GraphX 是 Spark 图表和图形并行计算的新组件。GraphX 延伸 Spark RDD 通过引入新的图形的抽象:计算与连接到每个顶点和边缘性的向量。以支持图形计算,GraphX 公开了一组基本的操作符(例如 subgraph, joinVertices和 aggregateMessages)以及一个优化高阶API。此外,GraphX 包括的图形越来越多的收集 algorithms 和 builders ,以简化图形分析任务。
概念
顶点
RDD[(VertexId, VD)] 表示顶点。 VertexId 就是Long类型,表示顶点的ID【主键】。 VD表示类型参数,可以是任意类型, 表示的是该顶点的属性。
VertexRDD[VD] 继承了RDD[(VertexId, VD)], 他是顶点的另外一种表示方式, 在内部的计算上提供了很多的优化还有一些更高级的API。
边
RDD[Edge[VD]] 表示边, Edge中有三个东西: srcId表示 源顶点的ID, dstId表示的是目标顶点的ID, attr表示表的属性,属性的类型是VD类型,VD是一个类型参数,可以是任意类型。
EdgeRDD[ED] 继承了 RDD[Edge[ED]] ,他是边的另外一种表示方式,在内部的计算上提供您改了很多的优化还有一些更高级的API。
三元组
EdgeTriplet[VD, ED] extends Edge[ED] 他表示一个三元组, 比边多了两个顶点的属性

图
Graph[VD: ClassTag, ED: ClassTag] VD 是顶点的属性、 ED是边的属性
思路
1、直接创建 sparkConf -》 sparkContext
2、创建顶点的RDD RDD[(VertexId, VD)]
3、创建边的RDD RDD[Edge[ED]]
4、根据边和顶点创建 Graph
5、对图进行计算
6、关闭 SparkContext
import org.apache.spark.graphx.{Edge, Graph, VertexId}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object GraphxHelloWorld extends App {
//创建sparkConf
val sparkConf = new SparkConf().setAppName("graphx").setMaster("local[*]")
//创建SparkContext
val sc = new SparkContext(sparkConf)
//业务逻辑
val users: RDD[(VertexId, (String, String))] =
sc.parallelize(Array(
(3L, ("rxin", "student")),
(7L, ("jgonzal", "postdoc")),
(5L, ("franklin", "prof")),
(2L, ("istoica", "prof")))
)
val relationships: RDD[Edge[String]] =
sc.parallelize(Array(
Edge(3L, 7L, "collab"),
Edge(5L, 3L, "advisor"),
Edge(2L, 5L, "colleague"),
Edge(5L, 7L, "pi"))
)
val defaultUser = ("John Doe", "Missing")
val graph = Graph(users, relationships, defaultUser)
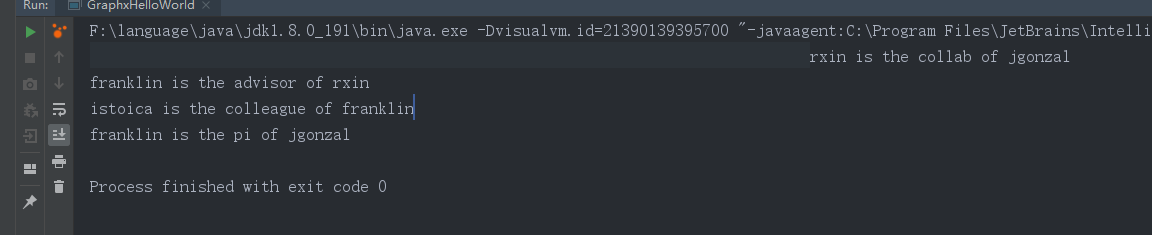
val facts: RDD[String] =
graph.triplets.map(triplet =>
triplet.srcAttr._1 + " is the " + triplet.attr + " of " + triplet.dstAttr._1)
facts.collect.foreach(println(_))
//关闭
sc.stop()
}
操作
创建操作
根据边和顶点的数据来创建。
def apply[VD: ClassTag, ED: ClassTag](
vertices: RDD[(VertexId, VD)],
edges: RDD[Edge[ED]],
defaultVertexAttr: VD = null.asInstanceOf[VD],
edgeStorageLevel: StorageLevel = StorageLevel.MEMORY_ONLY,
vertexStorageLevel: StorageLevel = StorageLevel.MEMORY_ONLY): Graph[VD, ED] 根据边直接创建, 所有顶点的属性都一样为 defaultValue
def fromEdges[VD: ClassTag, ED: ClassTag](
edges: RDD[Edge[ED]],
defaultValue: VD,
edgeStorageLevel: StorageLevel = StorageLevel.MEMORY_ONLY,
vertexStorageLevel: StorageLevel = StorageLevel.MEMORY_ONLY): Graph[VD, ED]根据裸边来进行创建,顶点的属性是 defaultValue ,边的属性为1
def fromEdgeTuples[VD: ClassTag](
rawEdges: RDD[(VertexId, VertexId)],
defaultValue: VD,
uniqueEdges: Option[PartitionStrategy] = None,
edgeStorageLevel: StorageLevel = StorageLevel.MEMORY_ONLY,
vertexStorageLevel: StorageLevel = StorageLevel.MEMORY_ONLY): Graph[VD, Int] 转换操作
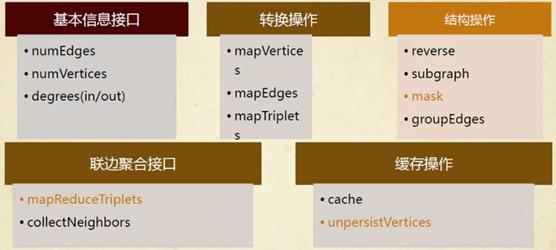
numEdges 返回边的个数
numVertices 顶点的个数
inDegrees: VertexRDD[Int] 返回顶点的入度, 返回类型为 RDD[(VertexId, Int)] Int就是入度的具体值
outDegrees: VertexRDD[Int] 返回顶点的出度, 返回类型为 RDD[(VertexId, Int)] Int就是出度的具体值
degrees: VertexRDD[Int] 返回顶点的入度和出度之和。 返回类型为 RDD[(VertexId, Int)] Int就是出度的具体值
结构操作
def reverse: Graph[VD, ED] 反转整个图 ,将边的方向调头
def subgraph( epred: EdgeTriplet[VD, ED] => Boolean = (x => true), vpred: (VertexId, VD) => Boolean = ((v, d) => true)) : Graph[VD, ED] 可以通过参数名来指定传参, 如果``subGraph中有的边没有顶点对应,那么会自动将该边去除 。 没有边的顶点不会自动被删除 def mask[VD2: ClassTag, ED2: ClassTag](other:Graph[VD2, ED2]): Graph[VD, ED] 将当前图和Other图做交集,返回一个新图,如果other中的属性和原图的属性不同,那么保留原图的属性 def groupEdges(merge: (ED, ED) => ED): Graph[VD, ED]` 合并两条边,通过函数合并边的属性。
聚合操作
def collectNeighbors(edgeDirection: EdgeDirection): VertexRDD[Array[(VertexId, VD)]] 收集邻居节点的数据,根据指定的方向。返回的数据为RDD[(VertexId, Array[(VertexId, VD)] )] 顶点的属性是 一个数组。数组中包含邻居节点的顶点
def collectNeighborIds(edgeDirection: EdgeDirection): VertexRDD[Array[VertexId]] 跟上一个相同,只不过只收集ID
def aggregateMessages[A: ClassTag]( sendMsg: EdgeContext[VD, ED, A] => Unit, mergeMsg: (A, A) => A, tripletFields: TripletFields = TripletFields.All) : VertexRDD[A] 每一个边都会通过sendMsg 发送一个消息, 每一个顶点都会通过mergeMsg 来处理所有他收到的消息。 TripletFields存在主要用于定制 EdgeContext 对象中的属性的值是否存在, 为了减少数据通信量。
关联操作
def joinVertices[U: ClassTag](table: RDD[(VertexId, U)])(mapFunc: (VertexId, VD, U) => VD) : Graph[VD, ED] 将相同顶点ID的数据进行加权, 将U这种类型的数据加入到 VD这种类型的数据上,但是不能修改VD的类型。
def outerJoinVertices[U: ClassTag, VD2: ClassTag](other: RDD[(VertexId, U)]) (mapFunc: (VertexId, VD, Option[U]) => VD2)(implicit eq: VD =:= VD2 = null) : Graph[VD2, ED] 和joinVertices类似。,只不是如果没有相对应的节点,那么join的值默认为None。
Pregel
节点: 有两种状态:
1、钝化态【类似于休眠,不做任何事】
2、激活态【干活】
2、节点能够处于激活态需要有条件:
(1)、节点收到消息
(2)、成功发送了任何一条消息
def pregel[A: ClassTag](
initialMsg: A, // 图初始化的时候,开始模型计算的时候,所有节点都会先收到一个消息。
maxIterations: Int = Int.MaxValue, //最大迭代次数
activeDirection: EdgeDirection = EdgeDirection.Either) //规定了发送消息的方向
(
vprog: (VertexId, VD, A) => VD, //节点调用该消息将聚合后的数据和本节点进行属性的合并。
sendMsg: EdgeTriplet[VD, ED] => Iterator[(VertexId, A)], //激活态的节点调用该方法发送消息
mergeMsg: (A, A) => A) //如果一个节点接收到多条消息,先用mergeMsg 来将多条消息聚合成为一条消息,如果节点只收到一条消息,则不调用该函数
: Graph[VD, ED]
案例
import org.apache.log4j.{Level, Logger}
import org.apache.spark.graphx.{Edge, _}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by wuyufei on 2017/9/22.
*
*/
object Practice extends App {
//屏蔽日志
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
//设定一个SparkConf
val conf = new SparkConf().setAppName("SimpleGraphX").setMaster("local[4]")
val sc = new SparkContext(conf)
//初始化顶点集合
val vertexArray = Array(
(1L, ("Alice", 28)),
(2L, ("Bob", 27)),
(3L, ("Charlie", 65)),
(4L, ("David", 42)),
(5L, ("Ed", 55)),
(6L, ("Fran", 50))
)
//创建顶点的RDD表示
val vertexRDD: RDD[(Long, (String, Int))] = sc.parallelize(vertexArray)
//初始化边的集合
val edgeArray = Array(
Edge(2L, 1L, 7),
Edge(2L, 4L, 2),
Edge(3L, 2L, 4),
Edge(3L, 6L, 3),
Edge(4L, 1L, 1),
Edge(2L, 5L, 2),
Edge(5L, 3L, 8),
Edge(5L, 6L, 3)
)
//创建边的RDD表示
val edgeRDD: RDD[Edge[Int]] = sc.parallelize(edgeArray)
//创建一个图
val graph: Graph[(String, Int), Int] = Graph(vertexRDD, edgeRDD)
//*************************** 图的属性 ****************************************
println("属性演示")
println("**********************************************************")
println("找出图中年龄大于30的顶点:")
graph.vertices.filter { case (id, (name, age)) => age > 30 }.collect.foreach {
case (id, (name, age)) => println(s"$name is $age")
}
println
//
println("找出图中属性大于5的边:")
graph.edges.filter(e => e.attr > 5).collect.foreach(e => println(s"${e.srcId} to ${e.dstId} att ${e.attr}"))
println
//triplets操作,((srcId, srcAttr), (dstId, dstAttr), attr)
println("列出边属性>5的tripltes:")
for (triplet <- graph.triplets.filter(t => t.attr > 5).collect) {
println(s"${triplet.srcAttr._1} likes ${triplet.dstAttr._1}")
}
println
//Degrees操作
println("找出图中最大的出度、入度、度数:")
def max(a: (VertexId, Int), b: (VertexId, Int)): (VertexId, Int) = {
if (a._2 > b._2) a else b
}
println("max of outDegrees:" + graph.outDegrees.reduce(max) + " max of inDegrees:" + graph.inDegrees.reduce(max) + " max of Degrees:" + graph.degrees.reduce(max))
println
//*************************** 转换操作 ****************************************
println("转换操作")
println("**********************************************************")
println("顶点的转换操作,顶点age + 10:")
graph.mapVertices { case (id, (name, age)) => (id, (name, age + 10)) }.vertices.collect.foreach(v => println(s"${v._2._1} is ${v._2._2}"))
println
println("边的转换操作,边的属性*2:")
graph.mapEdges(e => e.attr * 2).edges.collect.foreach(e => println(s"${e.srcId} to ${e.dstId} att ${e.attr}"))
println
println("三元组的转换操作,边的属性为端点的age相加:")
graph.mapTriplets(tri => tri.srcAttr._2 * tri.dstAttr._2).triplets.collect.foreach(e => println(s"${e.srcId} to ${e.dstId} att ${e.attr}"))
println
//*************************** 结构操作 ****************************************
println("结构操作")
println("**********************************************************")
println("顶点年纪>30的子图:")
val subGraph = graph.subgraph(vpred = (id, vd) => vd._2 >= 30)
println("子图所有顶点:")
subGraph.vertices.collect.foreach(v => println(s"${v._2._1} is ${v._2._2}"))
println
println("子图所有边:")
subGraph.edges.collect.foreach(e => println(s"${e.srcId} to ${e.dstId} att ${e.attr}"))
println
println("反转整个图:")
val reverseGraph = graph.reverse
println("子图所有顶点:")
reverseGraph.vertices.collect.foreach(v => println(s"${v._2._1} is ${v._2._2}"))
println
println("子图所有边:")
reverseGraph.edges.collect.foreach(e => println(s"${e.srcId} to ${e.dstId} att ${e.attr}"))
println
//*************************** 连接操作 ****************************************
println("连接操作")
println("**********************************************************")
val inDegrees: VertexRDD[Int] = graph.inDegrees
case class User(name: String, age: Int, inDeg: Int, outDeg: Int)
//创建一个新图,顶类点VD的数据型为User,并从graph做类型转换
val initialUserGraph: Graph[User, Int] = graph.mapVertices { case (id, (name, age)) => User(name, age, 0, 0) }
//initialUserGraph与inDegrees、outDegrees(RDD)进行连接,并修改initialUserGraph中inDeg值、outDeg值
val userGraph = initialUserGraph.outerJoinVertices(initialUserGraph.inDegrees) {
case (id, u, inDegOpt) => User(u.name, u.age, inDegOpt.getOrElse(0), u.outDeg)
}.outerJoinVertices(initialUserGraph.outDegrees) {
case (id, u, outDegOpt) => User(u.name, u.age, u.inDeg, outDegOpt.getOrElse(0))
}
println("连接图的属性:")
userGraph.vertices.collect.foreach(v => println(s"${v._2.name} inDeg: ${v._2.inDeg} outDeg: ${v._2.outDeg}"))
println
println("出度和入读相同的人员:")
userGraph.vertices.filter {
case (id, u) => u.inDeg == u.outDeg
}.collect.foreach {
case (id, property) => println(property.name)
}
println
//*************************** 聚合操作 ****************************************
println("聚合操作")
println("**********************************************************")
println("collectNeighbors:获取当前节点source节点的id和属性")
graph.collectNeighbors(EdgeDirection.In).collect.foreach(v => {
println(s"id: ${v._1}"); for (arr <- v._2) {
println(s" ${arr._1} (name: ${arr._2._1} age: ${arr._2._2})")
}
})
println("aggregateMessages版本:")
graph.aggregateMessages[Array[(VertexId, (String, Int))]](ctx => ctx.sendToDst(Array((ctx.srcId.toLong, (ctx.srcAttr._1, ctx.srcAttr._2)))), _ ++ _).collect.foreach(v => {
println(s"id: ${v._1}"); for (arr <- v._2) {
println(s" ${arr._1} (name: ${arr._2._1} age: ${arr._2._2})")
}
})
println("聚合操作")
println("**********************************************************")
println("找出年纪最大的追求者:")
val oldestFollower: VertexRDD[(String, Int)] = userGraph.aggregateMessages[(String, Int)](
// 将源顶点的属性发送给目标顶点,map过程
ctx => ctx.sendToDst((ctx.srcAttr.name, ctx.srcAttr.age)),
// 得到最大追求者,reduce过程
(a, b) => if (a._2 > b._2) a else b
)
userGraph.vertices.leftJoin(oldestFollower) { (id, user, optOldestFollower) =>
optOldestFollower match {
case None => s"${user.name} does not have any followers."
case Some((name, age)) => s"${name} is the oldest follower of ${user.name}."
}
}.collect.foreach { case (id, str) => println(str) }
println
//*************************** 实用操作 ****************************************
println("聚合操作")
println("**********************************************************")
val sourceId: VertexId = 5L // 定义源点
val initialGraph = graph.mapVertices((id, _) => if (id == sourceId) 0.0 else Double.PositiveInfinity)
initialGraph.triplets.collect().foreach(println)
println("找出5到各顶点的最短距离:")
val sssp = initialGraph.pregel(Double.PositiveInfinity, Int.MaxValue, EdgeDirection.Out)(
(id, dist, newDist) => {
println("||||" + id); math.min(dist, newDist)
},
triplet => { // 计算权重
println(">>>>" + triplet.srcId)
if (triplet.srcAttr + triplet.attr < triplet.dstAttr) {
//发送成功
Iterator((triplet.dstId, triplet.srcAttr + triplet.attr))
} else {
//发送不成功
Iterator.empty
}
},
(a, b) => math.min(a, b) // 当前节点所有输入的最短距离
)
sssp.triplets.collect().foreach(println)
println(sssp.vertices.collect.mkString("\n"))
sc.stop()
}
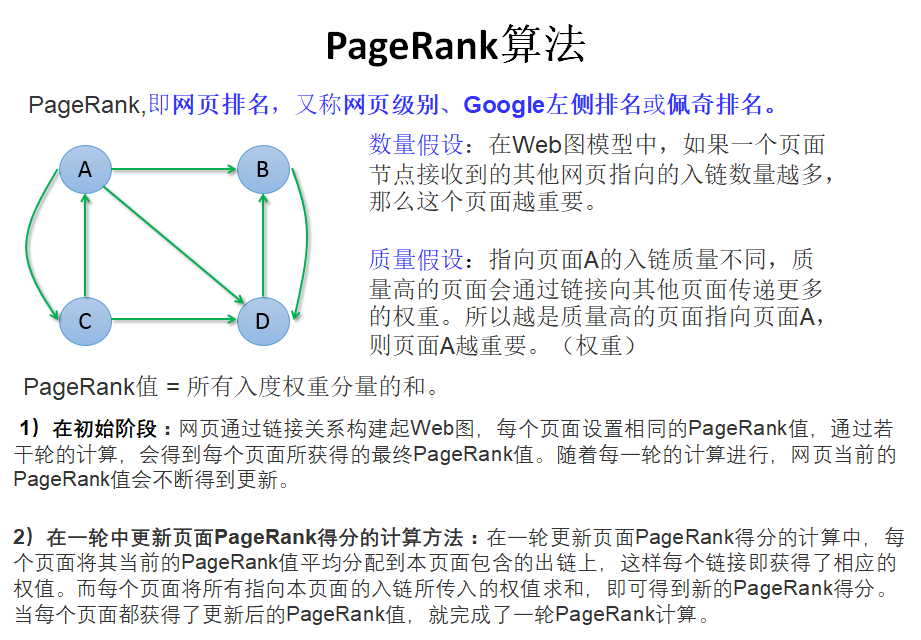
PageRank
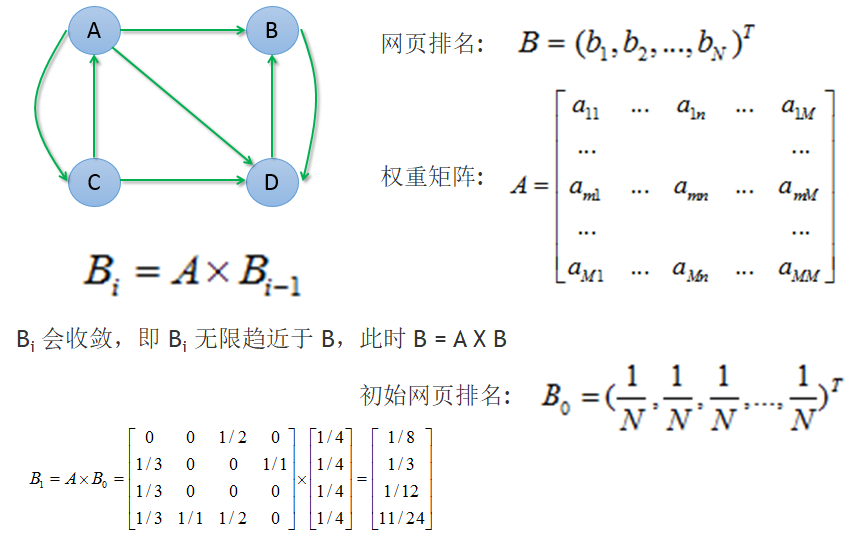

import org.apache.spark.graphx.{Graph, VertexId}
import org.apache.spark.{SparkConf, SparkContext, graphx}
/**
* Created by 清风笑丶 Cotter on 2019/6/8.
*/
object PageRank {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("Spark Graphx PageRank").setMaster("local[*]")
val sc = new SparkContext(sparkConf)
val erdd = sc.textFile("D:\\input\\graphx-wiki-edges.txt")
val edges = erdd.map(x => {
val para = x.split("\t"); graphx.Edge(para(0).trim.toLong, para(1).trim.toLong, 0)
})
val vrdd = sc.textFile("D:\\input\\graphx-wiki-vertices.txt")
val vertices = vrdd.map(x =>{val para =x.split("\t");(para(0).trim.toLong,para(1).trim)})
val graph =Graph(vertices,edges)
println("*****************************************************")
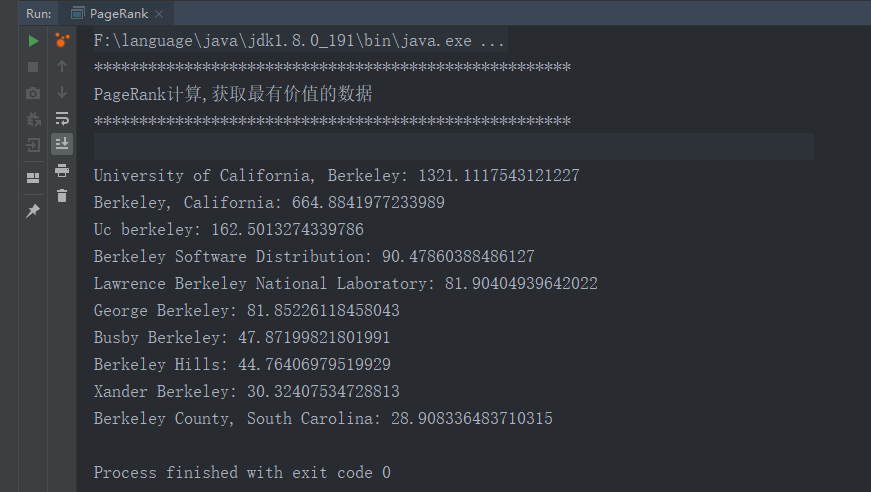
println("PageRank计算,获取最有价值的数据")
println("*****************************************************")
val prGraph = graph.pageRank(0.001).cache()
val titleAndPrGraph = graph.outerJoinVertices(prGraph.vertices) {
(v, title, rank) => (rank.getOrElse(0.0), title)
}
titleAndPrGraph.vertices.top(10) {
Ordering.by((entry: (VertexId, (Double, String))) => entry._2._1)
}.foreach(t => println(t._2._2 + ": " + t._2._1))
sc.stop()
}
}