<The rest of contents | 余下全文>
SparkSQL数据源
手动指定选项
Spark SQL的DataFrame接口支持多种数据源的操作。一个DataFrame可以进行RDD的方式的操作,也可以被注册为临时表。把DataFrame注册为临时表之后,就可以对该DataFrame执行SQL查询。
Spark SQL的默认数据源为Parquet格式。数据源为Parquet文件时,Spark SQL可以方便的执行所有的操作。修改配置项spark.sql.sources.default,可修改默认数据源格式。
val df = spark.read.load("/input/sparksql/users.parquet")
df.show()
df.select("name","favorite_color").write.save("/output/sparksql_out/namesAndFavColors.parquet")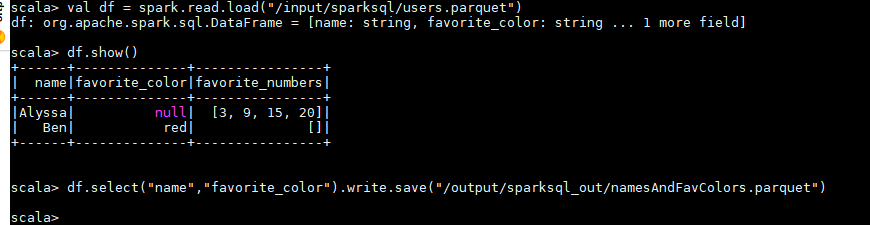

当数据源格式不是parquet格式文件时,需要手动指定数据源的格式。数据源格式需要指定全名(例如:org.apache.spark.sql.parquet),如果数据源格式为内置格式,则只需要指定简称定json, parquet, jdbc, orc, libsvm, csv, text来指定数据的格式。可以通过SparkSession提供的read.load方法用于通用加载数据,使用write和save保存数据。
val peopleDF = spark.read.format("json").load("/input/sparksql/people.json")
peopleDF.show()
peopleDF.write.format("parquet").save("/output/sparksql_out/namesAndAges.parquet")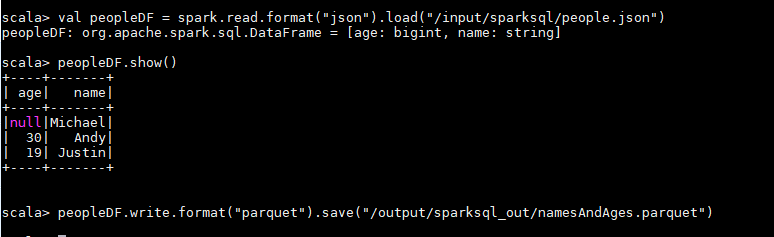

同时也可以直接运行SQL在文件上:
val sqlDF = spark.sql("SELECT * FROM parquet.`/output/sparksql_out/namesAndAges.parquet`")
sqlDF.show()
val sqlDF = spark.sql("SELECT * FROM parquet.`/output/sparksql_out/namesAndAges.parquet`")
sqlDF.show()
文件保存选项
SaveMode定义了对数据的处理模式,这些保存模式不使用任何锁定,f非原子操作。当使用Overwrite方式执行时,在输出新数据之前原数据就已经被删除。
| Scala/Java | Any Language | Meaning |
|---|---|---|
| SaveMode.ErrorIfExists(default) | “error”(default) | 如果文件存在,则报错 |
| SaveMode.Append | “append” | 追加 |
| SaveMode.Overwrite | “overwrite” | 覆写 |
| SaveMode.Ignore | “ignore” | 数据存在,则忽略 |
Parquet格式
Parquet是面向分析型业务的列式存储格式,由Twitter和Cloudera合作开发,2015年5月从Apache的孵化器里毕业成为Apache顶级项目。
Parquet文件是以二进制方式存储的,所以是不可以直接读取的,文件中包括该文件的数据和元数据,因此Parquet格式文件是自解析的。
通常情况下,在存储Parquet数据的时候会按照Block大小设置行组的大小,由于一般情况下每一个Mapper任务处理数据的最小单位是一个Block,这样可以把每一个行组由一个Mapper任务处理,增大任务执行并行度。

Parquet文件的内容,一个文件中可以存储多个行组,文件的首位都是该文件的Magic Code,用于校验它是否是一个Parquet文件,Footer length记录了文件元数据的大小,通过该值和文件长度可以计算出元数据的偏移量,文件的元数据中包括每一个行组的元数据信息和该文件存储数据的Schema信息。除了文件中每一个行组的元数据,每一页的开始都会存储该页的元数据,在Parquet中,有三种类型的页:数据页、字典页和索引页。数据页用于存储当前行组中该列的值,字典页存储该列值的编码字典,每一个列块中最多包含一个字典页,索引页用来存储当前行组下该列的索引,目前Parquet中还不支持索引页。
Parquet读写
Parquet格式经常在Hadoop生态圈中被使用,它也支持Spark SQL的全部数据类型。Spark SQL 提供了直接读取和存储 Parquet 格式文件的方法。
val peopleDF = spark.read.json("/input/sparksql/people.json")
peopleDF.collect
peopleDF.write.parquet("/output/sparksql_out/people.parquet")
val parquetFileDF = spark.read.parquet("/output/sparksql_out/people.parquet")
parquetFileDF.createOrReplaceTempView("parquetFile")
val namesDF = spark.sql("SELECT name FROM parquetFile WHERE age BETWEEN 13 AND 19")
namesDF.show()
namesDF.map(attributes => "Name: " + attributes(0)).show()
解析分区信息
对表进行分区是对数据进行优化的方式之一。在分区的表内,数据通过分区列将数据存储在不同的目录下。Parquet数据源现在能够自动发现并解析分区信息。例如,对人口数据进行分区存储,分区列为gender和country,使用下面的目录结构:
path
└── to
└── table
├── gender=male
│ ├── ...
│ │
│ ├── country=US
│ │ └── data.parquet
│ ├── country=CN
│ │ └── data.parquet
│ └── ...
└── gender=female
├── ...
│
├── country=US
│ └── data.parquet
├── country=CN
│ └── data.parquet
└── ...通过传递path/to/table给 SQLContext.read.parquet或SQLContext.read.load,Spark SQL将自动解析分区信息。返回的DataFrame的Schema如下:
root
|-- name: string (nullable = true)
|-- age: long (nullable = true)
|-- gender: string (nullable = true)
|-- country: string (nullable = true)数据的分区列的数据类型是自动解析的。当前,支持数值类型和字符串类型。自动解析分区类型的参数为:spark.sql.sources.partitionColumnTypeInference.enabled,默认值为true。如果想关闭该功能,直接将该参数设置为disabled。此时,分区列数据格式将被默认设置为string类型,不再进行类型解析。
Schema合并
Parquet也支持Schema evolution(Schema演变)。用户先定义一个简单的Schema,然后逐渐的向Schema中增加列描述。通过这种方式,用户可以获取多个有不同Schema但相互兼容的Parquet文件。现在Parquet数据源能自动检测这种情况,并合并这些文件的schemas。
因为Schema合并是一个高消耗的操作,在大多数情况下并不需要,所以Spark SQL从1.5.0开始默认关闭了该功能。可以通过下面两种方式开启该功能:
当数据源为Parquet文件时,将数据源选项mergeSchema设置为true
设置全局SQL选项spark.sql.parquet.mergeSchema为true
val df1 = sc.makeRDD(1 to 5).map(i => (i, i * 2)).toDF("single", "double")
df1.write.parquet("/data/test_table/key=1")
val df2 = sc.makeRDD(6 to 10).map(i => (i, i * 3)).toDF("single", "triple")
df2.write.parquet("/data/test_table/key=2")
val df3 = spark.read.option("mergeSchema", "true").parquet("/data/test_table")
df3.printSchema() .
.
Hive数据库
Apache Hive是Hadoop上的SQL引擎,Spark SQL编译时可以包含Hive支持,也可以不包含。包含Hive支持的Spark SQL可以支持Hive表访问、UDF(用户自定义函数)以及 Hive 查询语言(HiveQL/HQL)等。需要强调的 一点是,如果要在Spark SQL中包含Hive的库,并不需要事先安装Hive。一般来说,最好还是在编译Spark SQL时引入Hive支持,这样就可以使用这些特性了。如果你下载的是二进制版本的 Spark,它应该已经在编译时添加了 Hive 支持。
若要把Spark SQL连接到一个部署好的Hive上,你必须把hive-site.xml复制到 Spark的配置文件目录中($SPARK_HOME/conf)。即使没有部署好Hive,Spark SQL也可以运行。 需要注意的是,如果你没有部署好Hive,Spark SQL会在当前的工作目录中创建出自己的Hive 元数据仓库,叫作 metastore_db。此外,如果你尝试使用 HiveQL 中的 CREATE TABLE (并非 CREATE EXTERNAL TABLE)语句来创建表,这些表会被放在你默认的文件系统中的 /user/hive/warehouse 目录中(如果你的 classpath 中有配好的 hdfs-site.xml,默认的文件系统就是 HDFS,否则就是本地文件系统)。
内嵌Hive
内嵌的Hive可以直接使用,为了方便演示我们尽量使用指定master为lcoal
spark.sql("show tables").show()
spark.sql("CREATE TABLE IF NOT EXISTS test (key INT, value STRING)")
spark.sql("LOAD DATA LOCAL INPATH '/home/hadoop/data/kv1.txt' INTO TABLE test")
spark.sql("SELECT * FROM test").show()
spark.sql("SELECT COUNT(*) FROM test").show()
val sqlDF = sql("SELECT key, value FROM test WHERE key < 10 ORDER BY key")
import org.apache.spark.sql._
val stringsDS = sqlDF.map {
case Row(key: Int, value: String) => s"Key: $key, Value: $value"
}
stringsDS.show()
case class Record(key: Int, value: String)
val recordsDF = spark.createDataFrame((1 to 100).map(i => Record(i, s"val_$i")))
recordsDF.createOrReplaceTempView("records")
spark.sql("SELECT * FROM records r JOIN test s ON r.key = s.key").show() 注意:如果使用的是内部的Hive,在Spark2.0之后,spark.sql.warehouse.dir用于指定数据仓库的地址,如果使用HDFS作为路径,那么需要将core-site.xml和hdfs-site.xml 加入到Spark conf目录,否则只会创建master节点上的warehouse目录,查询时会出现文件找不到的问题,这是需要向使用HDFS,则需要将metastore删除,重启集群。
外部Hive
- 将Hive中的hive-site.xml拷贝或者软连接到Spark安装目录下的conf目录下。
cp /opt/module/hadoop/etc/hadoop/core-site.xml /opt/module/spark/conf/
cp /opt/module/hadoop/etc/hadoop/hdfs-site.xml /opt/module/spark/conf/
cd /opt/module/spark/conf
ln -s /opt/module/hive/conf/hive-site.xml- 打开spark shell,注意带上访问Hive元数据库的JDBC客户端
spark-shell --master spark://datanode1:7077 --jars mysql-connector-java-5.1.27-bin.jar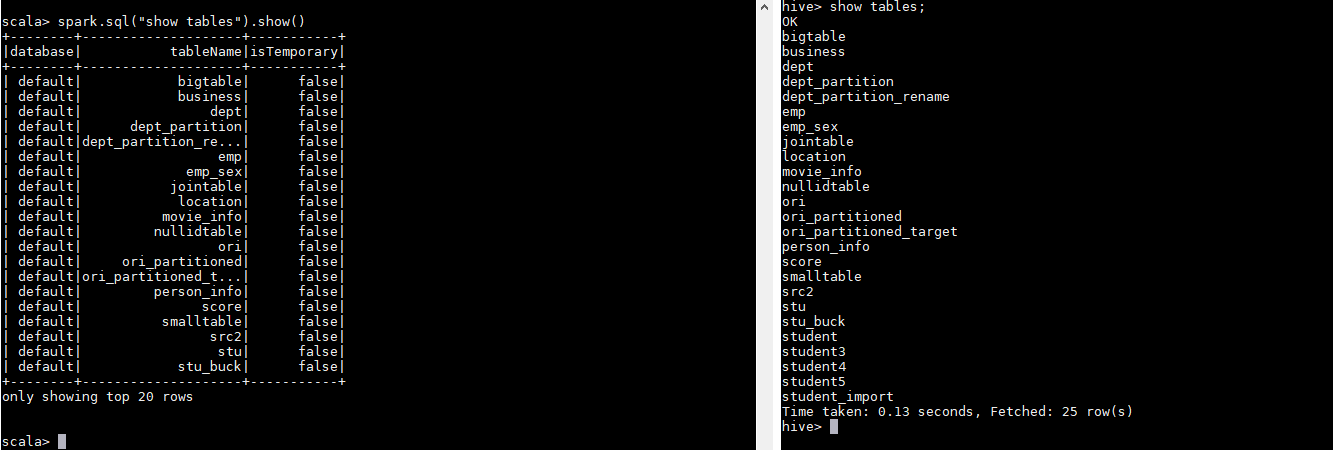
配置比较简单。
Windos开发
在本地windos上需要将core-site.xml, hive-site.xml,hdfs-site.xml的配置拷贝到resources中去

同时pom文件配置如下
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>spark</artifactId>
<groupId>com.hph</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>sparksql</artifactId>
<packaging>pom</packaging>
<modules>
<module>sparksql-helloword</module>
</modules>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.27</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
</dependencies>
</project>import org.apache.spark.sql.SparkSession
object LocalHive {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.enableHiveSupport()
.appName("Spark Hive")
.master("local[2]")
.getOrCreate()
spark.sql("show tables").limit(5).show()
}
}
JSON数据集
Spark SQL 能够自动推测 JSON数据集的结构,并将它加载为一个Dataset[Row]. 可以通过SparkSession.read.json()去加载一个 Dataset[String]或者一个JSON 文件.注意,这个JSON文件不是一个传统的JSON文件,每一行都得是一个JSON串。
{"name":"Michael"}
{"name":"Andy", "age":30}
{"name":"Justin", "age":19}//读取数据
val peopleDF = spark.read.json("/input/sparksql/people.json")
peopleDF.printSchema()
//创建临时表
peopleDF.createOrReplaceTempView("people")
//查询
val teenagerNamesDF = spark.sql("SELECT name FROM people WHERE age BETWEEN 13 AND 19")
teenagerNamesDF.show()
//隐式转换
import spark.implicits._
//创建Dataset
val otherPeopleDataset = spark.createDataset("""{"name":"Yin","address":{"city":"Columbus","state":"Ohio"}}""" :: Nil)
//官方网站案例 可以直接将读取otherPeopleDataset,然而spark2.1需要转化一下成为javaRDD
val otherPeopleRdd = otherPeopleDataset.toJavaRDD
val otherPeople = spark.read.json(otherPeopleRdd)
otherPeople.show()
JDBC
Spark SQL可以通过JDBC从关系型数据库中读取数据的方式创建DataFrame,通过对DataFrame一系列的计算后,还可以将数据再写回关系型数据库中。
import java.util.Properties
import org.apache.spark.sql.SparkSession
object Test {
def main(args: Array[String]): Unit = {
//创建SparkConf()并设置App名称
val spark = SparkSession.builder()
.appName("Spark SQL Strong Type UDF example")
.master("local[*]")
.getOrCreate()
//配置JDBC
//配置JDBC
val jdbcDF = spark.read.format("jdbc")
.option("url", "jdbc:mysql://datanode1:3306/rdd")
.option("dbtable", " rddtable")
.option("user", "root")
.option("password", "123456")
.load()
val connectionProperties = new Properties()
connectionProperties.put("user", "root")
connectionProperties.put("password", "123456")
val jdbcDF2 = spark.read.jdbc("jdbc:mysql://datanode1:3306/rdd", "rddtable", connectionProperties)
// 写入数据库
jdbcDF.write
.format("jdbc")
.option("url", "jdbc:mysql://datanode1:3306/rdd")
.option("dbtable", "Spark_2_Mysql")
.option("user", "root")
.option("password", "123456")
.save()
jdbcDF2.write.jdbc("jdbc:mysql://datanode1:3306/rdd", "Spark_2_Mysql_1", connectionProperties)
// 创建表时指定数据类别
jdbcDF.write.
option("createTableColumnTypes", "name CHAR(64), comments VARCHAR(1024)")
.jdbc("jdbc:mysql://datanode1:3306/rdd", "SparkRDD2Mysql_Type", connectionProperties)
}
}

原始数据

JDBC/ODBC服务器
Spark SQL也提供JDBC连接支持,这对于让商业智能(BI)工具连接到Spark集群上以 及在多用户间共享一个集群的场景都非常有用。JDBC 服务器作为一个独立的 Spark 驱动 器程序运行,可以在多用户之间共享。任意一个客户端都可以在内存中缓存数据表,对表 进行查询。集群的资源以及缓存数据都在所有用户之间共享。
Spark SQL的JDBC服务器与Hive中的HiveServer2相一致。由于使用了Thrift通信协议,它也被称为“Thrift server”。
服务器可以通过 Spark 目录中的 sbin/start-thriftserver.sh 启动。这个 脚本接受的参数选项大多与 spark-submit 相同。默认情况下,服务器会在 localhost:10000 上进行监听,我们可以通过环境变量(HIVE_SERVER2_THRIFT_PORT 和 HIVE_SERVER2_THRIFT_BIND_HOST)修改这些设置,也可以通过 Hive配置选项(hive. server2.thrift.port 和 hive.server2.thrift.bind.host)来修改。你也可以通过命令行参 数–hiveconf property=value来设置Hive选项。
./sbin/start-thriftserver.sh \
--hiveconf hive.server2.thrift.port=<listening-port> \
--hiveconf hive.server2.thrift.bind.host=<listening-host> \
--master <master-uri>
...
./bin/beeline
sbin/start-thriftserver.sh
./bin/beeline
!connect jdbc:hive2://datanode1:10000

Spark SQL CLI
Spark SQL CLI可以很方便的在本地运行Hive元数据服务以及从命令行执行查询任务。需要注意的是,Spark SQL CLI不能与Thrift JDBC服务交互。
在Spark目录下执行如下命令启动Spark SQL CLI:spark-sql 配置Hive需要替换 conf/ 下的 hive-site.xml 。


