackend
我们看一下再start方法中的
//创建了一个ApplicationDescription
val appDesc = new ApplicationDescription(sc.appName, maxCores, sc.executorMemory, command,
appUIAddress, sc.eventLogDir, sc.eventLogCodec, coresPerExecutor, initialExecutorLimit)
//创建了一个StandaloneAppClient
client = new StandaloneAppClient(sc.env.rpcEnv, masters, appDesc, this, conf) //控制权限转到StandaloneAppClient
client.start()
launcherBackend.setState(SparkAppHandle.State.SUBMITTED)
waitForRegistration()
launcherBackend.setState(SparkAppHandle.State.RUNNING)跳转StandaloneAppClient
private[spark] class StandaloneAppClient(
rpcEnv: RpcEnv,
masterUrls: Array[String],
appDescription: ApplicationDescription,
listener: StandaloneAppClientListener,
conf: SparkConf)
extends Logging { //Client
private val masterRpcAddresses = masterUrls.map(RpcAddress.fromSparkURL(_))
private val REGISTRATION_TIMEOUT_SECONDS = 20
private val REGISTRATION_RETRIES = 3
private val endpoint = new AtomicReference[RpcEndpointRef]
private val appId = new AtomicReference[String]
private val registered = new AtomicBoolean(false)
//也是个端点,
private class ClientEndpoint(override val rpcEnv: RpcEnv) extends ThreadSafeRpcEndpoint
with Logging {
private var master: Option[RpcEndpointRef] = None
// To avoid calling listener.disconnected() multiple times
private var alreadyDisconnected = false
// To avoid calling listener.dead() multiple times
private val alreadyDead = new AtomicBoolean(false)
private val registerMasterFutures = new AtomicReference[Array[JFuture[_]]]
private val registrationRetryTimer = new AtomicReference[JScheduledFuture[_]]
....
def start() {
// Just launch an rpcEndpoint; it will call back into the listener.
//创建了一个ClientEndpoint
endpoint.set(rpcEnv.setupEndpoint("AppClient", new ClientEndpoint(rpcEnv)))
}
....
override def receive: PartialFunction[Any, Unit] = {
case RegisteredApplication(appId_, masterRef) =>
// FIXME How to handle the following cases?
// 1. A master receives multiple registrations and sends back multiple
// RegisteredApplications due to an unstable network.
// 2. Receive multiple RegisteredApplication from different masters because the master is
// changing.
appId.set(appId_)
registered.set(true)
master = Some(masterRef)
listener.connected(appId.get)
case ApplicationRemoved(message) =>
markDead("Master removed our application: %s".format(message))
stop()
case ExecutorAdded(id: Int, workerId: String, hostPort: String, cores: Int, memory: Int) =>
val fullId = appId + "/" + id
logInfo(("Ex" +
"ecutor added: %s on %s (%s) with %d cores").format(fullId, workerId, hostPort,
cores))
listener.executorAdded(fullId, workerId, hostPort, cores, memory)
case ExecutorUpdated(id, state, message, exitStatus, workerLost) =>
val fullId = appId + "/" + id
val messageText = message.map(s => " (" + s + ")").getOrElse("")
logInfo("Executor updated: %s is now %s%s".format(fullId, state, messageText))
if (ExecutorState.isFinished(state)) {
listener.executorRemoved(fullId, message.getOrElse(""), exitStatus, workerLost)
}
case MasterChanged(masterRef, masterWebUiUrl) =>
logInfo("Master has changed, new master is at " + masterRef.address.toSparkURL)
master = Some(masterRef)
alreadyDisconnected = false
masterRef.send(MasterChangeAcknowledged(appId.get))
}
....
override def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = {
case StopAppClient =>
markDead("Application has been stopped.")
sendToMaster(UnregisterApplication(appId.get))
context.reply(true)
stop()
}
private def registerWithMaster(nthRetry: Int) { //向Master 注册
registerMasterFutures.set(tryRegisterAllMasters()) //查看这个方法
registrationRetryTimer.set(registrationRetryThread.schedule(new Runnable {
override def run(): Unit = {
if (registered.get) {
registerMasterFutures.get.foreach(_.cancel(true))
registerMasterThreadPool.shutdownNow()
} else if (nthRetry >= REGISTRATION_RETRIES) {
markDead("All masters are unresponsive! Giving up.")
} else {
registerMasterFutures.get.foreach(_.cancel(true))
registerWithMaster(nthRetry + 1) //重试
}
}
}, REGISTRATION_TIMEOUT_SECONDS, TimeUnit.SECONDS))
} tryRegisterAllMasters
private def tryRegisterAllMasters(): Array[JFuture[_]] = {
for (masterAddress <- masterRpcAddresses) yield {
registerMasterThreadPool.submit(new Runnable {
override def run(): Unit = try {
if (registered.get) {
return
}
logInfo("Connecting to master " + masterAddress.toSparkURL + "...")
val masterRef = rpcEnv.setupEndpointRef(masterAddress, Master.ENDPOINT_NAME)
//给master发送RegisterApplication
masterRef.send(RegisterApplication(appDescription, self)) //控制权走到Master
} catch {
case ie: InterruptedException => // Cancelled
case NonFatal(e) => logWarning(s"Failed to connect to master $masterAddress", e)
}
})
}
}回到Master
RegisterApplication
case RegisterApplication(description, driver) =>
// TODO Prevent repeated registrations from some driver
if (state == RecoveryState.STANDBY) {
// ignore, don't send response
} else {
logInfo("Registering app " + description.name)
val app = createApplication(description, driver)
registerApplication(app)
logInfo("Registered app " + description.name + " with ID " + app.id)
persistenceEngine.addApplication(app)
driver.send(RegisteredApplication(app.id, self)) //给driver 送法消息
// 启动分配Executor
schedule()
}schedule
private def schedule(): Unit = {
if (state != RecoveryState.ALIVE) {
return
}
// Drivers take strict precedence over executors
val shuffledAliveWorkers = Random.shuffle(workers.toSeq.filter(_.state == WorkerState.ALIVE))
val numWorkersAlive = shuffledAliveWorkers.size
var curPos = 0
for (driver <- waitingDrivers.toList) { // iterate over a copy of waitingDrivers
// We assign workers to each waiting driver in a round-robin fashion. For each driver, we
// start from the last worker that was assigned a driver, and continue onwards until we have
// explored all alive workers.
var launched = false
var numWorkersVisited = 0
while (numWorkersVisited < numWorkersAlive && !launched) {
val worker = shuffledAliveWorkers(curPos)
numWorkersVisited += 1
if (worker.memoryFree >= driver.desc.mem && worker.coresFree >= driver.desc.cores) {
launchDriver(worker, driver)
waitingDrivers -= driver
launched = true
}
curPos = (curPos + 1) % numWorkersAlive
}
}
startExecutorsOnWorkers() //Worker已经部署 我们需要看这个
}startExecutorsOnWorkers
private def startExecutorsOnWorkers(): Unit = {
// Right now this is a very simple FIFO scheduler. We keep trying to fit in the first app
// in the queue, then the second app, etc.
//这里的应用并不能并行执行,因为 再for循环里面 的任务智能一个一个分配
for (app <- waitingApps if app.coresLeft > 0) { //这里waitingApps保存所有需要分配资源的Driver
val coresPerExecutor: Option[Int] = app.desc.coresPerExecutor
// Filter out workers that don't have enough resources to launch an executor
val usableWorkers = workers.toArray.filter(_.state == WorkerState.ALIVE) //调出满足应用的Exector需要的Worker
.filter(worker => worker.memoryFree >= app.desc.memoryPerExecutorMB &&
worker.coresFree >= coresPerExecutor.getOrElse(1))
.sortBy(_.coresFree).reverse
//scheduleExecutorsOnWorkers是资源分配的核心算法我们来看一下
val assignedCores = scheduleExecutorsOnWorkers(app, usableWorkers, spreadOutApps)
// Now that we've decided how many cores to allocate on each worker, let's allocate them
for (pos <- 0 until usableWorkers.length if assignedCores(pos) > 0) {
allocateWorkerResourceToExecutors(
app, assignedCores(pos), coresPerExecutor, usableWorkers(pos))
}
}
}scheduleExecutorsOnWorkers
资源分配的核心代码
private def scheduleExecutorsOnWorkers(
app: ApplicationInfo,
usableWorkers: Array[WorkerInfo],
spreadOutApps: Boolean): Array[Int] = { //如果参数为True 仅量吧你需要的Executor分配到不同的Worker上
// 每一个Executor有多少Core
val coresPerExecutor = app.desc.coresPerExecutor
// minCoresPerExecutor 如果你没定义那么就是1,如果定义了就是coresPerExecutor
val minCoresPerExecutor = coresPerExecutor.getOrElse(1)
// 是否允许一个worker上有多个Executor
val oneExecutorPerWorker = coresPerExecutor.isEmpty
// 指定Memory 1G
val memoryPerExecutor = app.desc.memoryPerExecutorMB
// 获得usableWorkers 长度
val numUsable = usableWorkers.length
val assignedCores = new Array[Int](numUsable) // Number of cores to give to each worker
val assignedExecutors = new Array[Int](numUsable) // Number of new executors on each worker
// coresToAssign 保险
var coresToAssign = math.min(app.coresLeft, usableWorkers.map(_.coresFree).sum)
/** Return whether the specified worker can launch an executor for this app. */
def canLaunchExecutor(pos: Int): Boolean = {
val keepScheduling = coresToAssign >= minCoresPerExecutor
val enoughCores = usableWorkers(pos).coresFree - assignedCores(pos) >= minCoresPerExecutor
// If we allow multiple executors per worker, then we can always launch new executors.
// Otherwise, if there is already an executor on this worker, just give it more cores.
val launchingNewExecutor = !oneExecutorPerWorker || assignedExecutors(pos) == 0
if (launchingNewExecutor) {
val assignedMemory = assignedExecutors(pos) * memoryPerExecutor
val enoughMemory = usableWorkers(pos).memoryFree - assignedMemory >= memoryPerExecutor
val underLimit = assignedExecutors.sum + app.executors.size < app.executorLimit
keepScheduling && enoughCores && enoughMemory && underLimit
} else {
// We're adding cores to an existing executor, so no need
// to check memory and executor limits
keepScheduling && enoughCores
}
}
// Keep launching executors until no more workers can accommodate any
// more executors, or if we have reached this application's limits
var freeWorkers = (0 until numUsable).filter(canLaunchExecutor)
while (freeWorkers.nonEmpty) {
freeWorkers.foreach { pos =>
var keepScheduling = true
while (keepScheduling && canLaunchExecutor(pos)) {
coresToAssign -= minCoresPerExecutor
assignedCores(pos) += minCoresPerExecutor
// If we are launching one executor per worker, then every iteration assigns 1 core
// to the executor. Otherwise, every iteration assigns cores to a new executor.
if (oneExecutorPerWorker) {
assignedExecutors(pos) = 1
} else {
assignedExecutors(pos) += 1
}
// Spreading out an application means spreading out its executors across as
// many workers as possible. If we are not spreading out, then we should keep
// scheduling executors on this worker until we use all of its resources.
// Otherwise, just move on to the next worker.
if (spreadOutApps) {
keepScheduling = false
}
}
}
freeWorkers = freeWorkers.filter(canLaunchExecutor)
}
assignedCores
}startExecutorsOnWorkers
/**
* Schedule and launch executors on workers
*/
private def startExecutorsOnWorkers(): Unit = {
// Right now this is a very simple FIFO scheduler. We keep trying to fit in the first app
// in the queue, then the second app, etc.
for (app <- waitingApps if app.coresLeft > 0) {
val coresPerExecutor: Option[Int] = app.desc.coresPerExecutor
// Filter out workers that don't have enough resources to launch an executor
val usableWorkers = workers.toArray.filter(_.state == WorkerState.ALIVE)
.filter(worker => worker.memoryFree >= app.desc.memoryPerExecutorMB &&
worker.coresFree >= coresPerExecutor.getOrElse(1))
.sortBy(_.coresFree).reverse
val assignedCores = scheduleExecutorsOnWorkers(app, usableWorkers, spreadOutApps)
// Now that we've decided how many cores to allocate on each worker, let's allocate them
for (pos <- 0 until usableWorkers.length if assignedCores(pos) > 0) {
allocateWorkerResourceToExecutors( //控制权 回到allocateWorkerResourceToExecutors
app, assignedCores(pos), coresPerExecutor, usableWorkers(pos))
}
}
}allocateWorkerResourceToExecutors
private def allocateWorkerResourceToExecutors(
app: ApplicationInfo,
assignedCores: Int,
coresPerExecutor: Option[Int],
worker: WorkerInfo): Unit = {
// If the number of cores per executor is specified, we divide the cores assigned
// to this worker evenly among the executors with no remainder.
// Otherwise, we launch a single executor that grabs all the assignedCores on this worker.
val numExecutors = coresPerExecutor.map { assignedCores / _ }.getOrElse(1)
val coresToAssign = coresPerExecutor.getOrElse(assignedCores)
for (i <- 1 to numExecutors) {
val exec = app.addExecutor(worker, coresToAssign)
launchExecutor(worker, exec) //启动Executor 给 Worker
app.state = ApplicationState.RUNNING
}
}launchExecutor
private def launchExecutor(worker: WorkerInfo, exec: ExecutorDesc): Unit = {
logInfo("Launching executor " + exec.fullId + " on worker " + worker.id)
worker.addExecutor(exec)
worker.endpoint.send(LaunchExecutor(masterUrl, //给worker发送 LaunchExecutor
exec.application.id, exec.id, exec.application.desc, exec.cores, exec.memory))
exec.application.driver.send(
ExecutorAdded(exec.id, worker.id, worker.hostPort, exec.cores, exec.memory))
}回到Worker
case LaunchExecutor(masterUrl, appId, execId, appDesc, cores_, memory_) =>
if (masterUrl != activeMasterUrl) {
logWarning("Invalid Master (" + masterUrl + ") attempted to launch executor.")
} else {
try {
logInfo("Asked to launch executor %s/%d for %s".format(appId, execId, appDesc.name))
// Create the executor's working directory
val executorDir = new File(workDir, appId + "/" + execId) //创建工作目录
if (!executorDir.mkdirs()) { //如果没有创建
throw new IOException("Failed to create directory " + executorDir)
}
// Create local dirs for the executor. These are passed to the executor via the
// SPARK_EXECUTOR_DIRS environment variable, and deleted by the Worker when the
// application finishes.
val appLocalDirs = appDirectories.getOrElse(appId,
Utils.getOrCreateLocalRootDirs(conf).map { dir =>
val appDir = Utils.createDirectory(dir, namePrefix = "executor")
Utils.chmod700(appDir)
appDir.getAbsolutePath()
}.toSeq)
appDirectories(appId) = appLocalDirs
val manager = new ExecutorRunner( //如果可以
appId,
execId,
appDesc.copy(command = Worker.maybeUpdateSSLSettings(appDesc.command, conf)),
cores_,
memory_,
self,
workerId,
host,
webUi.boundPort,
publicAddress,
sparkHome,
executorDir,
workerUri,
conf,
appLocalDirs, ExecutorState.RUNNING)
executors(appId + "/" + execId) = manager
manager.start() //控制权到了这里
coresUsed += cores_
memoryUsed += memory_
sendToMaster(ExecutorStateChanged(appId, execId, manager.state, None, None)) //给Master发送Executor的资源分配已经好了
} catch {
case e: Exception =>
logError(s"Failed to launch executor $appId/$execId for ${appDesc.name}.", e)
if (executors.contains(appId + "/" + execId)) {
executors(appId + "/" + execId).kill()
executors -= appId + "/" + execId
}
sendToMaster(ExecutorStateChanged(appId, execId, ExecutorState.FAILED,
Some(e.toString), None))
}
}跳转到ExecutorRunner
private[worker] def start() {
workerThread = new Thread("ExecutorRunner for " + fullId) {
override def run() { fetchAndRunExecutor() } //启动Executro我们点进来看一下
}
workerThread.start()
// Shutdown hook that kills actors on shutdown.
shutdownHook = ShutdownHookManager.addShutdownHook { () =>
// It's possible that we arrive here before calling `fetchAndRunExecutor`, then `state` will
// be `ExecutorState.RUNNING`. In this case, we should set `state` to `FAILED`.
if (state == ExecutorState.RUNNING) {
state = ExecutorState.FAILED
}
killProcess(Some("Worker shutting down")) }
}fetchAndRunExecutor
没有特别指出
private def fetchAndRunExecutor() {
try {
// Launch the process
val builder = CommandUtils.buildProcessBuilder(appDesc.command, new SecurityManager(conf),
memory, sparkHome.getAbsolutePath, substituteVariables)
val command = builder.command() //这里的builder应该是processbuilder 运行一个本地命令
val formattedCommand = command.asScala.mkString("\"", "\" \"", "\"")
logInfo(s"Launch command: $formattedCommand")
builder.directory(executorDir)
builder.environment.put("SPARK_EXECUTOR_DIRS", appLocalDirs.mkString(File.pathSeparator))
// In case we are running this from within the Spark Shell, avoid creating a "scala"
// parent process for the executor command
builder.environment.put("SPARK_LAUNCH_WITH_SCALA", "0")
// Add webUI log urls
val baseUrl =
if (conf.getBoolean("spark.ui.reverseProxy", false)) {
s"/proxy/$workerId/logPage/?appId=$appId&executorId=$execId&logType="
} else {
s"http://$publicAddress:$webUiPort/logPage/?appId=$appId&executorId=$execId&logType="
}
builder.environment.put("SPARK_LOG_URL_STDERR", s"${baseUrl}stderr")
builder.environment.put("SPARK_LOG_URL_STDOUT", s"${baseUrl}stdout")
process = builder.start() // 根据流程图 会创建一个 CoarseGrainedSchedulerBackend 我们去哪里看下
val header = "Spark Executor Command: %s\n%s\n\n".format(
formattedCommand, "=" * 40)
// Redirect its stdout and stderr to files
val stdout = new File(executorDir, "stdout")
stdoutAppender = FileAppender(process.getInputStream, stdout, conf)
val stderr = new File(executorDir, "stderr")
Files.write(header, stderr, StandardCharsets.UTF_8)
stderrAppender = FileAppender(process.getErrorStream, stderr, conf)
// Wait for it to exit; executor may exit with code 0 (when driver instructs it to shutdown)
// or with nonzero exit code
val exitCode = process.waitFor()
state = ExecutorState.EXITED
val message = "Command exited with code " + exitCode
worker.send(ExecutorStateChanged(appId, execId, state, Some(message), Some(exitCode)))
} catch {
case interrupted: InterruptedException =>
logInfo("Runner thread for executor " + fullId + " interrupted")
state = ExecutorState.KILLED
killProcess(None)
case e: Exception =>
logError("Error running executor", e)
state = ExecutorState.FAILED
killProcess(Some(e.toString))
}
}回到Master
因为 sendToMaster(ExecutorStateChanged(appId, execId, manager.state, None, None))给Master发送了一条消息
case ExecutorStateChanged(appId, execId, state, message, exitStatus) =>
val execOption = idToApp.get(appId).flatMap(app => app.executors.get(execId))
execOption match {
case Some(exec) =>
val appInfo = idToApp(appId)
val oldState = exec.state
exec.state = state
if (state == ExecutorState.RUNNING) {
assert(oldState == ExecutorState.LAUNCHING,
s"executor $execId state transfer from $oldState to RUNNING is illegal")
appInfo.resetRetryCount()
}
//查看一下ExecutorUpdated 再StandaloneAppClient中
exec.application.driver.send(ExecutorUpdated(execId, state, message, exitStatus, false))
}跳转到StandaloneAppClient
ExecutorUpdated
case ExecutorAdded(id: Int, workerId: String, hostPort: String, cores: Int, memory: Int) =>
val fullId = appId + "/" + id
logInfo(("Ex" +
"ecutor added: %s on %s (%s) with %d cores").format(fullId, workerId, hostPort,
cores))
listener.executorAdded(fullId, workerId, hostPort, cores, memory) //这里的listener
case ExecutorUpdated(id, state, message, exitStatus, workerLost) =>
val fullId = appId + "/" + id
val messageText = message.map(s => " (" + s + ")").getOrElse("")
logInfo("Executor updated: %s is now %s%s".format(fullId, state, messageText))
if (ExecutorState.isFinished(state)) {
listener.executorRemoved(fullId, message.getOrElse(""), exitStatus, workerLost)
} //Executor资源基本完成
case MasterChanged(masterRef, masterWebUiUrl) =>
logInfo("Master has changed, new master is at " + masterRef.address.toSparkURL)
master = Some(masterRef)
alreadyDisconnected = false
masterRef.send(MasterChangeAcknowledged(appId.get))
}listener
private[spark] class StandaloneAppClient(
rpcEnv: RpcEnv,
masterUrls: Array[String],
appDescription: ApplicationDescription,
listener: StandaloneAppClientListener, //这就是Executor中的listener
conf: SparkConf)回到StandaloneSchedulerBackend
private[spark] class StandaloneSchedulerBackend(
scheduler: TaskSchedulerImpl,
sc: SparkContext,
masters: Array[String])
extends CoarseGrainedSchedulerBackend(scheduler, sc.env.rpcEnv)
with StandaloneAppClientListener //继承了那个listner;
with Logging {
....
}StandaloneAppClientListener
private[spark] trait StandaloneAppClientListener {
def connected(appId: String): Unit
/** Disconnection may be a temporary state, as we fail over to a new Master. */
def disconnected(): Unit
/** An application death is an unrecoverable failure condition. */
def dead(reason: String): Unit
def executorAdded(
fullId: String, workerId: String, hostPort: String, cores: Int, memory: Int): Unit
def executorRemoved(
fullId: String, message: String, exitStatus: Option[Int], workerLost: Boolean): Unit
}查看executorAdded
override def executorAdded(fullId: String, workerId: String, hostPort: String, cores: Int,
memory: Int) {
logInfo("Granted executor ID %s on hostPort %s with %d cores, %s RAM".format(
fullId, hostPort, cores, Utils.megabytesToString(memory)))
}到此为止步,Executor进程启动完成.
任务提交和反馈
通过对RDD的观察行动算子最终调用的方法runJob
SparkContext
/**
* Run a function on a given set of partitions in an RDD and pass the results to the given
* handler function. This is the main entry point for all actions in Spark.
*/
def runJob[T, U: ClassTag](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
resultHandler: (Int, U) => Unit): Unit = {
if (stopped.get()) {
throw new IllegalStateException("SparkContext has been shutdown")
}
val callSite = getCallSite
val cleanedFunc = clean(func)
logInfo("Starting job: " + callSite.shortForm)
if (conf.getBoolean("spark.logLineage", false)) {
logInfo("RDD's recursive dependencies:\n" + rdd.toDebugString)
} //我们查看一下dagScheduler
dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler, localProperties.get)
progressBar.foreach(_.finishAll())
rdd.doCheckpoint()
}
/**
* Run a function on a given set of partitions in an RDD and return the results as an array.
*/
def runJob[T, U: ClassTag](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int]): Array[U] = {
val results = new Array[U](partitions.size)
runJob[T, U](rdd, func, partitions, (index, res) => results(index) = res)
results
}
DAGScheduler
runrunJob
/**
* Run an action job on the given RDD and pass all the results to the resultHandler function as
* they arrive.
*
* @param rdd target RDD to run tasks on
* @param func a function to run on each partition of the RDD
* @param partitions set of partitions to run on; some jobs may not want to compute on all
* partitions of the target RDD, e.g. for operations like first()
* @param callSite where in the user program this job was called
* @param resultHandler callback to pass each result to
* @param properties scheduler properties to attach to this job, e.g. fair scheduler pool name
*
* @throws Exception when the job fails
*/
def runJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): Unit = {
val start = System.nanoTime /**提交Job**/
val waiter = submitJob(rdd, func, partitions, callSite, resultHandler, properties)
// Note: Do not call Await.ready(future) because that calls `scala.concurrent.blocking`,
// which causes concurrent SQL executions to fail if a fork-join pool is used. Note that
// due to idiosyncrasies in Scala, `awaitPermission` is not actually used anywhere so it's
// safe to pass in null here. For more detail, see SPARK-13747.
val awaitPermission = null.asInstanceOf[scala.concurrent.CanAwait]
waiter.completionFuture.ready(Duration.Inf)(awaitPermission)
waiter.completionFuture.value.get match {
case scala.util.Success(_) =>
logInfo("Job %d finished: %s, took %f s".format
(waiter.jobId, callSite.shortForm, (System.nanoTime - start) / 1e9))
case scala.util.Failure(exception) =>
logInfo("Job %d failed: %s, took %f s".format
(waiter.jobId, callSite.shortForm, (System.nanoTime - start) / 1e9))
// SPARK-8644: Include user stack trace in exceptions coming from DAGScheduler.
val callerStackTrace = Thread.currentThread().getStackTrace.tail
exception.setStackTrace(exception.getStackTrace ++ callerStackTrace)
throw exception
}
}submitJob
def submitJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): JobWaiter[U] = {
// Check to make sure we are not launching a task on a partition that does not exist.
val maxPartitions = rdd.partitions.length
partitions.find(p => p >= maxPartitions || p < 0).foreach { p =>
throw new IllegalArgumentException(
"Attempting to access a non-existent partition: " + p + ". " +
"Total number of partitions: " + maxPartitions)
}
val jobId = nextJobId.getAndIncrement()
if (partitions.size == 0) {
// Return immediately if the job is running 0 tasks
return new JobWaiter[U](this, jobId, 0, resultHandler)
}
assert(partitions.size > 0)
val func2 = func.asInstanceOf[(TaskContext, Iterator[_]) => _]
val waiter = new JobWaiter(this, jobId, partitions.size, resultHandler)
eventProcessLoop.post(JobSubmitted( //post一个JobSubmitted事件
jobId, rdd, func2, partitions.toArray, callSite, waiter,
SerializationUtils.clone(properties)))
waiter
}eventProcessLoop
private[scheduler] val eventProcessLoop = new DAGSchedulerEventProcessLoop(this)
taskScheduler.setDAGScheduler(this)DAGSchedulerEventProcessLoop
private[scheduler] class DAGSchedulerEventProcessLoop(dagScheduler: DAGScheduler)
extends EventLoop[DAGSchedulerEvent]("dag-scheduler-event-loop") with Logging { //点击EventLoop
....
}
}EventLoop
private[spark] abstract class EventLoop[E](name: String) extends Logging {
private val eventQueue: BlockingQueue[E] = new LinkedBlockingDeque[E]() //阻塞队列
private val stopped = new AtomicBoolean(false)
private val eventThread = new Thread(name) {
setDaemon(true)
override def run(): Unit = { //run方法
try {
while (!stopped.get) {
val event = eventQueue.take() //循环读取队列
try { //读到序列
onReceive(event) //开启
} catch {
case NonFatal(e) =>
try {
onError(e)
} catch {
case NonFatal(e) => logError("Unexpected error in " + name, e)
}
}
}
} catch {
case ie: InterruptedException => // exit even if eventQueue is not empty
case NonFatal(e) => logError("Unexpected error in " + name, e)
}
}
}
....
protected def onReceive(event: E): Unit //抽象方法回到DAGSchedulerEventProcessLoop
override def onReceive(event: DAGSchedulerEvent): Unit = {
val timerContext = timer.time()
try {
doOnReceive(event)
} finally {
timerContext.stop()
}
}
private def doOnReceive(event: DAGSchedulerEvent): Unit = event match {
case JobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties) =>
dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties) //我们关住一下handleJobSubmitted
case MapStageSubmitted(jobId, dependency, callSite, listener, properties) =>
dagScheduler.handleMapStageSubmitted(jobId, dependency, callSite, listener, properties)
case StageCancelled(stageId) =>
dagScheduler.handleStageCancellation(stageId)
case JobCancelled(jobId) =>
dagScheduler.handleJobCancellation(jobId)
case JobGroupCancelled(groupId) =>
dagScheduler.handleJobGroupCancelled(groupId)
case AllJobsCancelled =>
dagScheduler.doCancelAllJobs()
case ExecutorAdded(execId, host) =>
dagScheduler.handleExecutorAdded(execId, host)
case ExecutorLost(execId, reason) =>
val filesLost = reason match {
case SlaveLost(_, true) => true
case _ => false
}
dagScheduler.handleExecutorLost(execId, filesLost)
case BeginEvent(task, taskInfo) =>
dagScheduler.handleBeginEvent(task, taskInfo)
case GettingResultEvent(taskInfo) =>
dagScheduler.handleGetTaskResult(taskInfo)
case completion: CompletionEvent =>
dagScheduler.handleTaskCompletion(completion)
case TaskSetFailed(taskSet, reason, exception) =>
dagScheduler.handleTaskSetFailed(taskSet, reason, exception)
case ResubmitFailedStages =>
dagScheduler.resubmitFailedStages()
}handleJobSubmitted
private[scheduler] def handleJobSubmitted(jobId: Int,
finalRDD: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties) {
//一下代码是如何将代码拆分成一个个stage 再把
var finalStage: ResultStage = null
try {
// New stage creation may throw an exception if, for example, jobs are run on a
// HadoopRDD whose underlying HDFS files have been deleted.
finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite)
} catch {
case e: Exception =>
logWarning("Creating new stage failed due to exception - job: " + jobId, e)
listener.jobFailed(e)
return
}
val job = new ActiveJob(jobId, finalStage, callSite, listener, properties)
clearCacheLocs()
logInfo("Got job %s (%s) with %d output partitions".format(
job.jobId, callSite.shortForm, partitions.length))
logInfo("Final stage: " + finalStage + " (" + finalStage.name + ")")
logInfo("Parents of final stage: " + finalStage.parents)
logInfo("Missing parents: " + getMissingParentStages(finalStage))
val jobSubmissionTime = clock.getTimeMillis()
jobIdToActiveJob(jobId) = job
activeJobs += job
finalStage.setActiveJob(job)
val stageIds = jobIdToStageIds(jobId).toArray
val stageInfos = stageIds.flatMap(id => stageIdToStage.get(id).map(_.latestInfo))
listenerBus.post(
SparkListenerJobStart(job.jobId, jobSubmissionTime, stageInfos, properties))
//最后提交了submitStage
submitStage(finalStage)
} submitStage
/** Submits stage, but first recursively submits any missing parents. */
private def submitStage(stage: Stage) {
val jobId = activeJobForStage(stage)
if (jobId.isDefined) {
logDebug("submitStage(" + stage + ")")
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
//stage是从后往前划分
val missing = getMissingParentStages(stage).sortBy(_.id)
logDebug("missing: " + missing)
if (missing.isEmpty) {
logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents")
submitMissingTasks(stage, jobId.get)
} else { //如果获得了missing 我们卡产一下是怎么处理的
for (parent <- missing) {
submitStage(parent)
}
waitingStages += stage
}
}
} else {
abortStage(stage, "No active job for stage " + stage.id, None)
}
}getMissingParentStages
private def getMissingParentStages(stage: Stage): List[Stage] = {
val missing = new HashSet[Stage]
val visited = new HashSet[RDD[_]]
// We are manually maintaining a stack here to prevent StackOverflowError
// caused by recursively visiting
val waitingForVisit = new Stack[RDD[_]] //栈结构的 这是为什么Stage划分从后往前 压栈执行
def visit(rdd: RDD[_]) {
if (!visited(rdd)) {
visited += rdd
val rddHasUncachedPartitions = getCacheLocs(rdd).contains(Nil)
if (rddHasUncachedPartitions) {
for (dep <- rdd.dependencies) {
dep match {
case shufDep: ShuffleDependency[_, _, _] => //如果是 宽依赖
val mapStage = getOrCreateShuffleMapStage(shufDep, stage.firstJobId)
if (!mapStage.isAvailable) {
missing += mapStage
}
case narrowDep: NarrowDependency[_] => //如果是窄依赖
waitingForVisit.push(narrowDep.rdd) //主要是填充stage
}
}
}
}
}
waitingForVisit.push(stage.rdd)
while (waitingForVisit.nonEmpty) {
visit(waitingForVisit.pop())
}
missing.toList
}submitStage
/** Submits stage, but first recursively submits any missing parents. */
private def submitStage(stage: Stage) {
val jobId = activeJobForStage(stage)
if (jobId.isDefined) {
logDebug("submitStage(" + stage + ")")
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
val missing = getMissingParentStages(stage).sortBy(_.id)
logDebug("missing: " + missing)
if (missing.isEmpty) {
logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents")
submitMissingTasks(stage, jobId.get)//递归调用
} else {
for (parent <- missing) {
submitStage(parent) //递归
}
waitingStages += stage
}
}
} else {
abortStage(stage, "No active job for stage " + stage.id, None)
}
}submitMissingTasks
/** Called when stage's parents are available and we can now do its task. */
private def submitMissingTasks(stage: Stage, jobId: Int) {
logDebug("submitMissingTasks(" + stage + ")")
// Get our pending tasks and remember them in our pendingTasks entry
stage.pendingPartitions.clear()
// First figure out the indexes of partition ids to compute.
val partitionsToCompute: Seq[Int] = stage.findMissingPartitions()
// Use the scheduling pool, job group, description, etc. from an ActiveJob associated
// with this Stage
val properties = jobIdToActiveJob(jobId).properties
runningStages += stage
// SparkListenerStageSubmitted should be posted before testing whether tasks are
// serializable. If tasks are not serializable, a SparkListenerStageCompleted event
// will be posted, which should always come after a corresponding SparkListenerStageSubmitted
// event.
stage match {
case s: ShuffleMapStage =>
outputCommitCoordinator.stageStart(stage = s.id, maxPartitionId = s.numPartitions - 1)
case s: ResultStage =>
outputCommitCoordinator.stageStart(
stage = s.id, maxPartitionId = s.rdd.partitions.length - 1)
}
val taskIdToLocations: Map[Int, Seq[TaskLocation]] = try {
stage match {
case s: ShuffleMapStage =>
partitionsToCompute.map { id => (id, getPreferredLocs(stage.rdd, id))}.toMap
case s: ResultStage =>
partitionsToCompute.map { id =>
val p = s.partitions(id)
(id, getPreferredLocs(stage.rdd, p))
}.toMap
}
} catch {
case NonFatal(e) =>
stage.makeNewStageAttempt(partitionsToCompute.size)
listenerBus.post(SparkListenerStageSubmitted(stage.latestInfo, properties))
abortStage(stage, s"Task creation failed: $e\n${Utils.exceptionString(e)}", Some(e))
runningStages -= stage
return
}
stage.makeNewStageAttempt(partitionsToCompute.size, taskIdToLocations.values.toSeq)
listenerBus.post(SparkListenerStageSubmitted(stage.latestInfo, properties))
// TODO: Maybe we can keep the taskBinary in Stage to avoid serializing it multiple times.
// Broadcasted binary for the task, used to dispatch tasks to executors. Note that we broadcast
// the serialized copy of the RDD and for each task we will deserialize it, which means each
// task gets a different copy of the RDD. This provides stronger isolation between tasks that
// might modify state of objects referenced in their closures. This is necessary in Hadoop
// where the JobConf/Configuration object is not thread-safe.
var taskBinary: Broadcast[Array[Byte]] = null
try {
// For ShuffleMapTask, serialize and broadcast (rdd, shuffleDep).
// For ResultTask, serialize and broadcast (rdd, func).
val taskBinaryBytes: Array[Byte] = stage match {
case stage: ShuffleMapStage =>
JavaUtils.bufferToArray(
closureSerializer.serialize((stage.rdd, stage.shuffleDep): AnyRef))
case stage: ResultStage =>
JavaUtils.bufferToArray(closureSerializer.serialize((stage.rdd, stage.func): AnyRef))
}
taskBinary = sc.broadcast(taskBinaryBytes)
} catch {
// In the case of a failure during serialization, abort the stage.
case e: NotSerializableException =>
abortStage(stage, "Task not serializable: " + e.toString, Some(e))
runningStages -= stage
// Abort execution
return
case NonFatal(e) =>
abortStage(stage, s"Task serialization failed: $e\n${Utils.exceptionString(e)}", Some(e))
runningStages -= stage
return
}
val tasks: Seq[Task[_]] = try { //转换成一系列Task任务
stage match {
case stage: ShuffleMapStage =>
partitionsToCompute.map { id =>
val locs = taskIdToLocations(id)
val part = stage.rdd.partitions(id)
new ShuffleMapTask(stage.id, stage.latestInfo.attemptId,
taskBinary, part, locs, stage.latestInfo.taskMetrics, properties, Option(jobId),
Option(sc.applicationId), sc.applicationAttemptId)
}
case stage: ResultStage =>
partitionsToCompute.map { id =>
val p: Int = stage.partitions(id)
val part = stage.rdd.partitions(p)
val locs = taskIdToLocations(id)
new ResultTask(stage.id, stage.latestInfo.attemptId,
taskBinary, part, locs, id, properties, stage.latestInfo.taskMetrics,
Option(jobId), Option(sc.applicationId), sc.applicationAttemptId)
}
}
} catch {
case NonFatal(e) =>
abortStage(stage, s"Task creation failed: $e\n${Utils.exceptionString(e)}", Some(e))
runningStages -= stage
return
}
if (tasks.size > 0) {
logInfo("Submitting " + tasks.size + " missing tasks from " + stage + " (" + stage.rdd + ")")
stage.pendingPartitions ++= tasks.map(_.partitionId)
logDebug("New pending partitions: " + stage.pendingPartitions)
taskScheduler.submitTasks(new TaskSet( //提交我们的任务,把我们所有的的任务封装成了一个对象
tasks.toArray, stage.id, stage.latestInfo.attemptId, jobId, properties))
stage.latestInfo.submissionTime = Some(clock.getTimeMillis())
} else {
// Because we posted SparkListenerStageSubmitted earlier, we should mark
// the stage as completed here in case there are no tasks to run
markStageAsFinished(stage, None)
val debugString = stage match {
case stage: ShuffleMapStage =>
s"Stage ${stage} is actually done; " +
s"(available: ${stage.isAvailable}," +
s"available outputs: ${stage.numAvailableOutputs}," +
s"partitions: ${stage.numPartitions})"
case stage : ResultStage =>
s"Stage ${stage} is actually done; (partitions: ${stage.numPartitions})"
}
logDebug(debugString)
submitWaitingChildStages(stage)
}
}submitTasks
def submitTasks(taskSet: TaskSet): Unit
找到实现类
跳转TaskSchedulerImpl
submitTasks
override def submitTasks(taskSet: TaskSet) {
val tasks = taskSet.tasks
logInfo("Adding task set " + taskSet.id + " with " + tasks.length + " tasks")
this.synchronized { //同步
val manager = createTaskSetManager(taskSet, maxTaskFailures)
val stage = taskSet.stageId
val stageTaskSets =
taskSetsByStageIdAndAttempt.getOrElseUpdate(stage, new HashMap[Int, TaskSetManager])
stageTaskSets(taskSet.stageAttemptId) = manager
val conflictingTaskSet = stageTaskSets.exists { case (_, ts) =>
ts.taskSet != taskSet && !ts.isZombie
}
if (conflictingTaskSet) {
throw new IllegalStateException(s"more than one active taskSet for stage $stage:" +
s" ${stageTaskSets.toSeq.map{_._2.taskSet.id}.mkString(",")}")
}
schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties)
if (!isLocal && !hasReceivedTask) {
starvationTimer.scheduleAtFixedRate(new TimerTask() {
override def run() {
if (!hasLaunchedTask) {
logWarning("Initial job has not accepted any resources; " +
"check your cluster UI to ensure that workers are registered " +
"and have sufficient resources")
} else {
this.cancel()
}
}
}, STARVATION_TIMEOUT_MS, STARVATION_TIMEOUT_MS)
}
hasReceivedTask = true
}
backend.reviveOffers() //这个backend再StandaloneSchedulerBackend出现过
}在tandaloneSchedulerBackend没有找到.我们去CoarseGrainedSchedulerBackend中寻找一下
回到CoarseGrainedSchedulerBackend
case ReviveOffers =>
makeOffers() //跳转到
...
override def reviveOffers() {
driverEndpoint.send(ReviveOffers) //
}makeOffers
// Make fake resource offers on all executors
private def makeOffers() {
// Filter out executors under killing
val activeExecutors = executorDataMap.filterKeys(executorIsAlive)
val workOffers = activeExecutors.map { case (id, executorData) =>
new WorkerOffer(id, executorData.executorHost, executorData.freeCores)
}.toIndexedSeq
launchTasks(scheduler.resourceOffers(workOffers //运行任务 申请资源 resourceOffers 具体做关键资源
}跳转TaskSchedulerImpl
resourceOffers
/**
* Called by cluster manager to offer resources on slaves. We respond by asking our active task
* sets for tasks in order of priority. We fill each node with tasks in a round-robin manner so
* that tasks are balanced across the cluster.
*/
// 该类具体做具体的资源分配
def resourceOffers(offers: IndexedSeq[WorkerOffer]): Seq[Seq[TaskDescription]] = synchronized {
// Mark each slave as alive and remember its hostname
// Also track if new executor is added
var newExecAvail = false
for (o <- offers) {
if (!hostToExecutors.contains(o.host)) {
hostToExecutors(o.host) = new HashSet[String]()
}
if (!executorIdToRunningTaskIds.contains(o.executorId)) {
hostToExecutors(o.host) += o.executorId
executorAdded(o.executorId, o.host)
executorIdToHost(o.executorId) = o.host
executorIdToRunningTaskIds(o.executorId) = HashSet[Long]()
newExecAvail = true
}
for (rack <- getRackForHost(o.host)) {
hostsByRack.getOrElseUpdate(rack, new HashSet[String]()) += o.host
}
}
// Randomly shuffle offers to avoid always placing tasks on the same set of workers.
val shuffledOffers = Random.shuffle(offers)
// Build a list of tasks to assign to each worker.
val tasks = shuffledOffers.map(o => new ArrayBuffer[TaskDescription](o.cores))
val availableCpus = shuffledOffers.map(o => o.cores).toArray
val sortedTaskSets = rootPool.getSortedTaskSetQueue
for (taskSet <- sortedTaskSets) {
logDebug("parentName: %s, name: %s, runningTasks: %s".format(
taskSet.parent.name, taskSet.name, taskSet.runningTasks))
if (newExecAvail) {
taskSet.executorAdded()
}
}
// Take each TaskSet in our scheduling order, and then offer it each node in increasing order
// of locality levels so that it gets a chance to launch local tasks on all of them.
// NOTE: the preferredLocality order: PROCESS_LOCAL, NODE_LOCAL, NO_PREF, RACK_LOCAL, ANY
for (taskSet <- sortedTaskSets) {
var launchedAnyTask = false
var launchedTaskAtCurrentMaxLocality = false
for (currentMaxLocality <- taskSet.myLocalityLevels) {
do {
launchedTaskAtCurrentMaxLocality = resourceOfferSingleTaskSet(
taskSet, currentMaxLocality, shuffledOffers, availableCpus, tasks)
launchedAnyTask |= launchedTaskAtCurrentMaxLocality
} while (launchedTaskAtCurrentMaxLocality)
}
if (!launchedAnyTask) {
taskSet.abortIfCompletelyBlacklisted(hostToExecutors)
}
}
if (tasks.size > 0) {
hasLaunchedTask = true
}
return tasks
}回到CoarseGrainedSchedulerBackend
// Launch tasks returned by a set of resource offers
private def launchTasks(tasks: Seq[Seq[TaskDescription]]) {
for (task <- tasks.flatten) {
val serializedTask = ser.serialize(task)
if (serializedTask.limit >= maxRpcMessageSize) {
scheduler.taskIdToTaskSetManager.get(task.taskId).foreach { taskSetMgr =>
try {
var msg = "Serialized task %s:%d was %d bytes, which exceeds max allowed: " +
"spark.rpc.message.maxSize (%d bytes). Consider increasing " +
"spark.rpc.message.maxSize or using broadcast variables for large values."
msg = msg.format(task.taskId, task.index, serializedTask.limit, maxRpcMessageSize)
taskSetMgr.abort(msg)
} catch {
case e: Exception => logError("Exception in error callback", e)
}
}
}
else {
val executorData = executorDataMap(task.executorId)
executorData.freeCores -= scheduler.CPUS_PER_TASK
logDebug(s"Launching task ${task.taskId} on executor id: ${task.executorId} hostname: " +
s"${executorData.executorHost}.")
//控制权转到CoarseGrainedExecutorBackend的LaunchTask
executorData.executorEndpoint.send(LaunchTask(new SerializableBuffer(serializedTask)))
}
}
}跳转CoarseGrainedExecutorBackend
LaunchTask
case LaunchTask(data) =>
if (executor == null) {
exitExecutor(1, "Received LaunchTask command but executor was null")
} else {
val taskDesc = ser.deserialize[TaskDescription](data.value)
logInfo("Got assigned task " + taskDesc.taskId) //调用executor的launchTask
executor.launchTask(this, taskId = taskDesc.taskId, attemptNumber = taskDesc.attemptNumber,
taskDesc.name, taskDesc.serializedTask)
}跳转到Executor
launchTask
def launchTask(
context: ExecutorBackend,
taskId: Long,
attemptNumber: Int,
taskName: String,
serializedTask: ByteBuffer): Unit = {
//创建一个TaskRunner
val tr = new TaskRunner(context, taskId = taskId, attemptNumber = attemptNumber, taskName,
serializedTask)
runningTasks.put(taskId, tr)
threadPool.execute(tr) //线程池
}TaskRunner
我们关注一下run方法 上面的西线程池运行的是此处的润方法
override def run(): Unit = {
threadId = Thread.currentThread.getId
Thread.currentThread.setName(threadName)
val threadMXBean = ManagementFactory.getThreadMXBean
val taskMemoryManager = new TaskMemoryManager(env.memoryManager, taskId)
val deserializeStartTime = System.currentTimeMillis()
val deserializeStartCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime
} else 0L
Thread.currentThread.setContextClassLoader(replClassLoader)
val ser = env.closureSerializer.newInstance()
logInfo(s"Running $taskName (TID $taskId)")
execBackend.statusUpdate(taskId, TaskState.RUNNING, EMPTY_BYTE_BUFFER)
var taskStart: Long = 0
var taskStartCpu: Long = 0
startGCTime = computeTotalGcTime()
try {
val (taskFiles, taskJars, taskProps, taskBytes) =
Task.deserializeWithDependencies(serializedTask)
// Must be set before updateDependencies() is called, in case fetching dependencies
// requires access to properties contained within (e.g. for access control).
Executor.taskDeserializationProps.set(taskProps)
updateDependencies(taskFiles, taskJars)
task = ser.deserialize[Task[Any]](taskBytes, Thread.currentThread.getContextClassLoader)
task.localProperties = taskProps
task.setTaskMemoryManager(taskMemoryManager)
// If this task has been killed before we deserialized it, let's quit now. Otherwise,
// continue executing the task.
if (killed) {
// Throw an exception rather than returning, because returning within a try{} block
// causes a NonLocalReturnControl exception to be thrown. The NonLocalReturnControl
// exception will be caught by the catch block, leading to an incorrect ExceptionFailure
// for the task.
throw new TaskKilledException
}
logDebug("Task " + taskId + "'s epoch is " + task.epoch)
env.mapOutputTracker.updateEpoch(task.epoch)
// Run the actual task and measure its runtime.
taskStart = System.currentTimeMillis()
taskStartCpu = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime
} else 0L
var threwException = true
val value = try {
val res = task.run(
taskAttemptId = taskId,
attemptNumber = attemptNumber,
metricsSystem = env.metricsSystem)
threwException = false
res
} finally {
val releasedLocks = env.blockManager.releaseAllLocksForTask(taskId)
val freedMemory = taskMemoryManager.cleanUpAllAllocatedMemory()
if (freedMemory > 0 && !threwException) {
val errMsg = s"Managed memory leak detected; size = $freedMemory bytes, TID = $taskId"
if (conf.getBoolean("spark.unsafe.exceptionOnMemoryLeak", false)) {
throw new SparkException(errMsg)
} else {
logWarning(errMsg)
}
}
if (releasedLocks.nonEmpty && !threwException) {
val errMsg =
s"${releasedLocks.size} block locks were not released by TID = $taskId:\n" +
releasedLocks.mkString("[", ", ", "]")
if (conf.getBoolean("spark.storage.exceptionOnPinLeak", false)) {
throw new SparkException(errMsg)
} else {
logWarning(errMsg)
}
}
}
val taskFinish = System.currentTimeMillis()
val taskFinishCpu = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime
} else 0L
// If the task has been killed, let's fail it.
if (task.killed) {
throw new TaskKilledException
}
val resultSer = env.serializer.newInstance()
val beforeSerialization = System.currentTimeMillis()
val valueBytes = resultSer.serialize(value)
val afterSerialization = System.currentTimeMillis()
// Deserialization happens in two parts: first, we deserialize a Task object, which
// includes the Partition. Second, Task.run() deserializes the RDD and function to be run.
task.metrics.setExecutorDeserializeTime(
(taskStart - deserializeStartTime) + task.executorDeserializeTime)
task.metrics.setExecutorDeserializeCpuTime(
(taskStartCpu - deserializeStartCpuTime) + task.executorDeserializeCpuTime)
// We need to subtract Task.run()'s deserialization time to avoid double-counting
task.metrics.setExecutorRunTime((taskFinish - taskStart) - task.executorDeserializeTime)
task.metrics.setExecutorCpuTime(
(taskFinishCpu - taskStartCpu) - task.executorDeserializeCpuTime)
task.metrics.setJvmGCTime(computeTotalGcTime() - startGCTime)
task.metrics.setResultSerializationTime(afterSerialization - beforeSerialization)
// Note: accumulator updates must be collected after TaskMetrics is updated
val accumUpdates = task.collectAccumulatorUpdates()
// TODO: do not serialize value twice
val directResult = new DirectTaskResult(valueBytes, accumUpdates)
val serializedDirectResult = ser.serialize(directResult)
val resultSize = serializedDirectResult.limit
// directSend = sending directly back to the driver
val serializedResult: ByteBuffer = {
if (maxResultSize > 0 && resultSize > maxResultSize) {
logWarning(s"Finished $taskName (TID $taskId). Result is larger than maxResultSize " +
s"(${Utils.bytesToString(resultSize)} > ${Utils.bytesToString(maxResultSize)}), " +
s"dropping it.")
ser.serialize(new IndirectTaskResult[Any](TaskResultBlockId(taskId), resultSize))
} else if (resultSize > maxDirectResultSize) {
val blockId = TaskResultBlockId(taskId)
env.blockManager.putBytes(
blockId,
new ChunkedByteBuffer(serializedDirectResult.duplicate()),
StorageLevel.MEMORY_AND_DISK_SER)
logInfo(
s"Finished $taskName (TID $taskId). $resultSize bytes result sent via BlockManager)")
ser.serialize(new IndirectTaskResult[Any](blockId, resultSize))
} else {
logInfo(s"Finished $taskName (TID $taskId). $resultSize bytes result sent to driver")
serializedDirectResult
}
}
//无论失败与否发送一个状态statusUpdate 点击statusUpdate 我们查看一下
execBackend.statusUpdate(taskId, TaskState.FINISHED, serializedResult)
} catch {
case ffe: FetchFailedException =>
val reason = ffe.toTaskFailedReason
setTaskFinishedAndClearInterruptStatus()
execBackend.statusUpdate(taskId, TaskState.FAILED, ser.serialize(reason))
case _: TaskKilledException =>
logInfo(s"Executor killed $taskName (TID $taskId)")
setTaskFinishedAndClearInterruptStatus()
execBackend.statusUpdate(taskId, TaskState.KILLED, ser.serialize(TaskKilled))
case _: InterruptedException if task.killed =>
logInfo(s"Executor interrupted and killed $taskName (TID $taskId)")
setTaskFinishedAndClearInterruptStatus()
execBackend.statusUpdate(taskId, TaskState.KILLED, ser.serialize(TaskKilled))
case CausedBy(cDE: CommitDeniedException) =>
val reason = cDE.toTaskFailedReason
setTaskFinishedAndClearInterruptStatus()
execBackend.statusUpdate(taskId, TaskState.FAILED, ser.serialize(reason))
case t: Throwable =>
// Attempt to exit cleanly by informing the driver of our failure.
// If anything goes wrong (or this was a fatal exception), we will delegate to
// the default uncaught exception handler, which will terminate the Executor.
logError(s"Exception in $taskName (TID $taskId)", t)
// Collect latest accumulator values to report back to the driver
val accums: Seq[AccumulatorV2[_, _]] =
if (task != null) {
task.metrics.setExecutorRunTime(System.currentTimeMillis() - taskStart)
task.metrics.setJvmGCTime(computeTotalGcTime() - startGCTime)
task.collectAccumulatorUpdates(taskFailed = true)
} else {
Seq.empty
}
val accUpdates = accums.map(acc => acc.toInfo(Some(acc.value), None))
val serializedTaskEndReason = {
try {
ser.serialize(new ExceptionFailure(t, accUpdates).withAccums(accums))
} catch {
case _: NotSerializableException =>
// t is not serializable so just send the stacktrace
ser.serialize(new ExceptionFailure(t, accUpdates, false).withAccums(accums))
}
}
setTaskFinishedAndClearInterruptStatus()
execBackend.statusUpdate(taskId, TaskState.FAILED, serializedTaskEndReason)
// Don't forcibly exit unless the exception was inherently fatal, to avoid
// stopping other tasks unnecessarily.
if (Utils.isFatalError(t)) {
SparkUncaughtExceptionHandler.uncaughtException(t)
}
} finally {
runningTasks.remove(taskId)
}
}
}
statusUpdate
private[spark] trait ExecutorBackend {
def statusUpdate(taskId: Long, state: TaskState, data: ByteBuffer): Unit
}
override def statusUpdate(taskId: Long, state: TaskState, data: ByteBuffer) {
val msg = StatusUpdate(executorId, taskId, state, data)
driver match {
case Some(driverRef) => driverRef.send(msg) //给driver发送了一条消息 控制权回到Driver
case None => logWarning(s"Drop $msg because has not yet connected to driver")
}
}回到CoarseGrainedSchedulerBackend
override def receive: PartialFunction[Any, Unit] = {
case StatusUpdate(executorId, taskId, state, data) =>
scheduler.statusUpdate(taskId, state, data.value) //调用了scheduler(TaskSchedulerImpl)的statusUpdate方法
if (TaskState.isFinished(state)) { //如果任务结束了
executorDataMap.get(executorId) match {
case Some(executorInfo) => //如果还有executor的资源
executorInfo.freeCores += scheduler.CPUS_PER_TASK
makeOffers(executorId) //继续调度
case None =>
// Ignoring the update since we don't know about the executor.
logWarning(s"Ignored task status update ($taskId state $state) " +
s"from unknown executor with ID $executorId")
}
}回到TaskSchedulerImpl
statusUpdate
def statusUpdate(tid: Long, state: TaskState, serializedData: ByteBuffer) {
var failedExecutor: Option[String] = None
var reason: Option[ExecutorLossReason] = None
synchronized {
try {
taskIdToTaskSetManager.get(tid) match {
case Some(taskSet) =>
if (state == TaskState.LOST) { //如果所有的任务状态都完成了
// TaskState.LOST is only used by the deprecated Mesos fine-grained scheduling mode,
// where each executor corresponds to a single task, so mark the executor as failed.
val execId = taskIdToExecutorId.getOrElse(tid, throw new IllegalStateException(
"taskIdToTaskSetManager.contains(tid) <=> taskIdToExecutorId.contains(tid)"))
if (executorIdToRunningTaskIds.contains(execId)) {
reason = Some(
SlaveLost(s"Task $tid was lost, so marking the executor as lost as well."))
removeExecutor(execId, reason.get) //删除Executor
failedExecutor = Some(execId)
}
}
if (TaskState.isFinished(state)) {
cleanupTaskState(tid)
taskSet.removeRunningTask(tid)
if (state == TaskState.FINISHED) {
taskResultGetter.enqueueSuccessfulTask(taskSet, tid, serializedData)
} else if (Set(TaskState.FAILED, TaskState.KILLED, TaskState.LOST).contains(state)) {
taskResultGetter.enqueueFailedTask(taskSet, tid, state, serializedData)
}
}
case None =>
logError(
("Ignoring update with state %s for TID %s because its task set is gone (this is " +
"likely the result of receiving duplicate task finished status updates) or its " +
"executor has been marked as failed.")
.format(state, tid))
}
} catch {
case e: Exception => logError("Exception in statusUpdate", e)
}
}
// Update the DAGScheduler without holding a lock on this, since that can deadlock
if (failedExecutor.isDefined) {
assert(reason.isDefined)
dagScheduler.executorLost(failedExecutor.get, reason.get)
backend.reviveOffers()
}
}至此任务提交已经基本完成。

