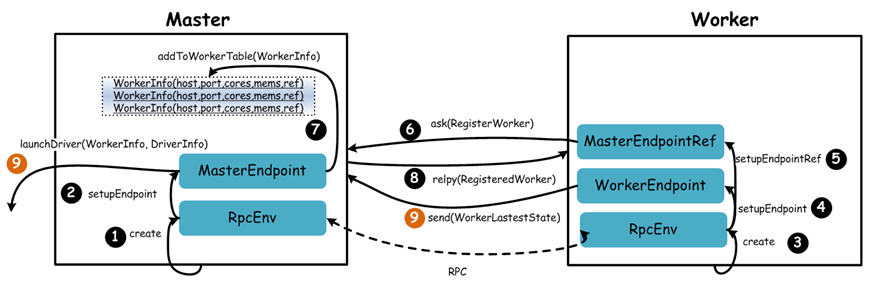
Master启动时首先创一个RpcEnv对象,负责管理所有通信逻辑
Master通过RpcEnv对象创建一个Endpoint,Master就是一个Endpoint,Worker可以与其进行通信
Worker启动时也是创一个RpcEnv对象
Worker通过RpcEnv对象创建一个Endpoint
Worker通过RpcEnv对,建立到Master的连接,获取到一个RpcEndpointRef对象,通过该对象可以与Master通信
Worker向Master注册,注册内容包括主机名、端口、CPU Core数量、内存数量
Master接收到Worker的注册,将注册信息维护在内存中的Table中,其中还包含了一个到Worker的RpcEndpointRef对象引用
Master回复Worker已经接收到注册,告知Worker已经注册成功
此时如果有用户提交Spark程序,Master需要协调启动Driver;而Worker端收到成功注册响应后,开始周期性向Master发送心跳
Mster
Master的main方法启动创建了一个startRpcEnvAndEndpoint
def main(argStrings: Array[String]) {
// 1、初始化log对象
Utils.initDaemon(log)
// 2、加载SparkConf
val conf = new SparkConf
// 3、解析Master启动参数
val args = new MasterArguments(argStrings, conf)
// 4、启动RPC框架端点
val (rpcEnv, _, _) = startRpcEnvAndEndpoint(args.host, args.port, args.webUiPort, conf)
rpcEnv.awaitTermination()
}我们点击startRpcEnvAndEndpoint查看中创建了一个Master
def startRpcEnvAndEndpoint(
host: String,
port: Int,
webUiPort: Int,
conf: SparkConf): (RpcEnv, Int, Option[Int]) = {
val securityMgr = new SecurityManager(conf)
val rpcEnv = RpcEnv.create(SYSTEM_NAME, host, port, conf, securityMgr)
val masterEndpoint = rpcEnv.setupEndpoint(ENDPOINT_NAME,
new Master(rpcEnv, rpcEnv.address, webUiPort, securityMgr, conf)) //创建一个Master
val portsResponse = masterEndpoint.askWithRetry[BoundPortsResponse](BoundPortsRequest)
(rpcEnv, portsResponse.webUIPort, portsResponse.restPort)
}
}在Master中我们重点关注一下onStart()方法,绑定WebUI,和定期心跳检测
override def onStart(): Unit = {
logInfo("Starting Spark master at " + masterUrl)
logInfo(s"Running Spark version ${org.apache.spark.SPARK_VERSION}")
webUi = new MasterWebUI(this, webUiPort)
webUi.bind()
masterWebUiUrl = "http://" + masterPublicAddress + ":" + webUi.boundPort
if (reverseProxy) {
masterWebUiUrl = conf.get("spark.ui.reverseProxyUrl", masterWebUiUrl)
logInfo(s"Spark Master is acting as a reverse proxy. Master, Workers and " +
s"Applications UIs are available at $masterWebUiUrl")
}
checkForWorkerTimeOutTask = forwardMessageThread.scheduleAtFixedRate(new Runnable {
override def run(): Unit = Utils.tryLogNonFatalError {
self.send(CheckForWorkerTimeOut) //周期性的自己给自己发送一条消息
}
}, 0, WORKER_TIMEOUT_MS, TimeUnit.MILLISECONDS) //WORKER_TIMEOUT_MS为60*1000 也就是一分钟超时时间为1分钟
if (restServerEnabled) {
val port = conf.getInt("spark.master.rest.port", 6066)
restServer = Some(new StandaloneRestServer(address.host, port, conf, self, masterUrl))
}
restServerBoundPort = restServer.map(_.start())
masterMetricsSystem.registerSource(masterSource)
masterMetricsSystem.start()
applicationMetricsSystem.start()
// Attach the master and app metrics servlet handler to the web ui after the metrics systems are
// started.
masterMetricsSystem.getServletHandlers.foreach(webUi.attachHandler)
applicationMetricsSystem.getServletHandlers.foreach(webUi.attachHandler)
val serializer = new JavaSerializer(conf)
val (persistenceEngine_, leaderElectionAgent_) = RECOVERY_MODE match { //RECOVERY_MODE是否设置
case "ZOOKEEPER" =>
logInfo("Persisting recovery state to ZooKeeper")
val zkFactory =
new ZooKeeperRecoveryModeFactory(conf, serializer)
(zkFactory.createPersistenceEngine(), zkFactory.createLeaderElectionAgent(this))
case "FILESYSTEM" =>
val fsFactory =
new FileSystemRecoveryModeFactory(conf, serializer)
(fsFactory.createPersistenceEngine(), fsFactory.createLeaderElectionAgent(this))
case "CUSTOM" =>
val clazz = Utils.classForName(conf.get("spark.deploy.recoveryMode.factory"))
val factory = clazz.getConstructor(classOf[SparkConf], classOf[Serializer])
.newInstance(conf, serializer)
.asInstanceOf[StandaloneRecoveryModeFactory]
(factory.createPersistenceEngine(), factory.createLeaderElectionAgent(this))
case _ =>
(new BlackHolePersistenceEngine(), new MonarchyLeaderAgent(this))
}
persistenceEngine = persistenceEngine_
leaderElectionAgent = leaderElectionAgent_
}我们在查看一下receive 这些只是受到消息,然而并没有恢复
override def receive: PartialFunction[Any, Unit] = {
case ElectedLeader => // Leader选举,用在SparkHA中
val (storedApps, storedDrivers, storedWorkers) = persistenceEngine.readPersistedData(rpcEnv)
state = if (storedApps.isEmpty && storedDrivers.isEmpty && storedWorkers.isEmpty) {
RecoveryState.ALIVE
} else {
RecoveryState.RECOVERING
}
logInfo("I have been elected leader! New state: " + state)
if (state == RecoveryState.RECOVERING) {
beginRecovery(storedApps, storedDrivers, storedWorkers)
recoveryCompletionTask = forwardMessageThread.schedule(new Runnable {
override def run(): Unit = Utils.tryLogNonFatalError {
self.send(CompleteRecovery)
}
}, WORKER_TIMEOUT_MS, TimeUnit.MILLISECONDS)
}
case CompleteRecovery => completeRecovery() //成功地恢复
case RevokedLeadership => //
logError("Leadership has been revoked -- master shutting down.")
System.exit(0)
//注册应用
case RegisterApplication(description, driver) =>
// TODO Prevent repeated registrations from some driver
if (state == RecoveryState.STANDBY) {
// ignore, don't send response
} else {
logInfo("Registering app " + description.name)
val app = createApplication(description, driver)
registerApplication(app)
logInfo("Registered app " + description.name + " with ID " + app.id)
persistenceEngine.addApplication(app)
driver.send(RegisteredApplication(app.id, self))
// 启动分配Executor
schedule()
}
// 检测 Executor
case ExecutorStateChanged(appId, execId, state, message, exitStatus) =>
val execOption = idToApp.get(appId).flatMap(app => app.executors.get(execId))
execOption match {
case Some(exec) =>
val appInfo = idToApp(appId)
val oldState = exec.state
exec.state = state
if (state == ExecutorState.RUNNING) {
assert(oldState == ExecutorState.LAUNCHING,
s"executor $execId state transfer from $oldState to RUNNING is illegal")
appInfo.resetRetryCount()
}
exec.application.driver.send(ExecutorUpdated(execId, state, message, exitStatus, false))
if (ExecutorState.isFinished(state)) {
// Remove this executor from the worker and app
logInfo(s"Removing executor ${exec.fullId} because it is $state")
// If an application has already finished, preserve its
// state to display its information properly on the UI
if (!appInfo.isFinished) {
appInfo.removeExecutor(exec)
}
exec.worker.removeExecutor(exec)
val normalExit = exitStatus == Some(0)
// Only retry certain number of times so we don't go into an infinite loop.
// Important note: this code path is not exercised by tests, so be very careful when
// changing this `if` condition.
if (!normalExit
&& appInfo.incrementRetryCount() >= MAX_EXECUTOR_RETRIES
&& MAX_EXECUTOR_RETRIES >= 0) { // < 0 disables this application-killing path
val execs = appInfo.executors.values
if (!execs.exists(_.state == ExecutorState.RUNNING)) {
logError(s"Application ${appInfo.desc.name} with ID ${appInfo.id} failed " +
s"${appInfo.retryCount} times; removing it")
removeApplication(appInfo, ApplicationState.FAILED)
}
}
}
schedule()
case None =>
logWarning(s"Got status update for unknown executor $appId/$execId")
}
case DriverStateChanged(driverId, state, exception) =>
state match {
case DriverState.ERROR | DriverState.FINISHED | DriverState.KILLED | DriverState.FAILED =>
removeDriver(driverId, state, exception)
case _ =>
throw new Exception(s"Received unexpected state update for driver $driverId: $state")
}
//心跳机制
case Heartbeat(workerId, worker) =>
idToWorker.get(workerId) match {
case Some(workerInfo) =>
workerInfo.lastHeartbeat = System.currentTimeMillis()
case None =>
if (workers.map(_.id).contains(workerId)) {
logWarning(s"Got heartbeat from unregistered worker $workerId." +
" Asking it to re-register.")
worker.send(ReconnectWorker(masterUrl))
} else {
logWarning(s"Got heartbeat from unregistered worker $workerId." +
" This worker was never registered, so ignoring the heartbeat.")
}
}
case MasterChangeAcknowledged(appId) =>
idToApp.get(appId) match {
case Some(app) =>
logInfo("Application has been re-registered: " + appId)
app.state = ApplicationState.WAITING
case None =>
logWarning("Master change ack from unknown app: " + appId)
}
if (canCompleteRecovery) { completeRecovery() }
//反馈Worker的运行状态
case WorkerSchedulerStateResponse(workerId, executors, driverIds) =>
idToWorker.get(workerId) match {
case Some(worker) =>
logInfo("Worker has been re-registered: " + workerId)
worker.state = WorkerState.ALIVE
val validExecutors = executors.filter(exec => idToApp.get(exec.appId).isDefined)
for (exec <- validExecutors) {
val app = idToApp.get(exec.appId).get
val execInfo = app.addExecutor(worker, exec.cores, Some(exec.execId))
worker.addExecutor(execInfo)
execInfo.copyState(exec)
}
for (driverId <- driverIds) {
drivers.find(_.id == driverId).foreach { driver =>
driver.worker = Some(worker)
driver.state = DriverState.RUNNING
worker.drivers(driverId) = driver
}
}
case None =>
logWarning("Scheduler state from unknown worker: " + workerId)
}
if (canCompleteRecovery) { completeRecovery() }
case WorkerLatestState(workerId, executors, driverIds) =>
idToWorker.get(workerId) match {
case Some(worker) =>
for (exec <- executors) {
val executorMatches = worker.executors.exists {
case (_, e) => e.application.id == exec.appId && e.id == exec.execId
}
if (!executorMatches) {
// master doesn't recognize this executor. So just tell worker to kill it.
worker.endpoint.send(KillExecutor(masterUrl, exec.appId, exec.execId))
}
}
for (driverId <- driverIds) {
val driverMatches = worker.drivers.exists { case (id, _) => id == driverId }
if (!driverMatches) {
// master doesn't recognize this driver. So just tell worker to kill it.
worker.endpoint.send(KillDriver(driverId))
}
}
case None =>
logWarning("Worker state from unknown worker: " + workerId)
}
case UnregisterApplication(applicationId) =>
logInfo(s"Received unregister request from application $applicationId")
idToApp.get(applicationId).foreach(finishApplication)
//给积极扫那个一个消息,检测自己是否挂掉
case CheckForWorkerTimeOut =>
timeOutDeadWorkers()
}
注意:上述都是没有回复的,我们需要查看一下receiveAndReply
case RequestSubmitDriver(description) =>
if (state != RecoveryState.ALIVE) {
val msg = s"${Utils.BACKUP_STANDALONE_MASTER_PREFIX}: $state. " +
"Can only accept driver submissions in ALIVE state."
context.reply(SubmitDriverResponse(self, false, None, msg))
} else {
logInfo("Driver submitted " + description.command.mainClass)
val driver = createDriver(description)
persistenceEngine.addDriver(driver)
waitingDrivers += driver
drivers.add(driver)
schedule()
// TODO: It might be good to instead have the submission client poll the master to determine
// the current status of the driver. For now it's simply "fire and forget".
context.reply(SubmitDriverResponse(self, true, Some(driver.id),
s"Driver successfully submitted as ${driver.id}"))
}
case RequestKillDriver(driverId) =>
if (state != RecoveryState.ALIVE) {
val msg = s"${Utils.BACKUP_STANDALONE_MASTER_PREFIX}: $state. " +
s"Can only kill drivers in ALIVE state."
context.reply(KillDriverResponse(self, driverId, success = false, msg))
} else {
logInfo("Asked to kill driver " + driverId)
val driver = drivers.find(_.id == driverId)
driver match {
case Some(d) =>
if (waitingDrivers.contains(d)) {
waitingDrivers -= d
self.send(DriverStateChanged(driverId, DriverState.KILLED, None))
} else {
// We just notify the worker to kill the driver here. The final bookkeeping occurs
// on the return path when the worker submits a state change back to the master
// to notify it that the driver was successfully killed.
d.worker.foreach { w =>
w.endpoint.send(KillDriver(driverId))
}
}
// TODO: It would be nice for this to be a synchronous response
val msg = s"Kill request for $driverId submitted"
logInfo(msg)
//回复KillDriverResponse
context.reply(KillDriverResponse(self, driverId, success = true, msg))
case None =>
val msg = s"Driver $driverId has already finished or does not exist"
logWarning(msg)
context.reply(KillDriverResponse(self, driverId, success = false, msg))
}
}
case RequestDriverStatus(driverId) =>
if (state != RecoveryState.ALIVE) {
val msg = s"${Utils.BACKUP_STANDALONE_MASTER_PREFIX}: $state. " +
"Can only request driver status in ALIVE state."
context.reply(
DriverStatusResponse(found = false, None, None, None, Some(new Exception(msg))))
} else {
(drivers ++ completedDrivers).find(_.id == driverId) match {
case Some(driver) =>
context.reply(DriverStatusResponse(found = true, Some(driver.state),
driver.worker.map(_.id), driver.worker.map(_.hostPort), driver.exception))
case None =>
context.reply(DriverStatusResponse(found = false, None, None, None, None))
}
}
case RequestMasterState =>
context.reply(MasterStateResponse(
address.host, address.port, restServerBoundPort,
workers.toArray, apps.toArray, completedApps.toArray,
drivers.toArray, completedDrivers.toArray, state))
case BoundPortsRequest =>
context.reply(BoundPortsResponse(address.port, webUi.boundPort, restServerBoundPort))
case RequestExecutors(appId, requestedTotal) =>
context.reply(handleRequestExecutors(appId, requestedTotal))
case KillExecutors(appId, executorIds) =>
val formattedExecutorIds = formatExecutorIds(executorIds)
context.reply(handleKillExecutors(appId, formattedExecutorIds))
}Worker
private[deploy] class Worker(
override val rpcEnv: RpcEnv,
webUiPort: Int,
cores: Int,
memory: Int,
masterRpcAddresses: Array[RpcAddress],
endpointName: String,
workDirPath: String = null,
val conf: SparkConf,
val securityMgr: SecurityManager)
extends ThreadSafeRpcEndpoint with Logging { //Worker继承了ThreadSafeRpcEndpoint,它也是一个通信端点我们查看一下Worker的main方法
def main(argStrings: Array[String]) {
Utils.initDaemon(log)
val conf = new SparkConf //创建SparkConf
val args = new WorkerArguments(argStrings, conf) //解析参数
val rpcEnv = startRpcEnvAndEndpoint(args.host, args.port, args.webUiPort, args.cores, //创建rpcEnv
args.memory, args.masters, args.workDir, conf = conf)
rpcEnv.awaitTermination()
}我们在查看一下调用的startRpcEnvAndEndpoint
def startRpcEnvAndEndpoint(
host: String,
port: Int,
webUiPort: Int,
cores: Int,
memory: Int,
masterUrls: Array[String],
workDir: String,
workerNumber: Option[Int] = None,
conf: SparkConf = new SparkConf): RpcEnv = {
// The LocalSparkCluster runs multiple local sparkWorkerX RPC Environments
val systemName = SYSTEM_NAME + workerNumber.map(_.toString).getOrElse("")
val securityMgr = new SecurityManager(conf)
val rpcEnv = RpcEnv.create(systemName, host, port, conf, securityMgr)
val masterAddresses = masterUrls.map(RpcAddress.fromSparkURL(_))
rpcEnv.setupEndpoint(ENDPOINT_NAME, new Worker(rpcEnv, webUiPort, cores, memory, //生成Worker会有很多属性.
masterAddresses, ENDPOINT_NAME, workDir, conf, securityMgr))
rpcEnv
}我们在查看一下onStart方法
override def onStart() {
assert(!registered)
logInfo("Starting Spark worker %s:%d with %d cores, %s RAM".format(
host, port, cores, Utils.megabytesToString(memory)))
logInfo(s"Running Spark version ${org.apache.spark.SPARK_VERSION}")
logInfo("Spark home: " + sparkHome) //打印日志
createWorkDir()
shuffleService.startIfEnabled()
webUi = new WorkerWebUI(this, workDir, webUiPort) //创建WorkerWebUI
webUi.bind()
workerWebUiUrl = s"http://$publicAddress:${webUi.boundPort}" //8081端
registerWithMaster() //注册点击查看
//测量系统启动
metricsSystem.registerSource(workerSource)
metricsSystem.start()
// Attach the worker metrics servlet handler to the web ui after the metrics system is started.
metricsSystem.getServletHandlers.foreach(webUi.attachHandler)
}我们查看一下registerWithMaster
private def registerWithMaster() {
// onDisconnected may be triggered multiple times, so don't attempt registration
// if there are outstanding registration attempts scheduled.
registrationRetryTimer match { //重试机制
case None =>
registered = false //未注册的
registerMasterFutures = tryRegisterAllMasters()
connectionAttemptCount = 0
registrationRetryTimer = Some(forwordMessageScheduler.scheduleAtFixedRate( //
new Runnable {
override def run(): Unit = Utils.tryLogNonFatalError {
Option(self).foreach(_.send(ReregisterWithMaster)) //发送
}
},
INITIAL_REGISTRATION_RETRY_INTERVAL_SECONDS,
INITIAL_REGISTRATION_RETRY_INTERVAL_SECONDS,
TimeUnit.SECONDS))
case Some(_) =>
logInfo("Not spawning another attempt to register with the master, since there is an" +
" attempt scheduled already.")
}
}点击ReregisterWithMaster
case ReregisterWithMaster =>
reregisterWithMaster() // 调用方法private def reregisterWithMaster(): Unit = {
Utils.tryOrExit {
connectionAttemptCount += 1
if (registered) {
cancelLastRegistrationRetry()
} else if (connectionAttemptCount <= TOTAL_REGISTRATION_RETRIES) {
logInfo(s"Retrying connection to master (attempt # $connectionAttemptCount)")
//
master match {
case Some(masterRef) => //获得masterRef
// registered == false && master != None means we lost the connection to master, so
// masterRef cannot be used and we need to recreate it again. Note: we must not set
// master to None due to the above comments.
if (registerMasterFutures != null) {
registerMasterFutures.foreach(_.cancel(true))
}
val masterAddress = masterRef.address
registerMasterFutures = Array(registerMasterThreadPool.submit(new Runnable {
override def run(): Unit = {
try {
logInfo("Connecting to master " + masterAddress + "...")
val masterEndpoint = rpcEnv.setupEndpointRef(masterAddress, Master.ENDPOINT_NAME)
registerWithMaster(masterEndpoint) //重试机制
} catch {
case ie: InterruptedException => // Cancelled
case NonFatal(e) => logWarning(s"Failed to connect to master $masterAddress", e)
}
}
}))
case None =>
if (registerMasterFutures != null) {
registerMasterFutures.foreach(_.cancel(true))
}
// We are retrying the initial registration
registerMasterFutures = tryRegisterAllMasters()
}
// We have exceeded the initial registration retry threshold
// All retries from now on should use a higher interval
if (connectionAttemptCount == INITIAL_REGISTRATION_RETRIES) {
registrationRetryTimer.foreach(_.cancel(true))
registrationRetryTimer = Some(
forwordMessageScheduler.scheduleAtFixedRate(new Runnable {
override def run(): Unit = Utils.tryLogNonFatalError {
self.send(ReregisterWithMaster) //重试机制
}
}, PROLONGED_REGISTRATION_RETRY_INTERVAL_SECONDS,
PROLONGED_REGISTRATION_RETRY_INTERVAL_SECONDS,
TimeUnit.SECONDS))
}
} else {
logError("All masters are unresponsive! Giving up.")
System.exit(1)
}
}
}Master
在Master中我们查看一下receiveAndReply
override def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = {
case RegisterWorker(
id, workerHost, workerPort, workerRef, cores, memory, workerWebUiUrl) =>
logInfo("Registering worker %s:%d with %d cores, %s RAM".format( //正在注册
workerHost, workerPort, cores, Utils.megabytesToString(memory)))
if (state == RecoveryState.STANDBY) { //如果state不是主节点
context.reply(MasterInStandby) //回复MasterInStandby
} else if (idToWorker.contains(id)) {
context.reply(RegisterWorkerFailed("Duplicate worker ID"))
} else {
val worker = new WorkerInfo(id, workerHost, workerPort, cores, memory, //否则new 一个WorkerInfo 将接收到的消息传入WorkerInfo 注册信息包含有主机名端口 CPU数量 内存数量
workerRef, workerWebUiUrl)
if (registerWorker(worker)) { //点击查看registerWorker
persistenceEngine.addWorker(worker)
context.reply(RegisteredWorker(self, masterWebUiUrl)) //成功放入
schedule()
} else { //放入失败
val workerAddress = worker.endpoint.address
logWarning("Worker registration failed. Attempted to re-register worker at same " +
"address: " + workerAddress)
context.reply(RegisterWorkerFailed("Attempted to re-register worker at same address: "
+ workerAddress))
}
}点击查看registerWorker
private def registerWorker(worker: WorkerInfo): Boolean = {
// There may be one or more refs to dead workers on this same node (w/ different ID's),
// remove them.
workers.filter { w =>
(w.host == worker.host && w.port == worker.port) && (w.state == WorkerState.DEAD)
}.foreach { w =>
workers -= w
}
val workerAddress = worker.endpoint.address
if (addressToWorker.contains(workerAddress)) {
val oldWorker = addressToWorker(workerAddress)
if (oldWorker.state == WorkerState.UNKNOWN) {
// A worker registering from UNKNOWN implies that the worker was restarted during recovery.
// The old worker must thus be dead, so we will remove it and accept the new worker.
removeWorker(oldWorker)
} else {
logInfo("Attempted to re-register worker at same address: " + workerAddress)
return false
}
}
workers += worker //这是一个HashSet[WorkerInfo] 维护的是Worker的注册信息
idToWorker(worker.id) = worker
addressToWorker(workerAddress) = worker
if (reverseProxy) {
webUi.addProxyTargets(worker.id, worker.webUiAddress)
}
true
}在Master上如果我们成功了则调用context.reply(RegisteredWorker(self, masterWebUiUrl)) 告知Worker注册成功
private def handleRegisterResponse(msg: RegisterWorkerResponse): Unit = synchronized {
msg match {
case RegisteredWorker(masterRef, masterWebUiUrl) => //注册成功打印日志
logInfo("Successfully registered with master " + masterRef.address.toSparkURL)
registered = true //改变registered的状态
changeMaster(masterRef, masterWebUiUrl)
forwordMessageScheduler.scheduleAtFixedRate(new Runnable {
override def run(): Unit = Utils.tryLogNonFatalError {
self.send(SendHeartbeat) //发送心跳
}
}, 0, HEARTBEAT_MILLIS, TimeUnit.MILLISECONDS)
if (CLEANUP_ENABLED) {
logInfo(
s"Worker cleanup enabled; old application directories will be deleted in: $workDir")
forwordMessageScheduler.scheduleAtFixedRate(new Runnable {
override def run(): Unit = Utils.tryLogNonFatalError {
self.send(WorkDirCleanup)
}
}, CLEANUP_INTERVAL_MILLIS, CLEANUP_INTERVAL_MILLIS, TimeUnit.MILLISECONDS)
}
val execs = executors.values.map { e =>
new ExecutorDescription(e.appId, e.execId, e.cores, e.state)
}
masterRef.send(WorkerLatestState(workerId, execs.toList, drivers.keys.toSeq))
case RegisterWorkerFailed(message) =>
if (!registered) {
logError("Worker registration failed: " + message)
System.exit(1)
}
case MasterInStandby =>
// Ignore. Master not yet ready.
}
}
override def receive: PartialFunction[Any, Unit] = synchronized {
case SendHeartbeat => //发送的消息为workerId 和 它自身
if (connected) { sendToMaster(Heartbeat(workerId, self)) } //sendToMaster给Master发送心跳
...
}点击进入sendToMaster
private def sendToMaster(message: Any): Unit = {
master match {
case Some(masterRef) => masterRef.send(message) //把消息发送给了Master
case None =>
logWarning(
s"Dropping $message because the connection to master has not yet been established")
}
}Master中收到发送的消息
case Heartbeat(workerId, worker) =>
idToWorker.get(workerId) match { //Worker中是否有
case Some(workerInfo) => //如果有
workerInfo.lastHeartbeat = System.currentTimeMillis() //更新lastHeartbeat的时间
case None => //如果没有发现
if (workers.map(_.id).contains(workerId)) {
logWarning(s"Got heartbeat from unregistered worker $workerId." +
" Asking it to re-register.")
worker.send(ReconnectWorker(masterUrl))//需要重新链接masterUrl
} else {
logWarning(s"Got heartbeat from unregistered worker $workerId." +
" This worker was never registered, so ignoring the heartbeat.")
}
}我们回过头看一下Master中的Onstart调用的self.send(CheckForWorkerTimeOut)
case CheckForWorkerTimeOut =>
timeOutDeadWorkers() //调用private def timeOutDeadWorkers() {
// Copy the workers into an array so we don't modify the hashset while iterating through it
val currentTime = System.currentTimeMillis() //获取当前时间
val toRemove = workers.filter(_.lastHeartbeat < currentTime - WORKER_TIMEOUT_MS).toArray //
for (worker <- toRemove) { //如果被filter出来
if (worker.state != WorkerState.DEAD) {
logWarning("Removing %s because we got no heartbeat in %d seconds".format(
worker.id, WORKER_TIMEOUT_MS / 1000))
removeWorker(worker) //worker 被移除
} else {
if (worker.lastHeartbeat < currentTime - ((REAPER_ITERATIONS + 1) * WORKER_TIMEOUT_MS)) {
workers -= worker // we've seen this DEAD worker in the UI, etc. for long enough; cull it
}
}
}
}
